使用 Pydantic 定义请求与响应模型
当我们用FastAPI写接口写到一定规模时,真正决定代码质量与团队协作效率的,往往不是路由写得有多快,而是我们是否认真对待“数据的形状”。所谓“形状”,指的是请求进来时我们允许什么、拒绝什么,指的是响应出去时我们承诺什么、隐藏什么,也指的是我们在代码里如何把这些约束讲清楚,让类型提示、自动文档、测试与运行时行为彼此一致。FastAPI把这件事交给了Pydantic,而Pydantic又把这件事落回到Python类型系统上,于是我们终于可以用一种非常工程化的方式,把输入输出的契约写进代码,并让框架替我们持续执行。
这一部分中,我们会以“我们正在构建一套可长期维护的API”为目标,循序渐进地把Pydantic在FastAPI中的关键用法串起来。我们会先从最朴素的请求体与响应体开始,接着讨论字段约束、默认值与可选字段,再进入嵌套结构、枚举与判别联合类型这类更贴近真实业务的数据形态。然后我们会回到工程视角,专门讲“响应瘦身”“敏感字段保护”“ORM对象如何安全输出”,以及如何让错误信息更适合前端与调用方消费。最后,我们还会把Pydantic v1与v2的差异说清楚,让我们写出来的代码既现代,又不会在依赖升级时失控。
从最小的请求模型开始
我们先从一个具体的端点出发。假设我们在写一个“创建课程”的接口,课程有标题、简介、难度级别与作者信息。我们当然可以把请求体当作原始字典处理,但那样做意味着每一个字段的存在性、类型、长度、可选性都要我们手写校验,同时文档也要我们手写维护。更糟糕的是,一旦代码演进,校验与文档很容易落后于真实逻辑。
FastAPI鼓励我们直接用Pydantic模型来表达请求体。我们会发现,当我们把结构写成模型后,验证、转换与文档会自动对齐,这种“减少人肉同步”的工程价值,会随着项目增长而越来越明显。
python
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class CourseCreate(BaseModel):
title: str
description: str
level: str
author: str
@app.post("/courses")
def create_course(payload: CourseCreate):
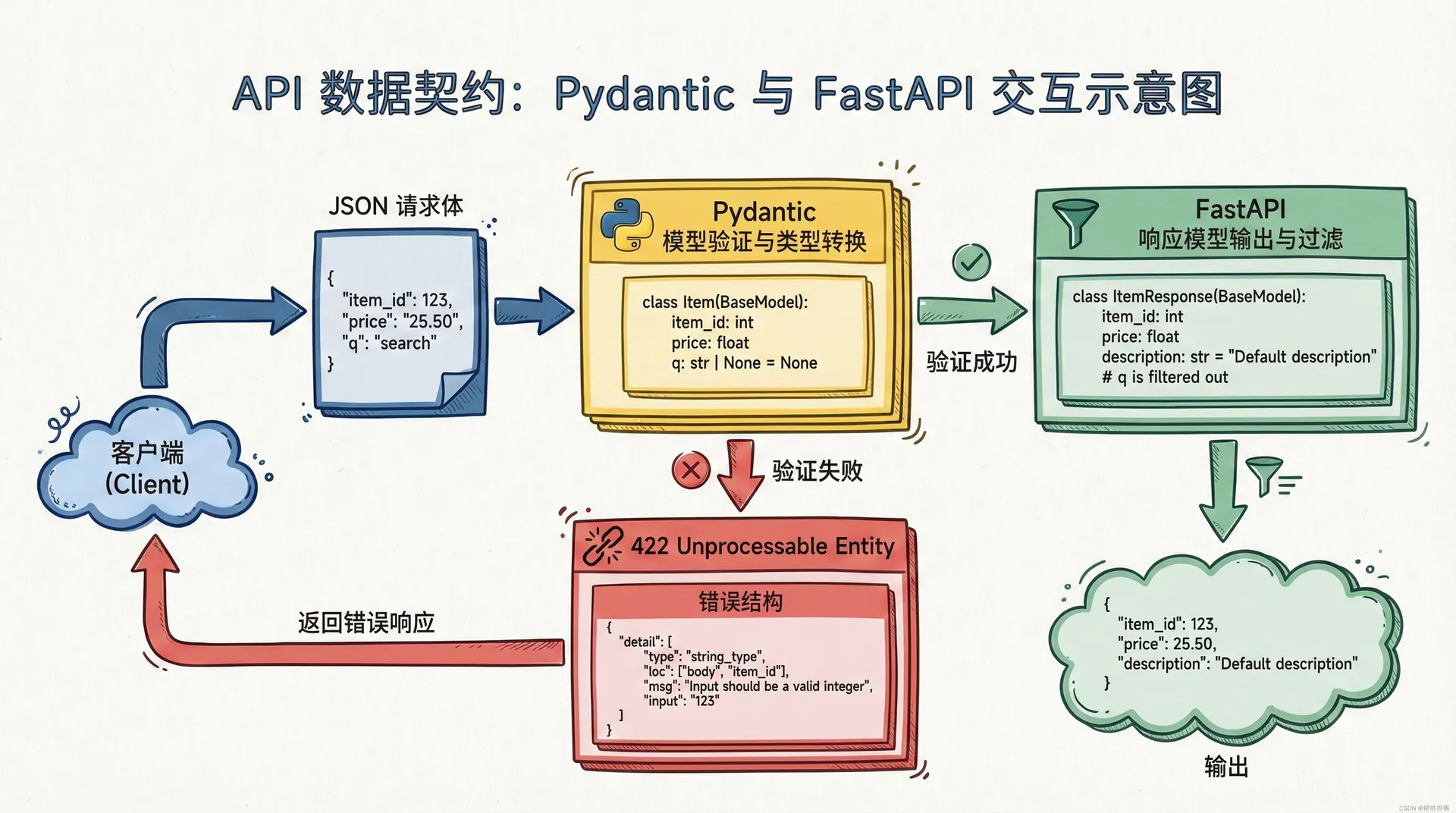
return {"message": "created", "course": payload.model_dump()}如果我们用Pydantic v1,model_dump()需要替换成dict(),但思想完全一致:我们让模型负责“把外部世界的JSON变成我们能在代码里自信使用的对象”。这时,FastAPI会把请求体解析成CourseCreate,并在进入函数之前做完类型验证。一旦字段缺失、类型错误或结构不匹配,FastAPI会直接返回422,并给出字段级别的错误定位。我们在路由函数里就可以专心处理业务,不必被校验细节拖住。
用字段约束把业务规则写进模型
