Redis —— 一个视频平台的例子 | 自在学Redis —— 一个视频平台的例子
假设你正在负责维护一个大型在线视频平台,每天需要支撑数以千万计用户同时访问海量视频内容。平台不仅要秒级响应各种观看请求和个性化推荐,还必须保证在高峰流量下依然流畅可靠。
所以本节我们将基于在线视频平台的一个实际业务场景,来系统讲解 Redis 在高并发、大规模数据处理中的核心应用价值。从用户身份认证到智能内容推荐,每一个环节都深度体现了 Redis 对现代互联网应用架构的支撑能力。
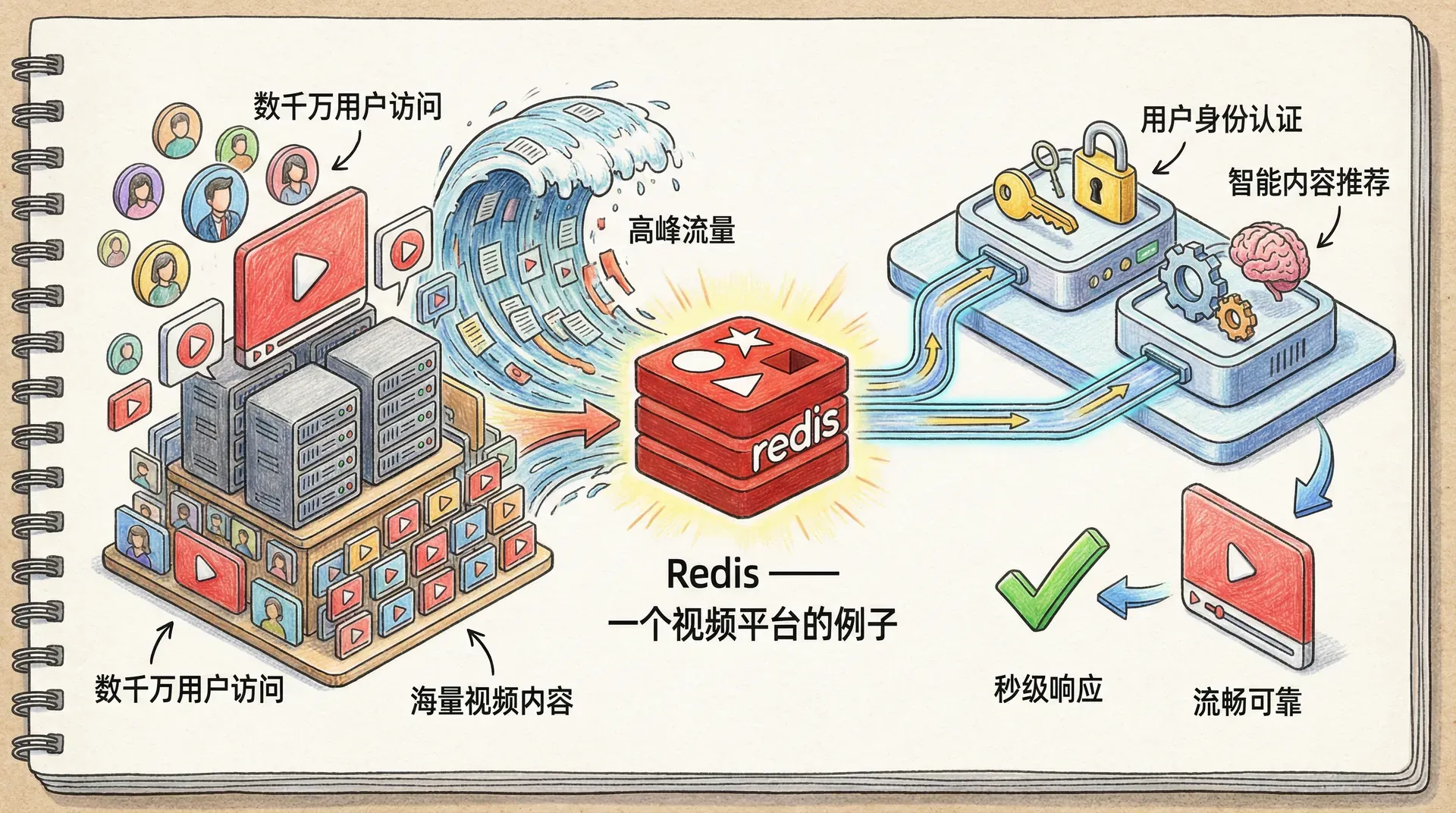
当用户点击播放按钮时,系统需要在毫秒级时间内完成一系列复杂操作:验证用户权限、获取视频元数据、生成播放链接、记录观看行为,同时还要为用户推荐相关内容。这个过程如果处理不当,很容易导致系统响应缓慢甚至崩溃。
在这个流程中,每一个步骤都可能成为性能瓶颈。特别是当平台同时服务数百万活跃用户时,传统的关系型数据库往往无法承受如此巨大的并发查询压力。
通过第一节课的学习我们已经了解到 Redis 的卓越性能特性。在视频平台中,我们可以将频繁访问但更新不那么频繁的数据存储在 Redis 中,从而大幅降低数据库的访问压力。
举个例子,假设我们的平台需要验证用户的观看权限。传统的做法是每次播放都查询数据库,但如果我们将用户的权限信息缓存在 Redis 中,就可以将验证时间从几百毫秒降低到几毫秒。
在设计 Redis 在网页应用中的应用时,我们始终要记住一个原则:将最常访问的数据放在最快的地方访问。
用户登录状态的管理
在视频平台中,用户登录状态的管理至关重要。当用户成功登录后,系统需要在后续的观看、评论、收藏等操作中能够准确识别用户身份。
传统的做法是将用户的登录信息存储在关系型数据库中,每次用户操作都需要查询数据库验证身份。但在视频平台这种高并发的场景下,这种做法会严重影响用户体验。
令牌式认证的优势
现在让我们来探讨一种更适合视频平台的解决方案:使用令牌来管理用户的登录状态。
想象一下,我们的视频平台为每位成功登录的用户生成一个独特的访问令牌。这个令牌就像是用户的数字身份卡,用户在观看视频、发表评论时都会携带这个令牌。服务器通过验证令牌的有效性,就可以确认用户的身份。
import redis
import json
import secrets
from datetime import datetime
# 视频平台的令牌生成和验证逻辑
def generate_access_token(user_id, redis_client):
# 生成一个安全的随机令牌
token = secrets.token_hex(32)
# 将令牌和用户ID关联存储,同时记录用户的基本信息
user_info = {
'userId': user_id,
'loginTime': datetime.now().timestamp() * 1000,
'platform': 'web'
}
redis_client.hset('access_tokens', token, json.dumps(user_info))
