聚合数据模型
当我们谈论数据库时,经常会听到「数据模型」这个词。但究竟什么是数据模型呢?数据模型本质上是我们理解和操作数据的一种思维框架。它决定了我们如何看待数据、如何与数据交互,以及如何思考数据之间的关系。
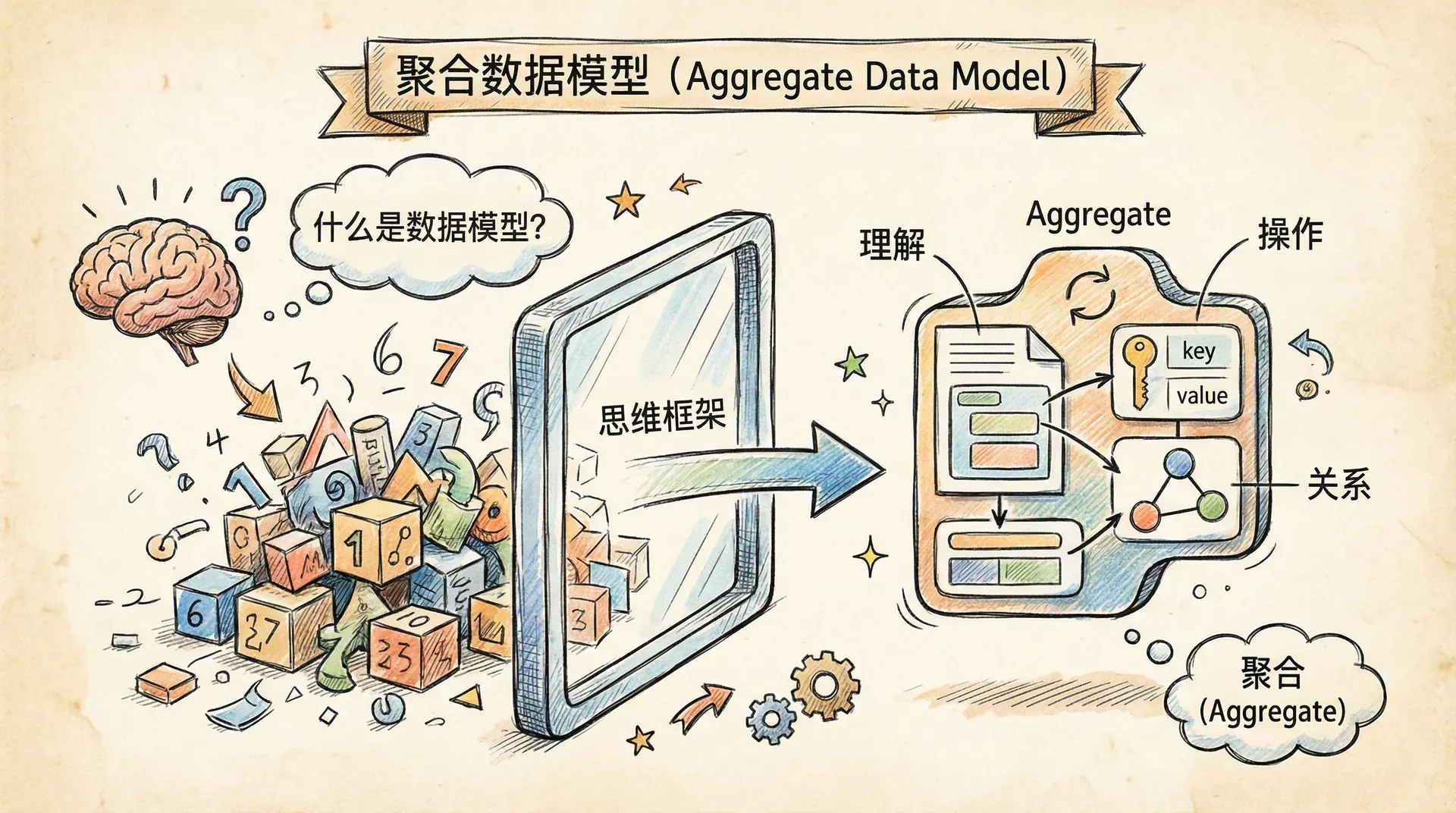
数据模型不同于存储模型。数据模型关注的是「我们如何理解数据」,而存储模型关注的是「数据库如何在硬盘上存储数据」。理想情况下,我们不需要关心存储模型的细节,但为了获得更好的性能,我们通常需要对存储模型有一定的了解。
在过去的几十年里,关系型数据模型一直占据着主导地位。我们可以把关系型数据库想象成一个巨大的电子表格,其中包含多个表格。每个表格都有行和列,行代表具体的数据实体,列代表这个实体的各种属性。 比如,在一个学生管理系统中,我们可能有一个「学生」表,每一行代表一个学生,每一列代表学生的不同信息,如姓名、年龄、专业等。
关系型模型的一个重要特点是标准化(规范化),这意味着我们会尽量避免数据的重复存储。每个数据只在一个地方存储,其他地方通过引用来访问这个数据。这种设计确保了数据的一致性,但也带来了复杂性。
NoSQL数据库的出现标志着数据建模思维的重大转变。与关系型数据库不同,NoSQL数据库采用了不同的数据组织方式。我们可以将NoSQL数据库分为四大类:键值存储、文档数据库、列族数据库和图数据库。
其中,前三种类型都有一个共同的特征,我们称之为「聚合导向」。这种导向性代表了一种全新的数据组织理念,它认识到在很多情况下,我们需要将相关的数据作为一个整体来处理,而不是像关系型数据库那样将数据分散在多个表中。
什么是聚合
假设你正在开发一个在线书店系统。在传统的关系型数据库中,你可能会将数据分散存储:用户信息在一个表中,订单信息在另一个表中,订单明细又在第三个表中,收货地址存在第四个表中。当用户想查看他的订单详情时,数据库需要从多个表中查询数据并拼接起来。