现实的业务字段从来不只是“字符串”或“整数”,而是带着规则来的。标题不能太短,简介可能允许为空,难度可能只能是几个固定值,作者名可能要去掉首尾空格,甚至还可能需要做一些跨字段的约束。Pydantic让我们把这些规则写在模型层,而不是散落在路由函数中。
使用 Field 表达边界条件
我们先把最常见的长度、范围这类约束写出来。我们会注意到,模型一旦表达了规则,文档也会同步展示这些限制,这对调用方非常友好。
python
from pydantic import BaseModel, Field
class CourseCreate(BaseModel):
title: str = Field(..., min_length=2, max_length=80, description="课程标题")
description: str = Field(..., min_length=10, max_length=2000, description
当调用方传一个只有1个字符的标题时,我们不需要写任何if判断,Pydantic会自动拒绝请求并返回“标题太短”的验证错误。我们在工程上得到的好处是:规则被集中管理,而且被持续执行。
用枚举限制离散取值
当某个字段只能取若干固定值时,把它写成str是最容易出错的,因为任何拼写错误都会溜进系统。我们可以用Enum把允许的取值集合显式化。
python
from enum import Enum
from pydantic import BaseModel, Field
class CourseLevel(str, Enum):
beginner = "beginner"
intermediate = "intermediate"
advanced = "advanced"
class CourseCreate(BaseModel):
title: str = Field(..., min_length=2,
这样一来,文档会直接列出可选值,客户端也可以把这些值当作强约束来处理。更重要的是,我们在代码里拿到的payload.level会是一个枚举成员,而不是随意的字符串,这会让后续逻辑更稳。
通过字段别名兼容外部协议
有时我们接入的客户端已经确定了字段命名,比如用course_title而不是title,或者用authorName这样的驼峰。我们不想为了外部协议把内部代码也改得别扭,这时字段别名就很有用。
python
from pydantic import BaseModel, Field
class CourseCreate(BaseModel):
title: str = Field(..., alias="course_title", min_length=2, max_length=80)
description: str
author: str = Field(..., alias="authorName")
model_config 当客户端发送course_title时,模型能解析成功,而我们在代码里仍然用payload.title。如果未来我们要支持两种字段名同时存在,也可以通过配置实现,而不必把“兼容性逻辑”散落到业务代码里。
可选字段、默认值与“只更新提供的字段”