return token
def validate_access_token(token, redis_client):
# 从Redis中获取令牌对应的用户信息
user_info_str = redis_client.hget('access_tokens', token)
if not user_info_str:
return None
try:
return json.loads(user_info_str)
except json.JSONDecodeError:
return None
这种令牌方式的优势在于,令牌本身不包含敏感信息,即使被截获也无法直接利用。同时,由于令牌存储在 Redis 中,验证速度极快,能够支持视频播放时的实时身份验证。
与传统会话管理的对比
除了令牌式认证,还有一种传统的会话管理方式。这种方式会在服务器端维护会话状态,用户每次请求都携带会话ID。
举个例子,传统的会话管理可能会在 Cookie 中存储一个会话ID:sessionId=abc123def456,然后服务器端维护一个会话存储来记录用户的状态。
虽然传统会话管理看起来简单,但它有明显的缺点。首先,需要在服务器端维护会话状态,这会消耗额外的内存。其次,在分布式部署时,需要考虑会话共享的问题。最后,会话过期时间的管理也比较复杂。
相比之下,令牌式认证更加现代化和灵活。令牌可以在多个设备间共享,过期时间可以精确控制,而且天然支持分布式部署。
在使用令牌认证时,一定要确保令牌的生成算法足够安全,并且设置合理的过期时间,避免令牌被恶意利用。
仅仅验证用户身份还不够,在视频平台中,我们还需要详细记录用户的观看行为。这不仅可以用于个性化推荐,还可以帮助我们分析用户的观看偏好。
比如说,我们可以记录用户最近观看过的视频,以及观看的时间戳。这样系统就可以根据用户的观看历史来推荐相关内容。
def record_viewing_activity(token, video_id, redis_client, watch_duration=0):
timestamp = datetime.now().timestamp() * 1000
# 记录用户观看的视频历史
redis_client.zadd(f'user_watch_history:{token}', {video_id: timestamp})
# 记录视频的观看时长
if watch_duration > 0:
redis_client.hincrbyfloat(f'video_watch_time:{video_id}', token, watch_duration)
# 保持最近观看的50个视频
redis_client.zremrangebyrank(
通过这样的设计,我们不仅能够快速验证用户的登录状态,还能收集到丰富的用户行为数据。这些数据将成为个性化推荐系统的重要基础。
观看列表和收藏夹的实现
在视频平台中,观看列表和收藏夹是用户体验的核心功能。用户可以创建自己的播放列表、收藏喜欢的视频,还可以管理稍后观看的内容。这些功能的数据存储需求非常适合用 Redis 来实现。
为什么不把列表数据放在本地存储中?