聚合导向的数据库采用了不同的思路。它将那些经常一起访问的相关数据组织成一个「聚合」单元。在我们的书店例子中,一个订单聚合可能包含订单的基本信息、购买的书籍列表、收货地址、支付信息等所有相关数据。当我们需要访问订单信息时,可以一次性获取所有相关数据。
聚合的概念来源于领域驱动设计(Domain-Driven Design)。在这个设计理念中,聚合是一组相关对象的集合,我们希望将它们作为一个单元来处理。更重要的是,聚合是数据操作和一致性管理的基本单位。我们通常希望以原子操作的方式更新聚合,并且以聚合为单位与数据存储进行通信。
聚合导向的设计使数据库更容易在集群环境中运行。由于聚合定义了哪些数据经常一起访问,数据库可以将整个聚合存储在同一个节点上,减少跨节点查询的需要。
聚合导向的数据库在处理事务时也有其特殊性。传统的关系型数据库支持ACID事务,可以跨多个表进行原子操作。而聚合导向的数据库通常只支持单个聚合内的原子操作。这意味着如果我们需要原子地操作多个聚合,就必须在应用层面进行管理。
这种限制听起来像是一个缺点,但实际上,在大多数情况下,我们的原子性需求都可以控制在单个聚合内。这也是我们在设计数据聚合时需要考虑的重要因素:如何划分聚合边界,使得大部分业务操作都能在单个聚合内完成。
关系型与聚合型建模
让我们通过一个具体的在线学习平台例子来深入理解这两种建模方式的差异。假设我们要为「小虎学习平台」设计数据模型,需要存储学生信息、课程内容、学习进度、作业提交和课程评价等数据。
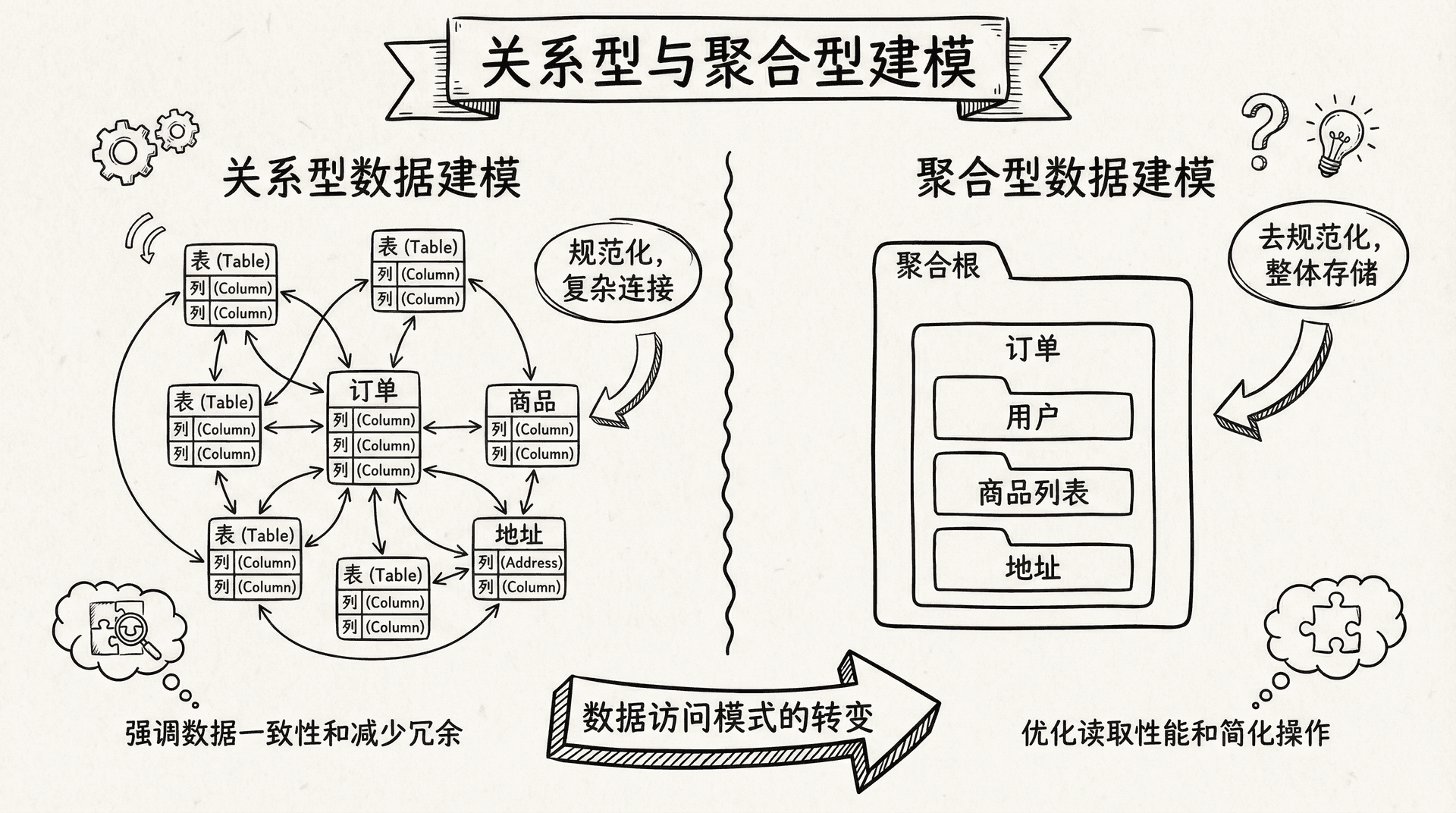
关系型数据建模
在关系型数据库中,我们会创建标准化的表结构:
这种设计完全符合关系型数据库的规范化原则。每个实体都有独立的表,通过外键建立关系。当学生想查看某门课程的学习情况时,数据库需要关联查询多个表:
sql
SELECT
c.课程名,
ch.章节名,
p.进度百分比,
s.提交时间
FROM 学生表 st
