Redis扩展
当我们的小型应用逐渐成长为大型系统时,单台Redis服务器往往无法满足我们的需求。如果你的电商平台从每天几百个用户增长到几百万用户,或者你的社交应用从简单的消息推送发展到需要处理海量用户动态的复杂系统。 这时候,我们就需要学会如何扩展Redis,让它能够承载更大的数据量和更高的并发访问。
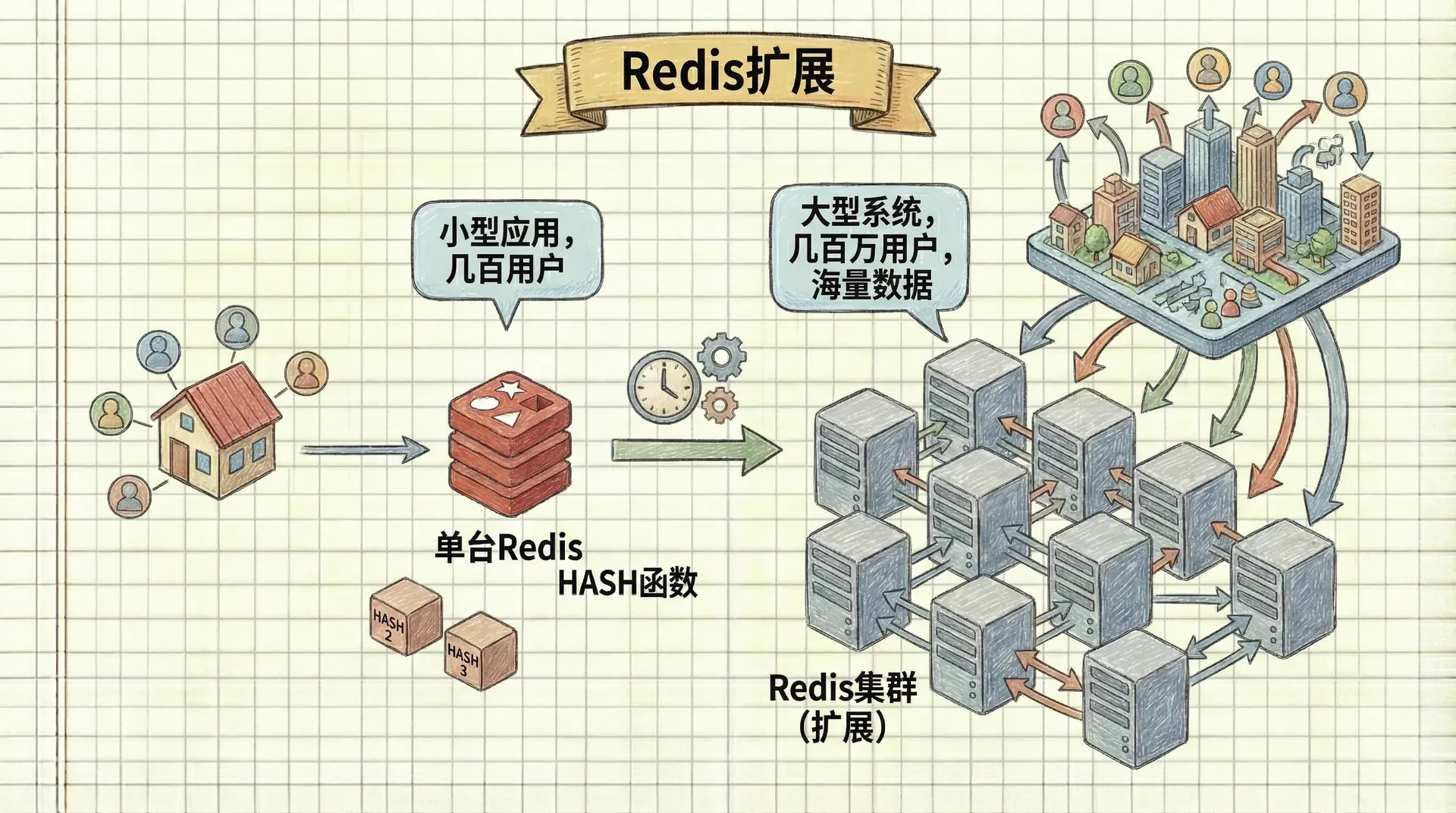
Redis扩展不仅仅是技术问题,更是业务发展的必然需求。掌握扩展技术,就是为你的应用未来做好准备。
在深入技术细节之前,让我们先理解为什么需要扩展Redis。Redis虽然性能卓越,但作为单线程的内存数据库,它也有自己的局限性。 想象你经营着一家在线教育平台,每天有数十万学生访问课程内容。最初,你使用单台Redis服务器缓存课程信息、用户会话和统计数据。随着业务增长,你开始遇到以下问题:
- 内存容量限制:课程视频的元数据、用户学习记录、考试结果等数据越来越多,单台服务器的内存无法容纳所有数据。
- 读写性能瓶颈:当同时有数万用户浏览课程时,单台Redis服务器无法处理如此高的并发请求,响应时间开始变慢。
- 可用性风险:如果这台Redis服务器出现故障,整个平台就会停止服务,影响所有用户的学习。
Redis扩展主要涉及三个维度:读操作扩展、写操作扩展和内存容量扩展。
读操作扩展
让我们从一个具体的场景开始:你运营着一个电商平台,商品详情页的访问量是写入量的100倍。每天有数百万用户浏览商品,但只有几万次商品更新操作。这种情况下,读操作扩展是最合适的解决方案。
主从复制
主从复制就像古代的“抄书”过程。主服务器(Master)是“原版书籍”,从服务器(Slave)是“手抄本”。每当主服务器有新的数据变化时,从服务器就会自动同步这些变化,保持数据一致性。
电商平台的读扩展实现
假设你的电商平台需要缓存商品信息。商品数据包括商品ID、名称、价格、库存、描述等。我们可以这样设计主从架构:
python
# 商品缓存服务的主从配置
class ProductCacheService:
def __init__(self):
# 主服务器用于写操作
self.master = redis.Redis(host='master-server', port=6379)
# 从服务器列表用于读操作
self.slaves = [
redis.Redis(host='slave1-server', port=6379),
redis.Redis(host='slave2-server', port=6379),
redis.Redis(host='slave3-server', port=6379)
]
self.slave_index = 0 # 用于轮询选择从服务器
def set_product(self, product_id, product_data):
"""写入商品信息到主服务器"""
key = f"product:{product_id}"
# 将商品数据序列化为JSON存储
self.master.hset(key, mapping=product_data)
# 设置过期时间,避免内存泄漏
self.master.expire(key, 3600) # 1小时过期