传统的做法是将用户的观看列表和收藏夹数据存储在浏览器的本地存储中。这种方式的优点是简单直接,不需要服务器端处理。但它也有明显的局限性:
首先,本地存储的数据无法在多个设备间同步。如果用户在手机上收藏了一个视频,在电脑上就看不到。其次,本地存储容易丢失,如果用户清理浏览器数据或者更换设备,所有收藏都会消失。最后,本地存储无法支持社交功能,比如查看好友的收藏列表。
Redis Hash 存储观看列表
更好的解决方案是将用户的观看列表和收藏夹数据存储在 Redis 中。我们可以使用 Hash 数据结构来表示用户的各种列表,其中键是视频ID,值可以是添加时间或者播放进度等信息。
def add_to_watch_later(token, video_id, redis_client):
timestamp = datetime.now().timestamp() * 1000
# 使用有序集合存储,时间戳作为分数
redis_client.zadd(f'watch_later:{token}', {video_id: timestamp})
def add_to_favorites(token, video_id, redis_client):
timestamp = datetime.now().timestamp() * 1000
redis_client.zadd(f'favorites:{token}', {video_id: timestamp})
# 同时更新视频的收藏计数
redis_client.zincrby('video_favorite_counts'
这样的设计有几个显著优势:
第一,数据存储在服务器端,可以在多设备间同步。第二,容量几乎没有限制,用户可以创建大量的播放列表。第三,读写速度非常快,能够支持实时更新和查询。
列表数据的生命周期管理
观看列表和收藏夹数据不像登录令牌那样需要严格的时效性,但我们仍然需要定期清理无效数据。
我们可以结合用户活动跟踪,当检测到用户长时间没有登录时,清理他们的临时观看列表,但保留收藏夹数据。
def cleanup_user_lists(redis_client):
one_month_ago = datetime.now().timestamp() * 1000 - (30 * 24 * 60 * 60 * 1000) # 30天前
one_week_ago = datetime.now().timestamp() * 1000 - (7 * 24 * 60 * 60 * 1000) # 7天前
# 找到不活跃的用户令牌
inactive_tokens
通过这样的设计,我们的观看列表和收藏夹系统既能够快速响应用户的操作,又能够有效地管理数据生命周期,避免存储空间被无效数据占用。
合理地使用 Redis 的数据结构,可以让原本复杂的用户数据管理变得简单而高效。我们刚刚的观看列表和收藏夹的实现就是一个很好的例证。
页面内容的缓存策略
在视频平台中,页面生成是一个计算密集的过程。特别是视频详情页面,可能需要查询视频元数据、创作者信息、评论数据等多个数据源。如果每次访问都要重新生成页面,会严重影响观看体验。
视频内容与个性化内容的区别
并不是所有的页面内容都需要实时生成。有些内容相对稳定,比如视频的基本信息页面、频道介绍页面等。这些内容非常适合缓存。
但是,也有一些内容必须实时更新,比如用户的观看历史、个性化推荐内容、实时的观看人数等。对于这些动态内容,我们需要精细地控制缓存策略。
智能缓存中间件的设计
我们可以设计一个专门针对视频平台的缓存中间件,来智能决定哪些请求应该被缓存。
from urllib.parse import urlparse, parse_qs
def create_video_caching_middleware(cache_client):
def video_cache_middleware(request, response, next_handler):
# 检查这个请求是否可以被缓存
if not should_cache_video_request(request):
# 如果不能缓存,直接交给下一个处理器
return next_handler(request, response)
# 生成缓存键
cache_key = generate_video_cache_key(request)
try:
# 尝试从缓存中获取内容
cached_content = cache_client.get(cache_key)
if cached_content:
# 如果缓存存在,直接返回
这个中间件的设计理念是:
首先精确判断请求是否适合缓存。对于视频详情页、频道页等相对静态的内容,我们可以放心地缓存。对于用户的推荐内容、观看历史等个性化页面,我们绝对不能缓存。
然后尝试从缓存中获取内容。如果缓存命中,直接返回缓存的内容,节省了数据库查询和页面渲染的时间。如果缓存没有命中,就正常生成页面,同时将结果存储到缓存中。
缓存过期时间的精细控制
视频平台对缓存时间的要求更加精细。热门视频的详情页可以缓存较长时间,而新上传的视频可能需要更频繁的更新。
# 不同类型内容的缓存策略
CACHE_TIMES = {
# 热门视频详情页:较长缓存时间
'HOT_VIDEO_PAGE': 15 * 60, # 15分钟
# 新视频详情页:较短缓存时间
'NEW_VIDEO_PAGE': 2 * 60, # 2分钟
# 频道页面:中等缓存时间
'CHANNEL_PAGE': 10 * 60, # 10分钟
# 分类页面:较长缓存时间
'CATEGORY_PAGE': 20 * 60, # 20分钟
# 首页推荐:不缓存(实时性要求高)
视频平台的缓存策略需要在内容新鲜度和性能之间找到完美平衡。热门内容可以缓存更长时间,而新内容需要更频繁更新。
数据库行的智能缓存
虽然页面缓存能够显著提升性能,但有些场景下我们需要更加精细的控制。比如在视频平台中,视频的观看次数会实时变化,我们不能缓存整个页面,但又希望避免频繁查询数据库来获取视频的基本信息。
视频元数据的缓存策略
我们可以将经常查询的视频元数据缓存到 Redis 中。当应用需要这些数据时,首先检查 Redis 中是否有缓存,如果有就直接使用,否则再查询数据库并更新缓存。
import logging
class VideoMetadataCache:
def __init__(self, redis_client, database):
self.redis = redis_client
self.db = database
def get_video_metadata(self, video_id):
cache_key = f'video_meta:{video_id}'
try:
# 尝试从缓存获取
cached_data = self.redis.get(cache_key)
if cached_data:
这种缓存策略特别适用于以下场景:
- 视频的基本信息(如标题、描述、时长)变化不频繁
- 用户的个人信息更新不频繁
- 观看次数、点赞数等实时数据需要单独处理
- 我们希望在页面上显示最新的统计数据,但又不想每次都查询数据库
自动化缓存更新机制