JOIN 学习进度表 p ON st.学生ID = p.学生ID
JOIN 章节表 ch ON p.章节ID = ch.章节ID
JOIN 课程表 c ON
聚合型数据建模
在聚合导向的数据库中,我们会重新组织这些数据。我们可能会设计两个主要的聚合:学生聚合和课程聚合。
学生聚合的JSON结构可能是这样的:
json
{
"studentId": "stu_12345",
"name": "张小明",
"email": "xiaoming@email.com",
"registrationDate": "2024-01-15",
"learningProgress": [
{
"courseId": "course_001",
"courseName": "NoSQL数据库入门",
"chapters": [
{
"chapterId": "ch_001",
"chapterName":
在这种设计中,当我们需要获取学生的学习情况时,只需要通过学生ID直接获取整个学生聚合,所有相关信息都包含在内。
这两种建模方式各有优劣。关系型建模避免了数据重复,但查询复杂;聚合型建模查询简单,但可能存在数据冗余。
如果我们将所有课程信息都嵌入到学生聚合中,那么当课程信息更新时,可能需要更新很多学生记录。这就是为什么我们需要根据具体的数据访问模式来设计聚合边界。
在实际应用中,我们可能会采用混合策略。比如,将学生的学习进度作为学生聚合的一部分,而将课程的基本信息作为单独的课程聚合。学生聚合中只保存课程的引用(如课程ID),这样既保持了聚合的完整性,又避免了过度的数据冗余。 聚合导向数据库的一个重要优势在于分布式环境下的性能。由于整个聚合都存储在同一个节点上,我们可以避免跨网络的数据查询,这对于大规模应用来说是相当重要的。
键值存储和文档数据库
正如前面我们提到的,键值存储、文档数据库和列族数据库均属于聚合导向型数据库范畴。下面将从专业的视角分别阐述键值存储与文档数据库的主要特性与差异。