当我们写更新接口时,最常见的需求是“部分更新”。调用方不需要把完整对象都发回来,它只想改动一两个字段。我们当然可以用原始字典来处理,但那会让校验逻辑复杂且容易遗漏。更好的方式是定义一个“Update模型”,把字段都设为可选,并在应用更新时只拿到调用方提供的那些字段。
python
from typing import Optional
from pydantic import BaseModel, Field
class CourseUpdate(BaseModel):
title: Optional[str] = Field(None, min_length=2, max_length=80)
description: Optional[str] = Field(None, min_length=10, max_length=
然后我们在路由里用“排除未设置字段”的方式,得到真正需要更新的补丁数据。Pydantic v2用model_dump(exclude_unset=True),v1用dict(exclude_unset=True),我们写法上需要注意版本差异,但思路完全一致。
python
from fastapi import FastAPI, HTTPException
app = FastAPI()
fake_db = {
1: {"id": 1, "title": "FastAPI 入门", "description": "第一版", "author": "我们"}
}
@app.patch("/courses/{course_id}")
def patch_course(course_id: int, payload: CourseUpdate):
这段代码看似简单,但它体现了一个很关键的工程原则:我们让模型负责“什么是合法的补丁”,让更新逻辑负责“如何应用补丁”。职责分离之后,出错概率就会明显下降。
嵌套模型与复杂对象结构
真实世界的请求往往是嵌套的。一个课程可以有作者对象,作者可以有社交链接,课程可以有多个章节,每个章节又有若干小节。如果我们坚持用扁平字段,模型会很快变得难以维护。Pydantic让我们像搭积木一样把结构组合起来,使模型既表达清楚,又便于复用。
作者对象与章节数组
python
from typing import List, Optional
from pydantic import BaseModel, Field, HttpUrl
class Author(BaseModel):
name: str = Field(..., min_length=2, max_length=40)
email: Optional[str] = None
homepage: Optional[HttpUrl] = None
class Lesson(BaseModel):
当请求进来时,FastAPI会把整棵JSON树一次性验证并转换成嵌套模型对象。我们在路由函数里拿到的,是一组结构良好、字段类型确定的对象树。我们可以直接写payload.author.homepage、payload.chapters[0].lessons[0].duration_minutes,而不用担心KeyError或类型混乱。