对于一些数据,我们可能希望定期自动更新缓存,而不是等到缓存过期或者被手动更新。
比如,对于热门视频排行榜,我们可以每15分钟自动更新一次缓存:
import threading
import time
class VideoRankingCache:
def __init__(self, redis_client, database):
self.redis = redis_client
self.db = database
self.start_auto_update()
def get_top_viewed_videos(self, limit=20):
cache_key = 'ranking:top_viewed_videos'
cached = self.redis.get(cache_key)
if cached:
缓存调度系统的设计
为了让缓存更新机制更加灵活和可控,我们可以设计并实现一个专门用于管理视频缓存刷新时间的调度系统。通过这个系统,不同类型的视频(如热门视频和普通视频)可以被设置不同的缓存更新时间间隔。
例如,热门视频由于访问量高,可以每5分钟刷新一次缓存,而普通视频则可以每30分钟刷新一次。调度系统会将每个视频的缓存更新时间和刷新频率分别存储在Redis的不同zset键中,并提供接口来动态调整、停止或重新安排某个视频的缓存更新。
此外,还会有一个守护进程定时轮询这些调度信息,按需执行缓存刷新任务。这种做法不仅提高了缓存的时效性,也减少了不必要的资源浪费,实现了缓存生命周期的精细化管理。
class VideoCacheScheduler:
def __init__(self, redis_client):
self.redis = redis_client
def schedule_hot_video_cache(self, video_id):
schedule_key = 'video_cache:schedule'
delay_key = 'video_cache:delay'
# 热门视频每5分钟更新一次
self.redis.zadd(delay_key, {video_id: 300}) # 5分钟
self.redis.zadd(schedule_key, {video_id: datetime.now().timestamp() * 1000})
def schedule_normal_video_cache(self, video_id):
schedule_key
这个调度系统允许我们根据视频的热门程度来动态调整缓存更新频率,既保证了数据的时效性,又避免了不必要的数据库查询。
在设计视频元数据缓存时,需要特别注意将静态数据(如标题、描述)和动态数据(如观看次数、点赞数)分开处理,避免缓存不一致的问题。
基于观看行为的智能内容推荐
仅仅依靠固定的推荐算法有时候并不能满足用户的个性化需求。不同的视频在不同时期会有不同的受欢迎程度,我们应该根据实际的观看数据来优化推荐策略和缓存决策。
记录用户的观看行为
为了实现真正精细化的内容推荐,我们必须对用户的观看行为采集尽可能全面和细致的数据。具体来说,每当用户播放一个视频,我们后台会自动记录多维度的行为信息,包括但不限于:
- 用户观看的视频ID及时间戳,可用于恢复历史记录和判断活跃度;
- 每个视频被用户观看的次数,从而分析兴趣偏好;
- 本次观看的时长(秒),用于了解用户实际的消耗时间,判断“跳出”还是“沉浸”;
- 本次观看的完成比例(如80%或100%),辅助衡量视频本身的吸引力;
- 该用户所有观看历史中,最新的前100条数据,既做实时分析,也节省存储空间;
- 用户每天活跃的小时分布,洞察其作息习惯或者重要流量时段。
我们会将这些数据实时写入 Redis 的多种数据结构,为后续的个性化推荐、热度判定、流量预测等算法提供详实的数据基础。
def record_video_viewing(user_token, video_id, redis_client, watch_duration=0, completion_rate=0):
timestamp = datetime.now().timestamp() * 1000
# 记录用户观看的视频历史(按时间排序)
redis_client.zadd(f'user_watch_history:{user_token}', {video_id: timestamp})
# 记录用户的观看偏好(按频次排序)
redis_client.zincrby(f'user_preferences:{user_token}', 1, video_id)
# 记录观看时长(用于计算用户兴趣度)
if watch_duration
动态内容推荐算法
基于丰富的用户观看行为数据,我们可以构建一个多维度的智能内容推荐系统。推荐逻辑通常包括以下几个核心步骤:首先,系统会分析用户最近一段时间内实际观看过的视频,通过这些行为数据识别其兴趣重点。
其次,会抽取用户观看偏好中次数较多的视频ID,进一步推断其偏好领域。接下来,结合“协同过滤”原理,系统查找与该用户有相似观看习惯的其他用户,挖掘他们近期浏览但当前用户尚未观看的视频,从而扩展推荐范围。
此外,还可以根据已看视频的内容属性(如创作者ID、分类标签等),检索具有相似特征的未看视频,以丰富推荐的相关性。
最后,系统会结合用户每个候选视频的历史偏好权重、视频总体热度和新鲜度等因素,综合计算个性化推荐分数,从而优先呈现最适合的内容。
这种方式能够持续自适应地调整推荐结果,让用户不断发现感兴趣的新内容,也极大提升了平台的活跃度和用户满意度。
class VideoRecommendationEngine:
def __init__(self, redis_client):
self.redis = redis_client
def get_recommendations_for_user(self, user_token, limit=10):
# 获取用户最近观看的视频
recent_videos = self.redis.zrevrange(f'user_watch_history:{user_token}', 0, 19)
# 获取用户的观看偏好
preferred_videos = self.redis.zrevrange(f
小结
在本部分的内容中,我们并没有花太多篇幅去系统介绍 Redis 的各种特性,而是选择用日常开发中你极有可能会遇到的一些场景,逐步搭建了一个简单的视频平台案例。通过这些示例,你应该已经初步体会到 Redis 在用户登录、行为记录、列表管理以及页面缓存等方面的灵活性和优势。
实际上,正是这些看似普通但极具代表性的需求,让 Redis 的卓越性能和丰富数据结构发挥得淋漓尽致。接下来,我们会正式走进 Redis 的世界,细致地了解它的关键特性与最佳实践,让你在实战和深入理解之间找到最佳平衡点。
让我们继续出发,深入学习 Redis!
f
'user_watch_history:
{
token
}
'
,
0
,
-
51
)
# 更新用户的活跃时间戳
redis_client.zadd('active_users', {token: timestamp})