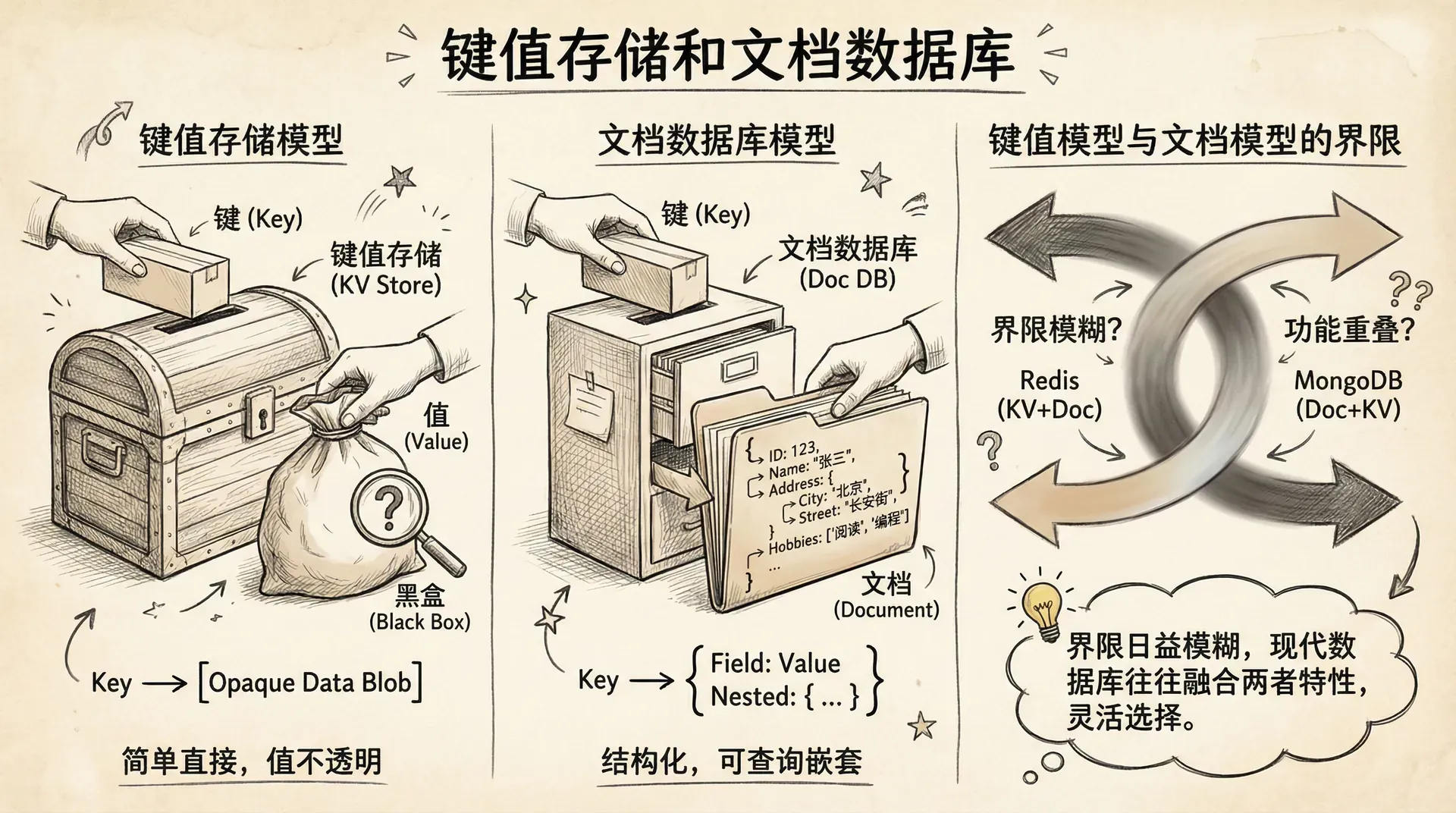
键值存储模型
键值存储是聚合导向数据库系统中最基础的一类,其核心数据模型是将数据以键(Key)-值(Value)对的形式进行组织和管理。每一个聚合体作为一个 value,均由唯一的 key 进行标识,并通过该 key 实现高效的点查操作。
从实现角度来看,键值存储系统等同于一个大规模分布式哈希表(Distributed Hash Table, DHT)。它对于 value 中存储的数据类型和内部结构没有任何语义上的理解或约束。换言之,每个聚合在键值存储中表现为“不可分割的二进制大对象”(opaque blob),系统仅负责存取,不提供基于 value 内容的查询能力。
键值存储的最大特点在于数据模型的极致简化——系统只关注键和值之间的对应关系,对值的内容和格式不做任何语义理解,也不存在结构校验。这种架构赋予了系统高度的灵活性和扩展能力。 无论我们存储的是纯文本、结构化的JSON、序列化对象还是任意二进制大对象(如图片、音视频文件),键值数据库都一视同仁,仅通过 key 实现高性能的存取操作。
这一模型非常适用于低延迟、高吞吐需求的场景,如分布式缓存、会话信息管理、用户自定义配置等。在实际应用中,Redis 便是该范式的典型代表,经常被用于分布式系统中的会话存储或热点数据缓存。
键值数据库只能按 key 精确定位数据,无法基于 value 内部属性进行检索或过滤。这意味着如需按业务属性(如年龄、地理位置等)进行查找时,必须依赖外部系统或对数据进行全量扫描,效率极低。
文档数据库模型
文档数据库在键值模型之上,引入了文档结构的解析与索引能力。每条记录仍由唯一 key 标识,但 value 部分必须是可以解析的文档格式(如 JSON、BSON、XML 等)。数据库能够识别、理解文档内部的多层级结构和字段语义,并据此自动构建索引、支持丰富的条件查询。 这使得用户不仅可以通过 key 检索文档,还能按内容字段精确、灵活查询、聚合与排序。例如,可以快速检索出年龄大于18岁、专业为“计算机科学”的所有学生文档,实现业务层的数据筛选与处理。
