性能、扩展性与多进程
在上一讲我们讨论了安全与认证基础,让接口的「谁可以访问」有了清晰边界。在服务既稳又安全的前提下,接下来要面对的是吞吐与扩展能力:单机单进程能扛多少请求、瓶颈从哪里来、如何利用多核与多进程把纵向扩展做上去。
这部分会围绕性能、扩展性与多进程展开:我们先说明 Node 的性能瓶颈从哪里来,以及单线程与事件循环在这一过程中的角色;接着介绍 Node 内置的 Cluster 模式,看如何用多进程监听同一端口并利用多核;最后归纳多核 CPU 的利用方式,以及它与单线程、事件循环的关系,并简要触及垂直扩展与水平扩展的思路。
Node.js 的性能瓶颈
单线程与 CPU 密集
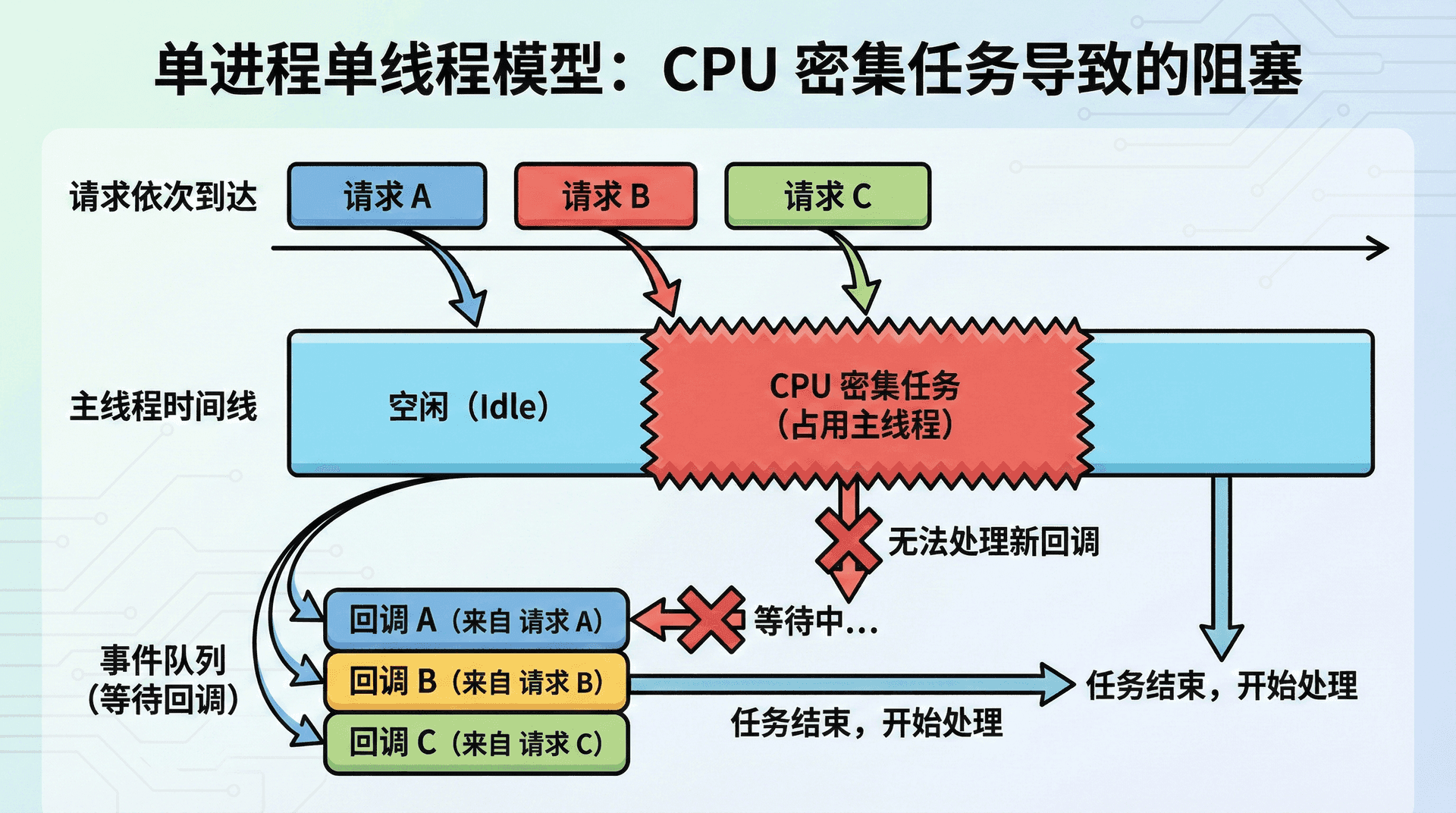
Node 的一个进程里只有一条执行 JavaScript 的主线程,事件循环在这条线程上不断取出任务并执行。当某段逻辑需要大量 CPU 运算时,例如复杂的业务计算、大对象的 JSON 解析或序列化、或密集的加密解密,这段逻辑会在这条主线程上持续执行,期间事件循环无法去处理其它已经就绪的回调。于是新到达的请求、已经完成的 I/O 回调都会在队列里等待,从外部看就是延迟升高、吞吐下降,甚至请求超时。这就是「单线程」带来的天然约束:CPU 密集型的计算会占满这条唯一的线程,从而拖住整个事件循环。
与此相关的是 I/O 与主线程的配合方式。Node 把 I/O 交给操作系统或线程池,主线程在 I/O 进行时可以去执行其它 JavaScript;但 I/O 完成之后,回调仍然要回到主线程上执行。若回调里又做了重计算或同步阻塞操作(例如在回调里同步读文件、或做大量 JSON 解析),整体吞吐仍然会受限于这条主线程能多快「消化」这些回调。因此,即便 I/O 再快,只要主线程上有长时间占用的 CPU 工作,就会成为瓶颈。
I/O 与事件循环