# 增加视频的总观看计数
redis_client.zincrby('video_view_counts', 1, video_id)
,
1
, video_id)
def create_playlist(token, playlist_name, video_ids, redis_client):
playlist_id = f'playlist:{token}:{int(datetime.now().timestamp() * 1000)}'
# 存储播放列表的基本信息
playlist_info = {
'name': playlist_name,
'creator': token,
'createdAt': datetime.now().timestamp() * 1000,
'isPublic': False
}
redis_client.hset(f'playlist_info:{playlist_id}', playlist_info)
# 存储播放列表中的视频
if video_ids and len(video_ids) > 0:
video_scores = {video_ids[i]: i for i in range(len(video_ids))}
redis_client.zadd(f'playlist_videos:{playlist_id}', video_scores)
return playlist_id
def get_watch_later_list(token, redis_client, limit=50):
return redis_client.zrevrange(f'watch_later:{token}', 0, limit - 1)
def get_favorites(token, redis_client, limit=100):
return redis_client.zrevrange(f'favorites:{token}', 0, limit - 1)
=
redis_client.zrangebyscore(
'active_users'
,
0
, one_month_ago)
for token in inactive_tokens:
# 清理临时观看列表(超过7天的)
old_watch_later = redis_client.zrangebyscore(f'watch_later:{token}', 0, one_week_ago)
if len(old_watch_later) > 0:
redis_client.zrem(f'watch_later:{token}', *old_watch_later)
# 可以选择保留收藏夹,或者设置过期时间
# redis_client.expire(f'favorites:{token}', 60 * 60 * 24 * 30) # 30天过期
# 从活跃用户列表中移除这些令牌
redis_client.zremrangebyscore('active_users', 0, one_month_ago)
response.headers[
'X-Video-Cache'
]
=
'HIT'
response.content = cached_content.decode('utf-8') if isinstance(cached_content, bytes) else cached_content
return response
# 缓存不存在,重写response来捕获输出
original_write = response.write
def capture_content(content):
# 根据内容类型设置不同的缓存时间
cache_time = get_cache_time_for_content(request.path)
cache_client.setex(cache_key, cache_time, content)
response.headers['X-Video-Cache'] = 'MISS'
return original_write(content)
response.write = capture_content
# 继续处理请求
return next_handler(request, response)
except Exception as error:
# 缓存出错时,继续正常处理
return next_handler(request, response)
return video_cache_middleware
def should_cache_video_request(request):
# 只缓存GET请求
if request.method != 'GET':
return False
# 缓存视频详情页
if request.path.startswith('/videos/') and len(request.path.split('/')) == 3:
return True
# 缓存频道页面
if request.path.startswith('/channels/'):
return True
# 缓存分类页面
if request.path.startswith('/categories/'):
return True
# 不缓存个性化内容
if '/recommendations' in request.path or '/history' in request.path:
return False
# 检查用户是否已登录(登录用户可能看到不同的内容)
if hasattr(request, 'user') and request.user:
return False
return False
def generate_video_cache_key(request):
# 为不同类型的页面生成合适的缓存键
base_key = f'video_page:{request.path}'
# 对于搜索页面,包含查询参数
if '/search' in request.path:
query_params = parse_qs(request.query_string.decode('utf-8'))
# 只包含影响结果的参数
relevant_params = ['q', 'category', 'sort']
filtered_params = {}
for param in relevant_params:
if param in query_params:
filtered_params[param] = query_params[param][0]
if filtered_params:
from urllib.parse import urlencode
return f"{base_key}?{urlencode(filtered_params)}"
return base_key
def get_cache_time_for_content(path):
# 视频详情页:缓存5分钟
if path.startswith('/videos/'):
return 5 * 60