相比于传统键值存储,文档数据库更适用于业务数据结构复杂、需求经常变动、需要动态扩展字段类型的场景,显著提升了数据建模的灵活性与查询效率。
json
// MongoDB中的文档示例
{
"_id": "student_001",
"name": "王小红",
"age": 22,
"major": "计算机科学",
"courses": [
{
"courseId": "cs101",
"courseName": "数据结构",
"grade": 92,
"semester": "2024春季"
},
{
在文档数据库中,我们可以执行复杂的查询操作:
javascript
// 查找所有计算机科学专业且年龄大于20岁的学生
db.students.find({
"major": "计算机科学",
"age": { "$gt": 20 }
})
// 查找某门课程成绩大于90分的所有学生
db.students.find({
"courses.courseId": "cs101",
"courses.grade": { "$gt": 90 }
})文档数据库具备投影查询能力,支持从文档中仅检索部分字段,无需加载完整文档。这一特性对于高维度、大体量文档在性能和网络传输上均有显著优势。
键值模型与文档模型的界限
尽管通常将键值存储与文档数据库概念区分开来,现实的技术实现中二者并非泾渭分明、孤立存在。业界许多主流键值数据库同样原生支持多种数据结构(如列表、集合、哈希表等),允许对聚合内部元素进行原子级操作,无需整体读取和重写整个 value。 例如,Redis 虽为典型的键值数据库,却可以灵活地操作哈希表中的单一域、高效增删集合成员等,具备一定的结构化数据访问能力。