非阻塞 I/O 让 Node 在等待磁盘或网络时不必干等,而是把等待交给系统,主线程去处理其它任务;事件循环负责在「有就绪 I/O 或定时器」时把对应回调拉回主线程执行。这种模型在 I/O 密集场景下能发挥很大优势,因为多数时间主线程只是在「派发」与「收尾」,真正耗时的等待在别处完成。但当回调本身的执行时间变长时,例如在一次请求处理里做了大量同步计算、或调用了会阻塞的 API,单次回调就会长时间占用主线程,后面排队的请求都会受影响。
典型瓶颈场景往往同时涉及「主线程被占满」与「单进程无法利用多核」。例如接口层对请求体或响应体做大量 JSON 的解析与序列化、在业务逻辑里做复杂统计或排序、或误用同步文件 API 和阻塞式调用,都会拉长单次请求在主线程上的执行时间。再叠加「一个进程只能跑在一个 CPU 核上」的事实,单机单进程的吞吐上限就非常明显。要突破这一上限,就需要在进程维度做文章,让多个进程共同分担负载,从而利用多核 CPU。
Cluster 模式
主进程与子进程
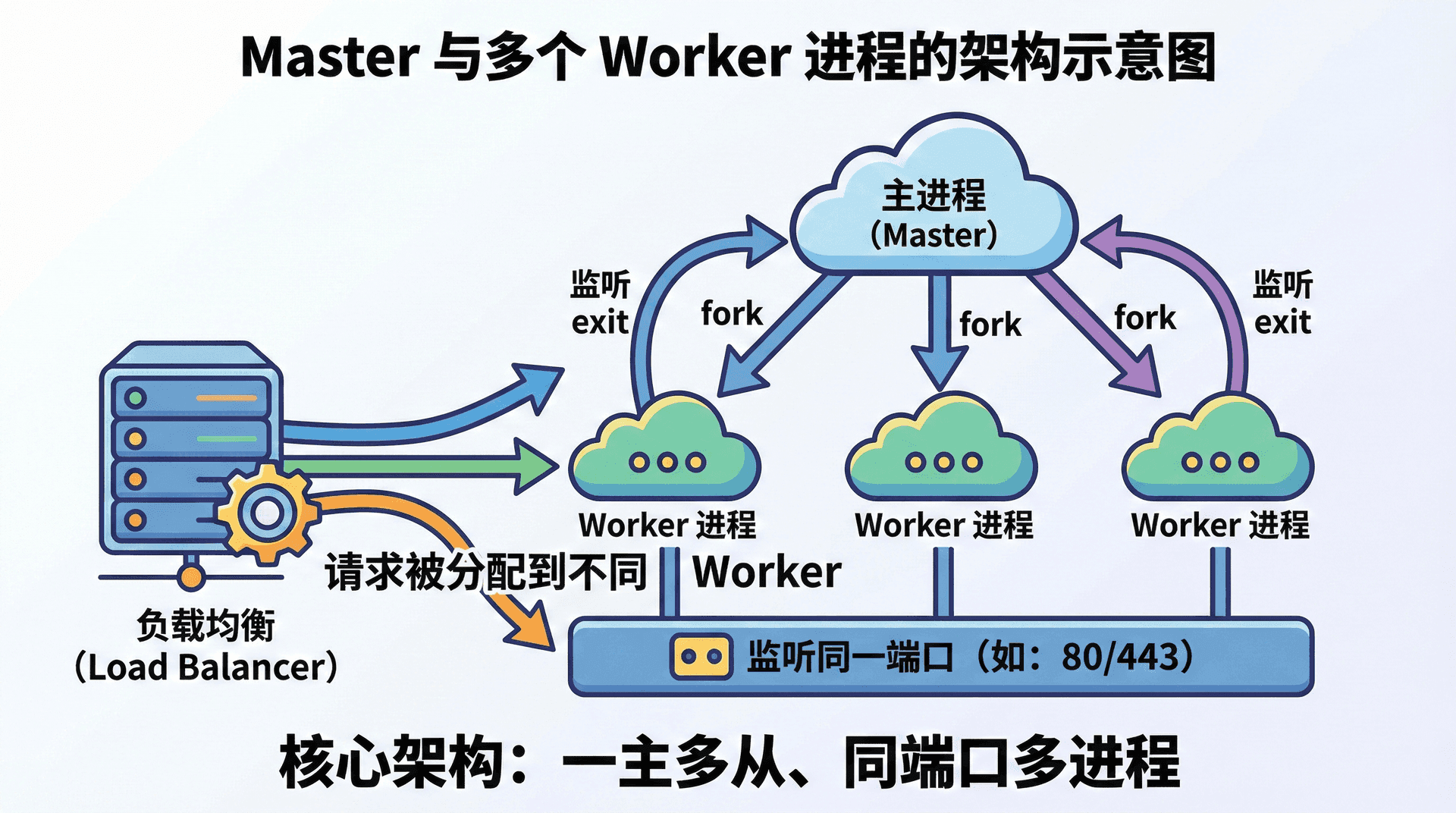
Node 内置的 cluster 模块提供了一种多进程方案:由一个主进程(在旧版 API 里常叫 master,新版里用 primary)负责创建并管理多个子进程(worker),每个子进程里运行一份你的应用代码,并且可以监听同一个端口。操作系统或 Node 会在这些进程之间做负载均衡,把到达该端口的连接分发到不同的 worker 上,从而在单机内用多进程利用多核。
主进程的职责是「管家」:根据你指定的数量或 CPU 核数调用 cluster.fork() 拉起子进程,监听子进程的 exit 等事件,在子进程异常退出时选择是否重新 fork() 以保持 worker 数量稳定。子进程之间不共享内存,各自有独立的事件循环和 V8 实例;若需要协作或共享状态,只能通过进程间通信(IPC)或外部存储(如 Redis、数据库)来完成。这种「主进程管生命周期、子进程干业务」的分工,与第十三讲里提到的「由进程管理器重启」的策略可以叠加:例如用 PM2 或 systemd 管主进程,主进程再通过 cluster 管多个 worker。
