NLP文本生成任务
文本生成可能是NLP中最具挑战性的任务之一。当我们让模型将“The cat sat on the mat”翻译成中文时,它不仅要理解英文句子的含义,还要用流畅、自然的中文表达出来。 当我们让模型为新闻文章生成摘要时,它需要理解整篇文章的要点,并用简洁的语言概括。当我们让GPT-3续写故事时,它需要保持情节连贯、角色一致、文笔优美。
文本生成之所以困难,在于它要求模型在每一步都做出正确的选择。假设词表大小是30,000,生成一个50词的句子,理论上有种可能的序列。在这个天文数字般的搜索空间中,只有极少数序列是流畅、正确、符合要求的。模型如何找到这些“好”的序列?
这就是解码(decoding)的任务——给定训练好的模型,如何生成高质量的文本。在过去的十年中,研究者们开发了各种解码策略,每种策略都在质量、多样性、效率之间做出不同的权衡。
解码策略:在搜索空间中寻路
贪婪解码:最简单的选择
最直观的生成策略是贪婪解码(Greedy Decoding):在每一步,选择模型预测概率最高的词。形式化地说:
其中是输入(例如待翻译的源句子),是已经生成的词。
贪婪解码的优点显而易见:简单、快速、确定性。给定相同的输入,它总是生成相同的输出,这在某些场景(如机器翻译)中是可取的。计算复杂度是,其中是生成序列的长度,非常高效。
然而,贪婪解码有一个致命缺陷:它只关注局部最优,忽略了全局最优。考虑这个例子:
text
输入:"How are you?"(你好吗)假设模型在第一步面临选择:
- “你” (概率 0.5)
- “您” (概率 0.4)
- 其他 (概率 0.1)
贪婪解码会选择“你”。但也许选择“您”会导致更好的整体序列,比如“您好吗”比“你好吗”更符合某些语境。贪婪解码无法预见这一点,因为它只看当前步的概率。
这个问题在长序列生成中尤为严重。早期的一个次优选择可能把模型"锁定"在一条糟糕的路径上,后续无论怎么努力都无法弥补。这就像下棋时只看一步——虽然每一步都"看起来"不错,但可能导向一个糟糕的结局。
贪婪解码的另一个问题是重复。在开放式文本生成(如故事续写)中,贪婪解码常常陷入重复循环,生成像“I don't know. I don't know. I don't know.”这样的退化输出。这是因为一旦模型进入某个高概率的局部模式,贪婪策略会不断重复这个模式。
束搜索:平衡质量与效率
为了克服贪婪解码的短视,研究者们提出了束搜索(Beam Search)。束搜索的核心思想是:不要只追踪单一最优路径,而是同时维护条最有希望的候选路径("束")。
算法流程如下:
初始化:从起始符号<BOS>开始,候选集只有一个空序列。
扩展阶段(每一步):
- 对当前束中的每个候选序列,预测下一个词的概率分布
- 为每个序列的每个可能的下一个词计算累积概率
- 从所有个候选中,选择累积概率最高的个作为新的束
终止:当束中的序列都生成了结束符<EOS>,或达到最大长度时停止。
输出:选择束中概率最高的序列作为最终输出。
让我们用一个具体例子理解束搜索。假设我们用的束搜索翻译"Hello":
text
步骤0:
束 = [<BOS>]
步骤1: 扩展<BOS>
候选:
- "你" (概率 0.5) → 累积: log(0.5) = -0.69
- "您" (概率 0.3) → 累积: log(0.3) = -1.20
- "嗨" (概率 0.1) → 累积: log(0.1) = -2.30
选择top-2: 束 = ["你", "您"]
步骤2: 扩展两个候选
从"你"扩展:
- "你好" (概率 0.6) → 累积: -0.69 + log(0.6) = -1.20
- "你是" (概率 0.2) → 累积: -0.69 + log(0.2) = -2.30
从"您"扩展:
- "您好" (概率 0.7) → 累积: -1.20 + log(0.7) = -1.56
- "您是" (概率 0.15) → 累积: -1.20 + log(0.15) = -3.10
选择top-2: 束 = ["你好", "您好"]束搜索通过维护多个候选,缓解了贪婪解码的短视问题。在上面的例子中,虽然"你"的初始概率高于"您",但"您好"的整体概率最终超过了"你好",束搜索能够发现这一点。
长度归一化的必要性
束搜索有一个技术细节很重要:由于我们使用对数概率的和作为分数,较长的序列会累积更多的负对数概率(因为每个概率都小于1,对数为负)。这导致模型偏向于生成短序列。
为了解决这个问题,通常使用长度归一化:
其中是长度惩罚系数,通常取0.6-0.7。是完全归一化(按长度平均),是不归一化。实践中,在0.6左右效果最好,既鼓励了合理长度,又没有过度惩罚自然的长度差异。
束搜索的局限
尽管束搜索在机器翻译等任务上很有效,它也有明显的局限:
首先,束搜索仍然可能陷入重复问题。事实上,在开放式文本生成(如故事续写)中,束搜索的重复问题往往比贪婪解码更严重!Holtzman等人(2019)的研究发现,当用束搜索生成长文本时,模型会陷入"我们需要...我们需要...我们需要..."这样的重复循环。这是因为一旦某个模式进入束,它会在后续步骤中不断强化自己。
其次,束搜索倾向于生成通用、安全但无聊的文本。在对话系统中,束搜索常常生成"我不知道"、"好的"、"谢谢"这样的通用回复,因为这些回复在训练数据中频繁出现,概率较高。但这样的回复虽然"安全"(不会出错),却缺乏信息量和趣味性。