shell
# Redis中的操作示例
$ HSET student:001 name "李明" age 23 major "软件工程"
$ HGET student:001 name
"李明"
$ HINCRBY student:001 age 1
24另一方面,一些文档数据库也支持通过文档ID进行简单的键值查找,这与键值存储的使用方式非常相似。
选择键值存储还是文档数据库,主要取决于你的查询需求。如果主要通过键来访问数据,键值存储可能更合适;如果需要基于内容进行复杂查询,文档数据库是更好的选择。
无论选择哪种类型,聚合导向的设计思想都是一致的:将相关数据组织在一起,减少跨数据块的查询,提高系统在分布式环境下的性能。
列族存储模型
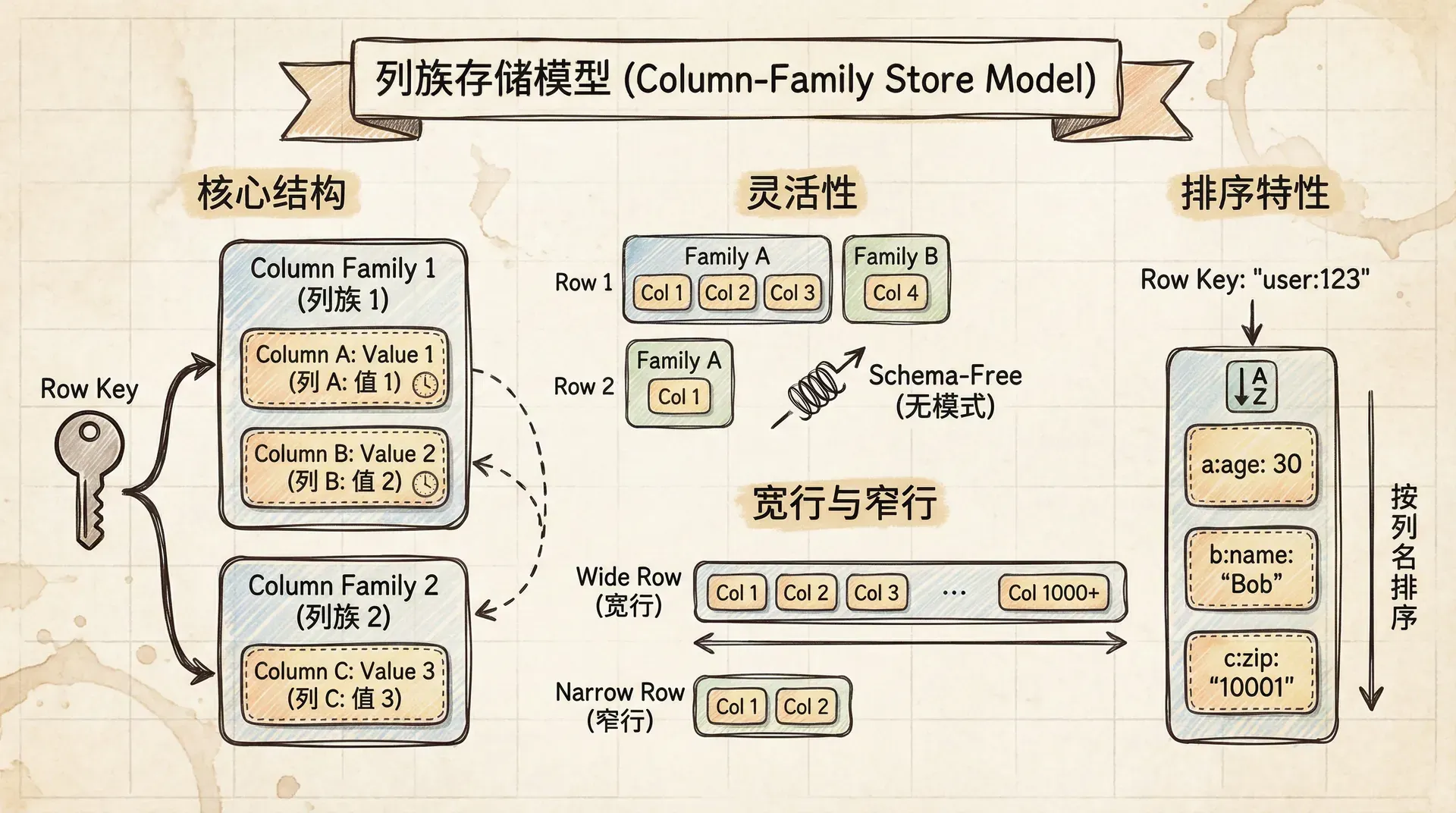
列族数据库属于聚合导向的数据库范畴,其数据模型兼具高扩展性与灵活性,在大规模分布式存储场景中尤为重要。该模型最早由 Google 的 BigTable 提出,随后被 Apache HBase、Apache Cassandra 等分布式数据库广泛采纳。 尽管名称涉及“列”一词,但列族数据库的列与传统关系型数据库的列本质上存在显著差异——前者强调的是列组对多维数据的高效组织和访问模式,并非平面表结构下的字段集合。
列族模型的核心结构
列族数据库本质上可视为「可扩展的稀疏二维映射」,以行键(Row Key)唯一确定数据聚合的主入口,并在其内部通过列族及具体列进行细粒度的数据组织。每个数据单元由(行键,列族,列限定符)三元组唯一定位,并可携带时间戳(Version),实现多版本并发控制(MVCC)。 结构上可抽象为如下:
以我们的学习平台为例,列族数据库中的数据可被组织如下:
在这个例子中,user_001是行键,而「基本信息」、「登录记录」、「学习统计」是不同的列族。每个列族内部可以包含多个具体的列。
列族的灵活性