复用模型并避免“复制粘贴的结构漂移”
当我们开始复用模型时,会遇到一个很常见的问题:创建模型与响应模型不完全一致。创建时有密码,响应时不能包含密码;创建时不需要id,响应时一定要有id。我们不希望重复定义所有字段,因为重复很容易产生漂移。更好的策略是用“基础模型 + 扩展模型”的方式,把公共字段抽出来。
python
from datetime import datetime
from pydantic import BaseModel, EmailStr
class UserBase(BaseModel):
username: str
email: EmailStr
class UserCreate(UserBase):
password: str
class UserOut(UserBase):
id: int
created_at: datetime当我们把这套模式用在课程上时,维护成本会显著下降,因为公共字段只写一次,扩展模型只表达差异点。
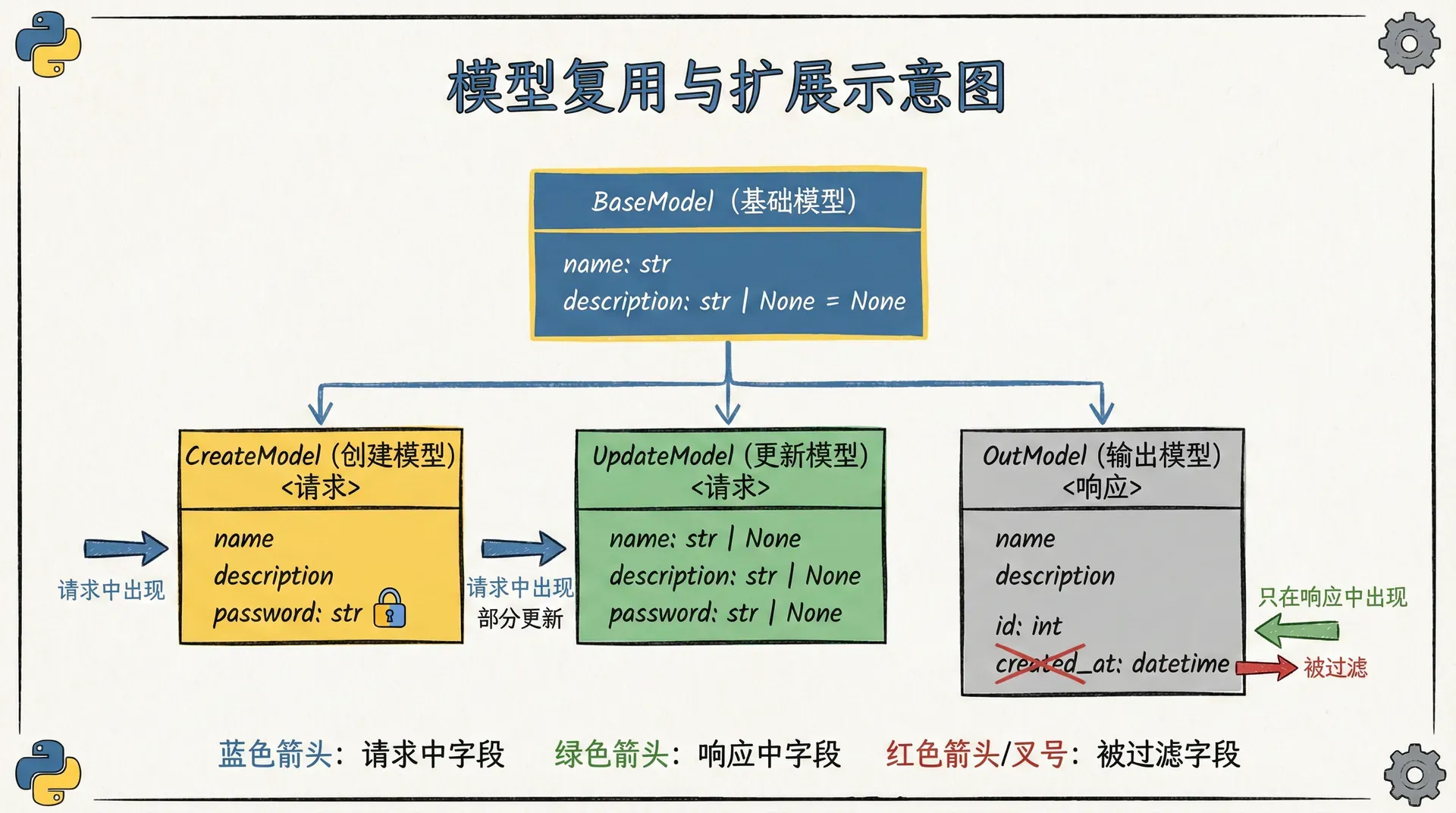
响应模型:我们对外的承诺
请求模型是我们对输入的要求,响应模型则是我们对输出的承诺。很多团队在早期会忽视响应模型,只返回字典或ORM对象,靠约定来维持一致性。短期看很快,长期看会让客户端难以依赖,也让后端在演进时容易“悄悄改变输出”,造成线上兼容性事故。
FastAPI允许我们通过response_model明确声明响应形状,让框架帮我们过滤多余字段、做类型转换、并把这一切体现在OpenAPI文档里。我们应该把它当成API契约的一部分,而不是可有可无的装饰。
python
from fastapi import FastAPI
from pydantic import BaseModel, Field
from datetime import datetime
app = FastAPI()
class CourseOut(BaseModel):
id: int
title: str
description: str
author: str
created_at: datetime
@app.get("/courses/{course_id}", response_model
这个例子里我们故意返回了internal_flag与secret,但响应模型只会输出CourseOut中声明的字段。我们会发现,这种“默认只输出契约字段”的机制非常适合做安全兜底,尤其是在我们不小心把内部字段带入返回值时,它能在框架层面拦下来。
用 response_model_exclude 与 response_model_include 做精细控制
有时我们需要同一个端点在不同场景下输出不同视图,例如管理员可以看到更多字段,普通用户只能看到公开字段。我们可以通过response_model_exclude或response_model_include在路由层做精细控制,而不必为每个视图创建完全不同的模型。我们当然也可以创建多个Out模型,选择哪一种取决于团队偏好与复杂度,关键是输出必须可控。
python