# 频道页面:缓存10分钟
if path.startswith('/channels/'):
return 10 * 60
# 分类页面:缓存15分钟
if path.startswith('/categories/'):
return 15 * 60
# 默认缓存时间
return 5 * 60
'HOME_RECOMMENDATIONS': 0, # 不缓存
# 用户个性化内容:不缓存
'USER_PERSONALIZED': 0 # 不缓存
}
def get_dynamic_cache_time(video_id, redis_client):
# 获取视频的观看计数
view_count = redis_client.zscore('video_view_counts', video_id) or 0
if view_count > 1000000: # 超热门视频
return CACHE_TIMES['HOT_VIDEO_PAGE']
elif view_count > 100000: # 热门视频
return 10 * 60 # 10分钟
elif view_count > 10000: # 一般视频
return 5 * 60 # 5分钟
else: # 新视频
return CACHE_TIMES['NEW_VIDEO_PAGE']
logging.info(f'Cache hit for video: {video_id}')
return json.loads(cached_data)
# 缓存未命中,从数据库查询
logging.info(f'Cache miss for video: {video_id}')
video_data = self.db.get_video_by_id(video_id)
if video_data:
# 将查询结果缓存到Redis,设置过期时间为30分钟
# 注意:不包含实时变化的数据,如观看次数
cache_data = {
'id': video_data['id'],
'title': video_data['title'],
'description': video_data['description'],
'creatorId': video_data['creatorId'],
'creatorName': video_data['creatorName'],
'duration': video_data['duration'],
'uploadTime': video_data['uploadTime'],
'thumbnailUrl': video_data['thumbnailUrl'],
'category': video_data['category']
}
self.redis.setex(cache_key, 1800, json.dumps(cache_data))
return video_data
except Exception as error:
logging.error(f'Error in video metadata cache: {error}')
# 缓存出错时,降级到直接查询数据库
return self.db.get_video_by_id(video_id)
def update_video_metadata(self, video_id, update_data):
# 更新数据库
result = self.db.update_video(video_id, update_data)
if result:
# 成功更新数据库后,清除相关缓存
cache_key = f'video_meta:{video_id}'
self.redis.delete(cache_key)
# 如果更新了标题或描述,可能需要清除页面缓存
if 'title' in update_data or 'description' in update_data:
self.redis.delete(f'video_page:/videos/{video_id}')
return result
def invalidate_video_cache(self, video_id):
# 当视频信息发生重大变化时,清除缓存
cache_key = f'video_meta:{video_id}'
self.redis.delete(cache_key)
# 同时清除页面缓存
self.redis.delete(f'video_page:/videos/{video_id}')
class UserProfileCache:
def __init__(self, redis_client, database):
self.redis = redis_client
self.db = database
def get_user_profile(self, user_id):
cache_key = f'user_profile:{user_id}'
try:
cached_data = self.redis.get(cache_key)
if cached_data:
return json.loads(cached_data)
user_data = self.db.get_user_by_id(user_id)
if user_data:
# 缓存用户的基本信息,不包含敏感数据
cache_data = {
'id': user_data['id'],
'username': user_data['username'],
'displayName': user_data['displayName'],
'avatarUrl': user_data['avatarUrl'],
'bio': user_data['bio'],
'followerCount': user_data['followerCount'],
'videoCount': user_data['videoCount'],
'joinDate': user_data['joinDate']
}
self.redis.setex(cache_key, 600, json.dumps(cache_data)) # 10分钟缓存
return user_data
except Exception as error:
logging.error(f'Error in user profile cache: {error}')
return self.db.get_user_by_id(user_id)
def invalidate_user_cache(self, user_id):
cache_key = f'user_profile:{user_id}'
self.redis.delete(cache_key)
return
json.loads(cached)
return self.update_ranking_cache(limit)
def update_ranking_cache(self, limit=20):
cache_key = 'ranking:top_viewed_videos'