列族数据库的一个重要特征是列的动态性。与关系型数据库不同,我们可以随时为任何行添加新的列,而不需要修改表结构。这种灵活性使得列族数据库非常适合存储半结构化数据。
考虑一个用户行为跟踪的场景。不同的用户可能有完全不同的行为记录:
在这个例子中,每个用户的行为记录都不同,有些用户可能没有某些类型的行为数据。在关系型数据库中,我们需要用NULL值来填充缺失的数据,但在列族数据库中,我们可以完全省略这些列,从而节省存储空间。
宽行与窄行
列族数据库中有两种截然不同的使用模式:窄行和宽行。 窄行模式类似于传统的关系型表格。每行有相对固定的列集合,不同行之间的列结构基本相同。在这种模式下,列族定义了一种记录类型,每行是一个记录实例,每列是一个字段。
text
用户表(窄行模式):
user_001: {name: "张三", age: 22, major: "计算机科学"}
user_002: {name: "李四", age: 21, major: "软件工程"}
user_003: {name: "王五", age: 23, major: "信息系统"}宽行模式则完全不同。一行可能包含成千上万的列,而且不同行的列结构可能完全不同。在这种模式下,我们实际上是在用列来表示列表或时间序列数据。
text
用户活动记录(宽行模式):
user_001: {
"2024-01-15T09:00": "登录",
"2024-01-15T09:05": "查看课程",
"2024-01-15T09:30": "开始学习",
"2024-01-15T10:15": "暂停学习",
... (可能有数千个时间戳列)
}列族的排序特性
列族数据库的另一个重要特性是列的自动排序。数据库会根据列键对列进行排序,这使得我们可以高效地进行范围查询。 比如,在上面的用户活动记录例子中,由于时间戳是按字典序排列的,我们可以轻松查询某个时间段内的所有活动:
text
// 查询用户在2024-01-15当天的所有活动