def get_product(self, product_id):
"""从从服务器读取商品信息"""
key = f"product:{product_id}"
# 轮询选择从服务器,实现负载均衡
slave = self.slaves[self.slave_index % len(self.slaves)]
self.slave_index += 1
# 从从服务器获取数据
product_data = slave.hgetall(key)
if product_data:
# 将字节串转换为字符串
return {k.decode(): v.decode() for k, v in product_data.items()}
return None在实际部署中,我们需要考虑网络延迟、数据同步频率等因素。对于电商平台这样的高并发场景,我们可以进行以下优化:
记住一个重要的原则:所有写操作必须发送到主服务器。如果向从服务器写入数据,Redis会返回错误。这是为了保证数据一致性的基本要求。
写操作和内存扩展
当你的应用不仅读操作多,写操作也很多时,仅仅使用主从复制就不够了。这时候我们需要使用分片技术,将数据分散到多台服务器上。
分片的基本思想
分片就像把一个大仓库分成多个小仓库。每个小仓库负责存储一部分商品,这样既增加了总存储容量,也提高了并发处理能力。 想象你的在线教育平台需要存储数百万学生的学习记录。如果所有数据都存储在一台服务器上,不仅内存不够用,写操作也会成为瓶颈。 通过分片,我们可以将学生数据按照某种规则(比如学生ID的哈希值)分散到多台服务器上。
选择合适的分片键是分片技术成功的关键。分片键决定了数据如何分布到不同的服务器上。
让我们以在线教育平台为例,实现一个完整的分片方案:
python
import hashlib
import redis
class ShardedEducationService:
def __init__(self, shard_configs):
"""
初始化分片服务
shard_configs: 分片服务器配置列表
"""
self.shards = []
for config in shard_configs:
self.shards.append(redis.Redis(**config))
self.shard_count = len(self.shards)
def
分片的一致性哈希算法
为了实现数据分片时各个服务器负载更加均匀,同时还能方便地进行水平扩展,我们通常会采用一致性哈希算法。举个例子,如果你的Redis集群中新增或移除一台服务器,传统的哈希分片会导致大量的数据需要重新分布,而一致性哈希算法只需要重定位一小部分相关的数据,大部分键值依然会落在原来的分片上,这极大提升了系统的伸缩性和稳定性。这也是为什么在需要动态扩展分片架构时,一致性哈希成为主流选择。
python
import hashlib
import bisect
class ConsistentHash:
def __init__(self, nodes=None):
"""初始化一致性哈希环"""
self.nodes = [] # 存储节点在哈希环上的位置