# 从Redis的观看计数中获取排行数据
video_ids_with_scores = self.redis.zrevrange('video_view_counts', 0, limit - 1, withscores=True)
# 获取每个视频的详细信息
ranking = []
for video_id, view_count in video_ids_with_scores:
video_data = self.db.get_video_basic_info(video_id.decode('utf-8') if isinstance(video_id, bytes) else video_id)
if video_data:
video_data['viewCount'] = int(view_count)
ranking.append(video_data)
# 更新缓存,设置15分钟过期
self.redis.setex(cache_key, 900, json.dumps(ranking))
return ranking
def start_auto_update(self):
# 每15分钟更新一次排行榜缓存
def auto_update():
while True:
try:
self.update_ranking_cache()
except Exception as error:
logging.error(f'Error updating ranking cache: {error}')
time.sleep(15 * 60) # 15分钟
thread = threading.Thread(target=auto_update, daemon=True)
thread.start()
=
'video_cache:schedule'
delay_key = 'video_cache:delay'
# 普通视频每30分钟更新一次
self.redis.zadd(delay_key, {video_id: 1800}) # 30分钟
self.redis.zadd(schedule_key, {video_id: datetime.now().timestamp() * 1000})
def stop_video_cache(self, video_id):
schedule_key = 'video_cache:schedule'
delay_key = 'video_cache:delay'
self.redis.zrem(schedule_key, video_id)
self.redis.zrem(delay_key, video_id)
# 删除缓存的元数据
self.redis.delete(f'video_meta:{video_id}')
def run_video_cache_daemon(self):
while True:
try:
next_items = self.redis.zrange('video_cache:schedule', 0, 0, withscores=True)
if not next_items:
time.sleep(0.05)
continue
video_id, next_update_time = next_items[0]
video_id = video_id.decode('utf-8') if isinstance(video_id, bytes) else video_id
now = datetime.now().timestamp() * 1000
if float(next_update_time) > now:
time.sleep(0.05)
continue
delay = self.redis.zscore('video_cache:delay', video_id)
if not delay or float(delay) <= 0:
self.stop_video_cache(video_id)
continue
# 检查视频是否仍然活跃
view_count = self.redis.zscore('video_view_counts', video_id) or 0
if view_count < 100: # 观看次数太少的视频停止缓存
self.stop_video_cache(video_id)
continue
# 更新视频元数据缓存
self.refresh_video_metadata_cache(video_id)
# 安排下次更新时间
self.redis.zadd('video_cache:schedule', {video_id: now + float(delay)})
except Exception as error:
logging.error(f'Video cache daemon error: {error}')
time.sleep(1)
def refresh_video_metadata_cache(self, video_id):
# 刷新视频元数据的缓存
cache_key = f'video_meta:{video_id}'
# 这里应该从数据库重新获取数据并更新缓存
logging.info(f'Refreshing cache for video: {video_id}')
>
0
:
redis_client.hincrbyfloat(f'video_watch_time:{video_id}', user_token, watch_duration)
# 记录完成度(用于评估视频质量)
if completion_rate > 0:
redis_client.hset(f'video_completion:{video_id}', user_token, completion_rate)
# 保持最近观看的100个视频
redis_client.zremrangebyrank(f'user_watch_history:{user_token}', 0, -101)
# 更新用户活跃时间
redis_client.zadd('active_users', {user_token: timestamp})
# 增加视频总观看计数
redis_client.zincrby('video_view_counts', 1, video_id)
# 记录观看时间段(用于分析用户习惯)
hour = datetime.fromtimestamp(timestamp / 1000).hour
redis_client.zincrby(f'user_watch_hours:{user_token}', 1, hour)
'user_preferences:
{
user_token
}
'
,
0
,
19
)
candidate_videos = set()
# 基于协同过滤:找观看过相似视频的用户
for video_id_bytes in recent_videos[:5]:
video_id = video_id_bytes.decode('utf-8') if isinstance(video_id_bytes, bytes) else video_id_bytes