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class UserOut(BaseModel):
id: int
username: str
email: str
is_admin: bool
@app.get("/users/{user_id}/public", response_model=UserOut, response_model_exclude={"email"
ORM对象、from_attributes 与“把数据库世界翻译成API世界”
当我们接入SQLAlchemy或其他ORM后,常见的做法是从数据库拿到ORM对象,然后直接返回。FastAPI确实能在很多情况下帮我们序列化,但我们必须清楚地知道:ORM对象通常包含延迟加载关系、内部状态、甚至敏感字段。我们应该把“把ORM对象翻译成API响应”当成一个明确的步骤,而不是指望框架猜对我们的意图。
Pydantic v2提供了from_attributes=True的配置,用来从对象属性读取字段。Pydantic v1则是orm_mode = True。我们在团队里最好统一一种写法,并在升级时成体系地调整。
python
from datetime import datetime
from pydantic import BaseModel
class CourseORM:
def __init__(self, id: int, title: str, description: str, author: str):
self.id = id
self.title = title
self.description = description
self.author = author
self
当我们用这种方式做“显式翻译”时,内部字段不会被输出,同时模型仍然会做类型检查。这个习惯非常重要,因为它让数据库层与API层保持边界清晰,边界清晰的系统在演进时才不会失控。
让错误信息对人类与机器都友好
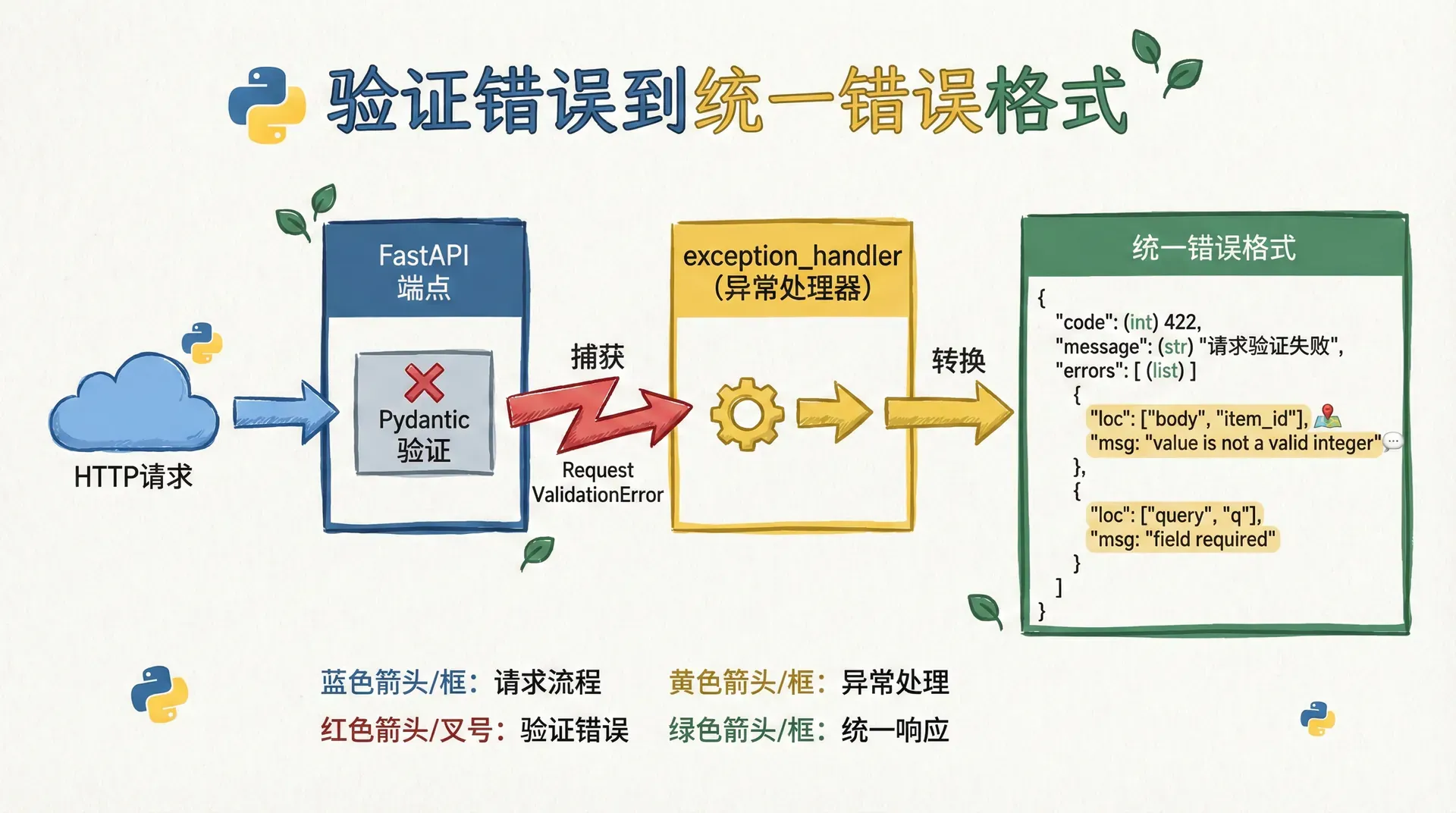
FastAPI默认返回的422错误已经很可用了,它会告诉我们哪里错了、错的是什么类型。我们仍然可以进一步把错误包装得更符合业务语义,例如当我们希望前端统一用code与message来展示时,我们可以自定义异常处理器,把Pydantic的验证错误翻译成我们内部的错误格式。
python
from fastapi import FastAPI, Request
from fastapi.responses import JSONResponse
from fastapi.exceptions import RequestValidationError
app = FastAPI()
@app.exception_handler(RequestValidationError)
async def validation_exception_handler(request: Request, exc: RequestValidationError):
normalized = []
for e in exc.errors():