get_range(user_001, "2024-01-15T00:00", "2024-01-15T23:59")这种排序特性使得列族数据库特别适合处理时间序列数据、日志数据和其他需要范围查询的场景。
虽然列族数据库看起来像表格,但不要被表象迷惑。它的本质仍然是聚合导向的。每一行都是一个独立的聚合单元,我们需要根据数据访问模式来设计行键和列族结构。
设计列族结构时,最重要的原则是「一起访问的数据应该放在同一个列族中」。数据库会将同一列族的数据存储在一起,这样可以优化读取性能。
在我们的学习平台中,我们可能会设计三个主要的列族。首先是基本信息列族,用于存储用户的相对静态信息,如姓名、邮箱、注册时间等;其次是学习进度列族,存储动态的学习相关数据,如课程进度、测试成绩等;最后是活动日志列族,记录用户的行为轨迹,如登录时间、页面访问等。 这种设计确保了相关数据的访问效率,同时避免了不相关数据的干扰。
小结
聚合导向数据库(如键值存储、文档数据库和列族数据库)虽然实现方式不同,但都秉持以“聚合”为核心的理念。它们通过唯一键来高效访问和组织聚合,将每个聚合作为数据存储与操作的基本单元,这让数据库在分布式集群环境下能够便捷地分配数据,避免跨节点的通信提升了性能。 同时,聚合天然也成为数据更新的最小原子单位,虽然事务范围受限于单个聚合,但在大多数业务场景里已经足够使用。三类数据库各有亮点:键值存储弹性最大但不支持结构化查询,文档数据库可以理解聚合内容支持灵活检索,而列族数据库则用列族结构兼顾弹性与查询效率,尤其适用于半结构化与大规模数据。
不过,聚合导向并不适用所有场景。当业务主要关注单聚合高效读写时,这一模型非常合适。然而遇到跨聚合复杂查询或统计需求时,它反而会变得不那么灵活。这时,关系型数据库或图数据库可能更合适。归根结底,选择哪种数据库,还是要看应用场景、数据访问模式与系统需求是否相匹配——理解各种数据模型的长处和不足,才能做出最合适的技术决策。