基本用法示例
下面这段代码演示如何用 cluster 模块在入口处区分主进程与子进程:主进程根据 CPU 核数(或配置)调用 cluster.fork() 拉起多个 worker,并在 worker 退出时重新 fork 以补足数量;子进程里则像单进程应用一样创建 HTTP 服务并监听端口,无需关心端口冲突,因为 cluster 与底层会在多进程间协调同一端口的监听。
javascript
const cluster = require('cluster');
const http = require('http');
const os = require('os');
const numCPUs = os.cpus().length;
if (cluster.isPrimary) {
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.error(`worker ${worker.process.pid} exited`);
cluster.fork();
});
} else {
http.createServer((req, res) => {
res.writeHead(200);
res.end(`handled by pid ${process.pid}\n`);
}).listen(3000);
}注意:在 Node.js 16+ 中,推荐使用 cluster.isPrimary 与 cluster.isWorker;旧版中对应的属性为 cluster.isMaster 与 cluster.isWorker,语义一致。主进程里只应做 fork、监控与重启等轻量逻辑,不要把繁重的业务或 I/O 放在主进程,否则会拖慢对子进程的管理;业务代码应全部运行在 worker 进程中。
主进程与子进程的生命周期是分离的:主进程退出会导致所有子进程被带走,因此部署时通常让主进程作为顶层进程由 PM2 或 systemd 管理。端口由多个 worker 共享时,由内核或 Node 的 cluster 逻辑负责分发连接,不要在业务里再手动监听同一端口。同时不要把耗时业务或大量 I/O 放在主进程,主进程只负责 fork 与监控,否则会成为单点瓶颈。
多核 CPU 的利用方式
进程与核的对应
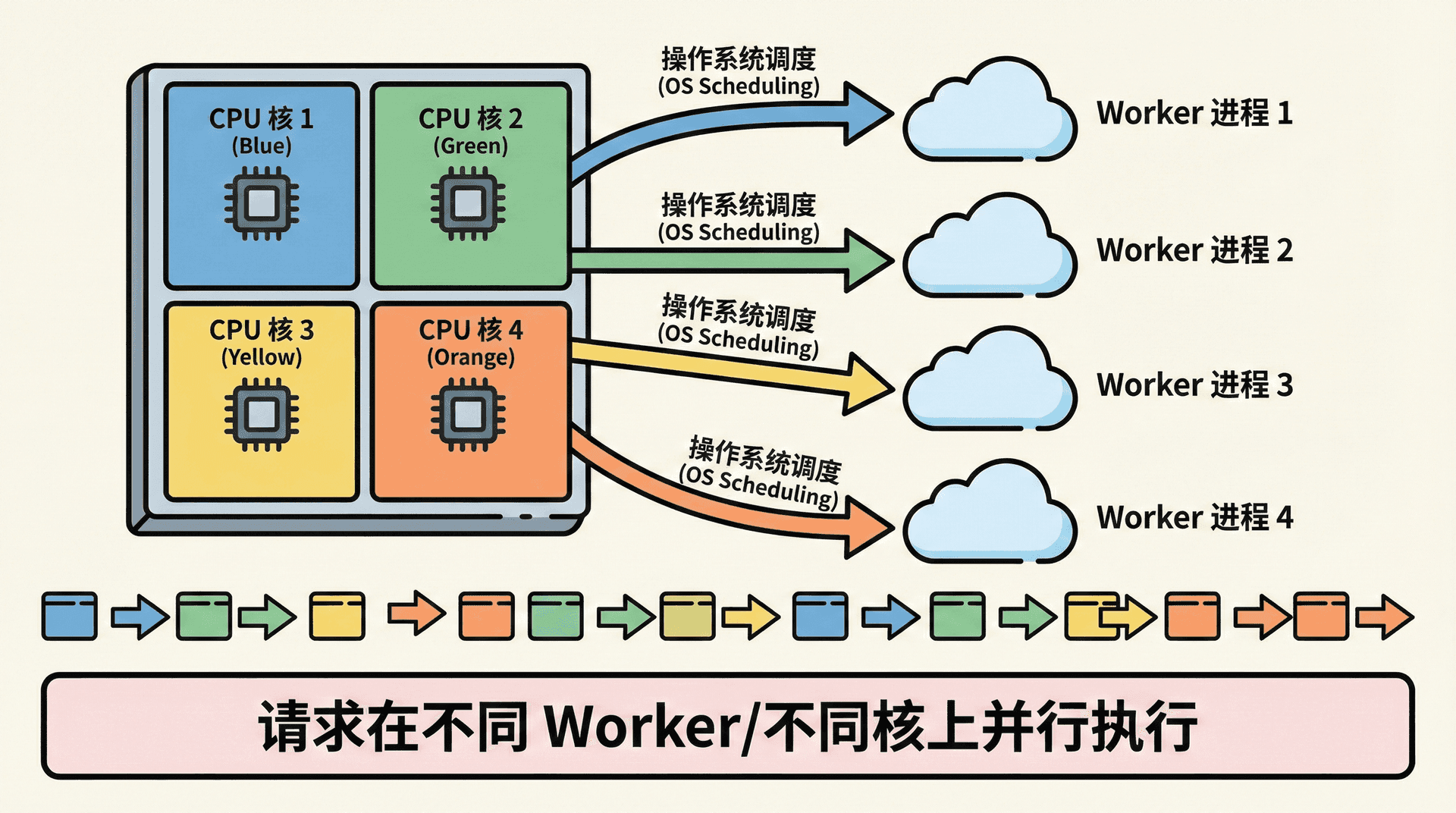
Cluster 模式下通常采用「一 worker 一进程」的对应方式:主进程 fork 出与 CPU 核数相同(或按配置略少)的 worker,每个 worker 绑定到不同核上由操作系统调度,从而在单机内把多核用满。Worker 数量可以取 os.cpus().length,也可以根据实际负载或预留核数做调整,例如留一核给主进程与系统时使用 numCPUs - 1。这样,多个请求会分散到不同进程、进而落在不同核上执行,单进程单线程的 CPU 瓶颈就被「横向」摊到多核上。
每个 worker 内部仍然是单线程加事件循环,并没有把 Node 变成多线程;多核的利用是在进程维度实现的,通过多进程并行来达到多核并行的效果。若业务里仍有少量 CPU 密集逻辑无法拆走,可以考虑配合 Worker Threads 在单进程内再开线程,但多数 Web 服务场景下,cluster 的多进程已经能显著提升吞吐。
与事件循环的关系
多进程并没有改变「每个进程里事件循环单线程」的模型。每个 worker 各自维护自己的事件循环和任务队列,请求 A 在 worker 1 上处理、请求 B 在 worker 2 上处理,两者是真正的并行。与第十三讲中的错误处理结合起来看:每个 worker 都应注册自己的 uncaughtException 与 unhandledRejection,在发生未捕获异常时该 worker 退出,由主进程的 exit 监听里重新 fork 补上;这样单 worker 崩溃不会拖垮整机,同时通过重启恢复可用性。