self.node_map = {} # 存储位置到节点的映射
if nodes:
for node in nodes:
self.add_node(node)
def add_node
电商系统的完整扩展方案
接下来,我们以一个典型电商平台为例,详细说明如何将上面介绍的各种Redis扩展方案组合起来,满足实际业务需求。大家可以想象,电商系统日常需要承载巨大的访问量,包括但不限于商品浏览、用户购物车管理、下单结算、以及实时库存校验等环节。 每一个环节都对应着不同的数据访问模式与压力,这使得我们必须灵活地设计Redis的扩展方式。
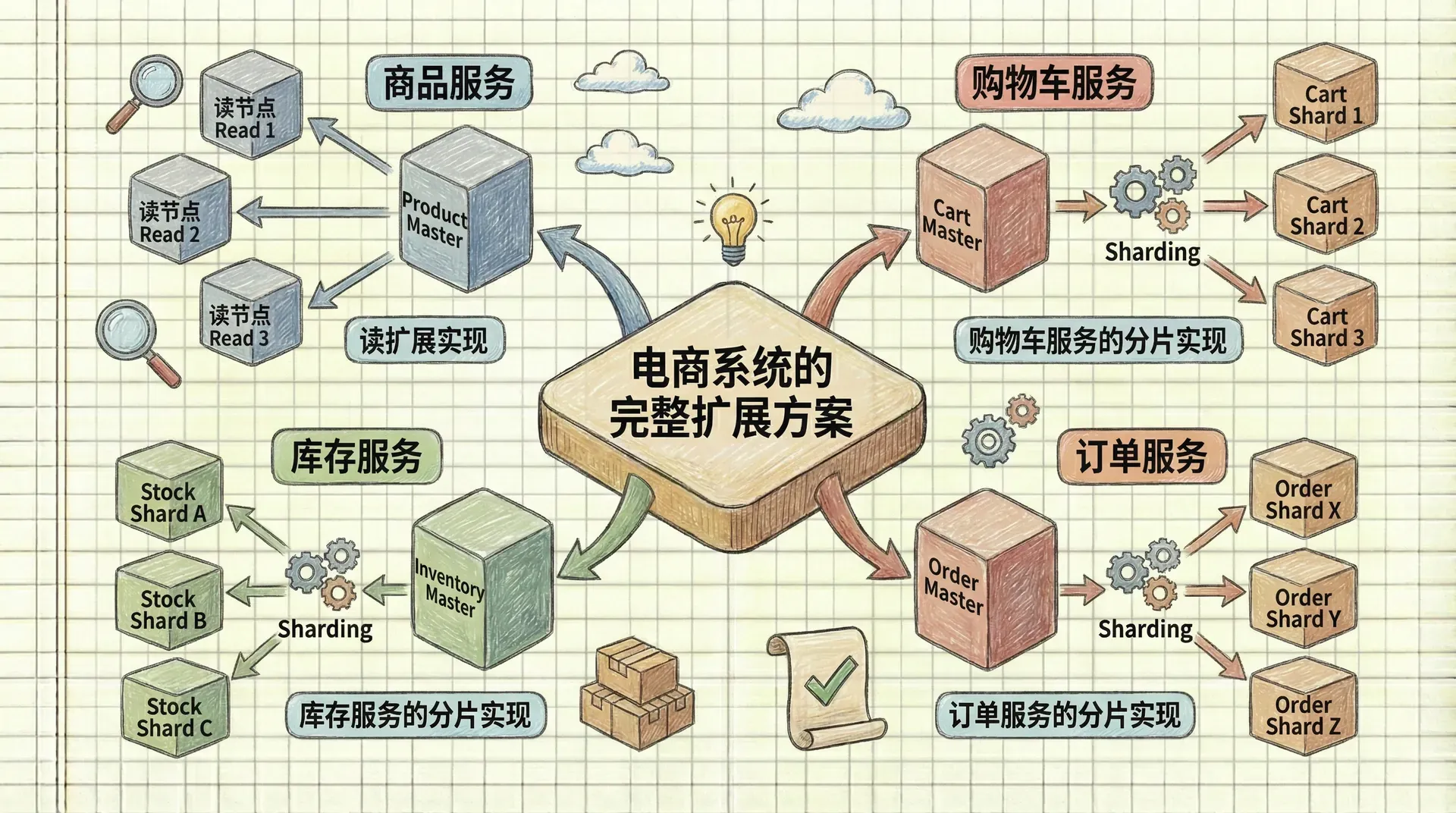
系统架构设计
为了应对复杂多变的业务需求,这个电商系统整体采用了分层的技术架构。每一层根据其特点和压力场景,采用最适合的扩展策略。例如:商品服务读多写少,非常适合用主从复制提升读取性能;购物车、订单、库存等等写入和容量需求大,则通过分片扩展分散压力。 从宏观上看,各服务既能独立扩展,又能整体协同,确保系统既高性能又高可用。
商品服务的读扩展实现
在一个电商系统中,商品信息无疑是最核心的数据之一。通常来说,用户浏览商品详情的次数远远多于商品本身的更新频率,也就是大家常说的“读多写少”场景。 为了让商品详情页面响应又快又稳,我们可以为商品服务配置一套主从复制集群:主服务器负责所有写操作(比如商品价格调整、库存更新),而多个从服务器则专门用来响应海量的商品详情查询。这 样一来,哪怕短时间内有几十万用户同时浏览热门商品,系统也能轻松应对,极大提升了读取性能和整体并发能力。
python
class ProductService:
def __init__(self):
# 主服务器配置
self.master = redis.Redis(
host='product-master',
port=6379,
decode_responses=True
)
# 从服务器配置
self.slaves = [
redis.Redis(host='product-slave1', port=6379
购物车服务的分片实现
在实际业务场景中,购物车数据往往面临着海量用户的高并发读写请求。为了保障系统的性能和扩展能力,我们通常会采用分片技术来进行数据存储和管理。具体做法是:根据用户ID等字段,将不同用户的购物车数据均匀地分散存储到多个Redis实例(分片)上。这样一来,可以显著提升读写吞吐量,避免单点瓶颈的出现,也为后续的容量扩展提供了便利。
python
class ShoppingCartService:
def __init__(self, shard_configs):
self.shards = []
for config in shard_configs:
self.shards.append(redis.Redis(**config, decode_responses=True))
self.shard_count = len(self.shards)
def _get_shard(self, user_id):
"""根据用户ID计算分片"""
hash_value = hash(user_id)