normalized.append({
"loc": e.get("loc"),
"msg": e.get(
我们要谨慎对待自定义错误格式这件事,因为它一旦成为对外契约,就需要长期维护。但是在中大型项目里,统一错误格式通常能显著提升客户端处理体验,也能减少前后端在“错误展示”上的沟通成本。
批量接口与列表模型:别把“数组”当成附属品
批量接口经常被实现得很粗糙,要么不验证每一个元素,要么错误信息难以定位。Pydantic对列表模型的支持非常自然,我们只要把列表元素类型写清楚,验证就会逐个发生,错误定位也会精确到数组下标。
python
from typing import List
from pydantic import BaseModel, Field
class TagCreate(BaseModel):
name: str = Field(..., min_length=1, max_length=20)
class BulkTagCreate(BaseModel):
tags: List[TagCreate] = Field(..., min_length=1当调用方传入tags里某个元素的name为空,错误会指向具体下标。我们在排查与沟通时会省去大量“到底是哪条数据坏了”的时间,这就是模型带来的工程收益。
Pydantic v1 与 v2:我们如何写得更稳
Pydantic v2在性能与API上都发生了变化。FastAPI在逐步拥抱v2,但生态中仍存在大量v1写法。我们在课程里不需要死记每个差异点,但我们需要把几个关键变化记牢,避免未来升级时踩坑。
当我们在v2里想把模型变成字典,应该使用model_dump()而不是dict()。当我们想做验证与转换,应该使用model_validate()而不是parse_obj()。当我们希望从ORM对象读取属性,应该使用model_config = {"from_attributes": True}而不是Config.orm_mode = True。这些变化背后的逻辑是:v2把“验证”和“序列化”两个概念拆得更清晰,也把配置统一到了model_config里。
为了让我们的教学代码尽可能面向未来,这一章的示例默认使用v2写法。如果你的项目仍在v1上,我们只需要把model_dump()换成dict(),把model_validate()换成parse_obj()或直接实例化模型即可。关键在于我们掌握的是“模型驱动API契约”的思维,而不是某一个函数名。
小结
到这里,我们已经把Pydantic在FastAPI中的核心用法串成了一条完整的路线。我们从最简单的请求体开始,把字段约束、枚举、别名、可选字段与部分更新逐步加入,然后走进嵌套结构与模型复用,最后又回到工程视角,通过响应模型过滤、ORM翻译与统一错误格式,把“契约”真正落在可维护的实现上。 我们发现,Pydantic并不是让我们写更多代码,它是在让我们把“本来就必须思考的数据规则”写得更清楚、更集中,并且让框架持续帮我们执行。
下一节课我们将进入身份验证与授权,我们会把“谁能访问什么”的规则也写成可组合、可测试的依赖与模型,让我们的API不仅正确,而且安全。