similar_users = self.find_users_with_similar_taste(video_id, user_token)
for similar_user in similar_users[:5]:
their_videos = self.redis.zrevrange(f'user_watch_history:{similar_user}', 0, 9)
for vid_bytes in their_videos:
vid = vid_bytes.decode('utf-8') if isinstance(vid_bytes, bytes) else vid_bytes
if vid not in recent_videos:
candidate_videos.add(vid)
# 基于内容相似性:找相同创作者或类别的视频
for video_id_bytes in preferred_videos[:3]:
video_id = video_id_bytes.decode('utf-8') if isinstance(video_id_bytes, bytes) else video_id_bytes
related_videos = self.find_related_videos(video_id)
candidate_videos.update(related_videos)
# 计算推荐分数
recommendations = self.score_recommendations(
list(candidate_videos),
user_token,
[vid.decode('utf-8') if isinstance(vid, bytes) else vid for vid in preferred_videos]
)
# 返回最高分的推荐
return sorted(recommendations, key=lambda x: x['score'], reverse=True)[:limit]
def find_users_with_similar_taste(self, video_id, exclude_user):
# 简化的协同过滤实现
users_who_watched = self.redis.hkeys(f'video_watch_time:{video_id}')
return [user.decode('utf-8') if isinstance(user, bytes) else user
for user in users_who_watched
if (user.decode('utf-8') if isinstance(user, bytes) else user) != exclude_user][:20]
def find_related_videos(self, video_id):
# 这里可以实现基于创作者、类别、标签的关联推荐
# 为了简化,我们返回一些模拟数据
return [f'related_{video_id}_1', f'related_{video_id}_2', f'related_{video_id}_3']
def score_recommendations(self, video_ids, user_token, preferred_videos):
scored = []
for video_id in video_ids:
score = 0
# 基础分数:观看热度
view_count = self.redis.zscore('video_view_counts', video_id) or 0
score += (view_count + 1).bit_length() * 0.3 # 使用对数近似
# 个性化分数:与用户偏好的相似度
categories = self.get_video_categories(video_id)
user_preferred_categories = self.get_user_preferred_categories(user_token)
category_overlap = len(set(categories) & set(user_preferred_categories))
score += category_overlap * 0.4
# 新鲜度分数:最近上传的视频加分
upload_time = self.get_video_upload_time(video_id)
days_since_upload = (datetime.now().timestamp() * 1000 - upload_time) / (1000 * 60 * 60 * 24)
score += max(0, (30 - days_since_upload) / 30) * 0.3 # 30天内新视频加分
scored.append({'videoId': video_id, 'score': score})
return scored
def get_video_categories(self, video_id):
# 从缓存或数据库获取视频类别
metadata = self.redis.get(f'video_meta:{video_id}')
if metadata:
data = json.loads(metadata)
return [data.get('category', '')]
return []
def get_user_preferred_categories(self, user_token):
# 基于用户观看历史推断偏好类别
recent_videos = self.redis.zrevrange(f'user_watch_history:{user_token}', 0, 49)
categories = set()
for video_id_bytes in recent_videos[:10]:
video_id = video_id_bytes.decode('utf-8') if isinstance(video_id_bytes, bytes) else video_id_bytes
cats = self.get_video_categories(video_id)
categories.update(cats)
return list(categories)
def get_video_upload_time(self, video_id):
metadata = self.redis.get(f'video_meta:{video_id}')
if metadata:
return json.loads(metadata).get('uploadTime', datetime.now().timestamp() * 1000 - (30 * 24 * 60 * 60 * 1000))
return datetime.now().timestamp() * 1000 - (30 * 24 * 60 * 60 * 1000) # 默认30天前