扩展思路可以分两个方向:在单机内通过 cluster 多进程把多核用满,属于垂直扩展(单机纵向);当单机容量仍不足时,再通过多机部署与负载均衡做水平扩展(多机横向)。进程管理器如 PM2、systemd 既可以管单进程,也可以管 cluster 模式下的主进程,并与「有序退出、重启恢复」的策略配合,形成稳定的生产部署方式。
接下来
这节课我们围绕性能、扩展性与多进程展开了三块内容。在Node.js 的性能瓶颈中,我们说明了单线程下 CPU 密集计算会占满主线程并拖住事件循环,导致请求排队与吞吐下降,同时提到 I/O 再快也受限于主线程对回调的消化能力,以及典型瓶颈往往与大量 JSON 处理、同步阻塞和单进程单核有关。
- 在Cluster 模式中,我们介绍了 Node 内置的 cluster 模块如何通过主进程 fork 多个子进程、子进程同端口监听并由系统或 Node 做负载均衡,并给出了主进程与 worker 分支、fork 数量与 exit 重启的示例代码,并提醒主进程只做轻量管理与端口共享的注意点。
- 在多核 CPU 的利用方式中,我们归纳了一 worker 一进程与多核的对应关系、多进程在进程维度并行而非单进程多线程的事实,以及垂直扩展与水平扩展的思路,并和错误处理、进程管理做了衔接。
理解了 Node 的性能瓶颈与 Cluster 多进程的用法之后,单机多核的利用就有了清晰路径。下一部分我们将讨论现代 Node.js 后端架构:Node 在 BFF 中的角色、与 Java 或 Python 后端的协作方式,以及 NestJS 的架构思想如何对标 Spring,从而把整门课从单机单进程带到更贴近现代工程实践的架构视角。