库存服务的分片实现
在电商平台中,库存管理扮演着至关重要的角色。我们不仅要考虑每一件商品库存数据的准确性,防止超卖、少卖等问题,还要能应对大量并发下单时的压力。如何既保证数据一致,又能让系统承受高并发请求?一个合理的分库分片方案就是关键所在。
python
class InventoryService:
def __init__(self, shard_configs):
self.shards = []
for config in shard_configs:
self.shards.append(redis.Redis(**config, decode_responses=True))
self.shard_count = len(self.shards)
def _get_shard(self, product_id):
"""根据商品ID计算分片"""
hash_value = hash(product_id)
订单服务的分片实现
在实际电商业务中,订单属于需要长期保存的重要数据。随着用户量和订单量的不断增长,如果所有订单都存储在同一个Redis实例中,势必带来存储和访问的巨大压力。为了提升系统的可扩展性和性能,我们可以将订单数据按照一定的规则做“分片”,即拆分到多个Redis实例上存储。这样,每个Redis实例只负责一部分订单,读写压力分散,整体系统就能支撑更多的订单量并保持高效运行。
python
class OrderService:
def __init__(self, shard_configs):
self.shards = []
for config in shard_configs:
self.shards.append(redis.Redis(**config, decode_responses=True))
self.shard_count = len(self.shards)
def _get_shard(self, order_id):
"""根据订单ID计算分片"""
hash_value = hash(order_id)
在实际应用中,选择合适的扩展策略需要考虑多个因素。让我们通过对比下表分析来帮助大家做出最佳选择:
在实际的大型系统中,我们往往需要组合使用多种扩展策略。比如我们的电商系统:
扩展不是一劳永逸的解决方案。随着业务发展,你需要持续监控系统性能,及时调整扩展策略。
小结
通过本部分,我们认识了Redis扩展的三种主要方式:读扩展、写扩展和内存扩展。不同的业务场景下,需要灵活选择最合适的扩展策略。一般来说,可以先从主从复制实现读扩展入手,再视业务增长逐步引入数据分片来实现写扩展和内存扩展,既提升性能,也提升系统的可用性和容量。 在扩展过程中,特别要关注数据一致性、扩展空间预留和系统的持续监控优化,这些都是保障稳定运行和后续演进的关键。
随着云计算、容器和智能化技术的发展,Redis扩展也在持续进化,未来会有更多自动化和高效的方案。只有持续关注新技术、不断优化实践,才能让你的Redis系统始终支持业务的高速发展。
我们的 Redis 课程到这里就结束了,相信你现在已经能够自信地在实际项目中灵活应用 Redis。如果遇到挑战,也别忘了回来看一看哦,祝你们技术不断进步!