第三,束搜索的计算成本是贪婪解码的倍。对于大型模型(如GPT-3),即使,计算开销也可能令人望而却步。
采样方法:拥抱随机性
束搜索追求的是最大化模型的预测概率。但这真的是我们想要的吗?人类写作并不总是选择"最可能"的词——我们会使用同义词、变换句式、加入创意。过于追求高概率,可能导致输出单调、缺乏多样性。
这就引出了采样(Sampling)方法的动机:不是选择最高概率的词,而是按照概率分布随机采样。
纯粹的随机采样给模型带来了创造性。每次运行会生成不同的输出,这在创意写作、对话生成等任务中很有价值。采样避免了贪婪/束搜索的重复问题——即使陷入某个模式,随机性也会"踢"模型一脚,让它跳出循环。
然而,纯随机采样有个问题:它有时会采样到概率很低但不合理的词。模型的预测分布往往有一个长尾——大部分概率集中在少数合理的词上,但仍有很多低概率词。纯采样可能偶然选中这些低概率词,导致输出不连贯。
温度采样是一个简单但有效的改进。在采样前,用温度参数调整概率分布:
其中是模型的原始logits(softmax之前的值)。
温度的作用非常直观:
- :标准softmax,保持原始分布
- (如0.5):让分布更"尖锐",高概率词的概率进一步提高,低概率词被进一步抑制。生成更确定、保守
- (如1.5):让分布更"平坦",降低高概率词的统治地位,给低概率词更多机会。生成更随机、多样
温度采样让我们可以灵活控制生成的随机性。在需要创意的任务(如诗歌生成)中,使用较高温度;在需要准确性的任务(如摘要)中,使用较低温度。
Top-k与Nucleus采样:动态截断
温度采样虽然改善了纯随机采样,但仍然可能采样到不合理的词。一个更激进的想法是:只从最有希望的词中采样,直接忽略那些不靠谱的低概率词。
Top-k采样是最简单的实现:每步只从概率最高的个词中采样,其余词的概率设为0并重新归一化。例如,意味着只考虑最有可能的40个词。
Top-k采样在实践中效果不错,但有个问题:是固定的。然而,模型的"确定性"在不同时刻是不同的。有时模型非常确定下一个词(如"United"后面很可能是"States"),前几个词就占据了99%的概率,保留40个词是浪费。有时模型很不确定(如故事刚开始时),40个词可能不够捕捉所有合理选择。
Nucleus采样(Top-p采样)由Holtzman等人在2019年提出,优雅地解决了这个问题。它的思想是:不固定候选词的数量,而是固定候选词的累积概率。
具体地,选择最小的词集,使得这些词的累积概率达到阈值(通常或0.95):
然后只从中采样。
Nucleus采样的美妙之处在于它的自适应性:
- 当模型很确定时,nucleus很小(可能只有2-3个词),避免了不必要的随机性
- 当模型不确定时,nucleus扩大(可能有几十个词),给模型更多选择空间
这种动态调整让nucleus采样在质量和多样性之间取得了更好的平衡。Holtzman等人的实验表明,nucleus采样生成的长文本在流畅性和多样性上都超过了束搜索和top-k采样。
实现细节:
python
def nucleus_sampling(logits, p=0.9, temperature=1.0):
"""
Nucleus (top-p) 采样实现
Args:
logits: 模型输出的logits (vocab_size,)
p: 累积概率阈值
temperature: 温度参数
Returns:
采样得到的词索引
"""
# 应用温度
logits = logits / temperature
# 计算概率并排序
probs = F.softmax(logits, dim=-1)
sorted_probs, sorted_indices = torch.sort(probs, descending=True)
# 计算累积概率
cumulative_probs = torch.cumsum(sorted_probs, dim=-1)
# 找到超过阈值p的位置
# 注意:我们保留第一个超过p的词,因此要移位
sorted_indices_to_remove = cumulative_probs > p
sorted_indices_to_remove[1:] = sorted_indices_to_remove[:-1].clone()
sorted_indices_to_remove[0] = False # 总是保留概率最高的词
# 将要移除的词的概率设为0
probs[sorted_indices[sorted_indices_to_remove]] = 0
# 重新归一化
probs = probs / probs.sum()
# 采样
next_token = torch.multinomial(probs, 1)
return next_token在GPT-3、ChatGPT等现代语言模型中,nucleus采样已成为默认的解码策略。它在创造性和连贯性之间找到了甜蜜点,让模型既能生成有趣多样的文本,又不至于失控产生胡言乱语。
评估指标:如何衡量生成质量?
文本生成的评估是一个棘手的问题。不像分类任务有明确的对错,文本生成有多个合理的答案。“Hello”可以翻译成“你好”、“您好”、“嗨”,它们都是正确的,只是风格略有不同。那么,我们如何评估模型生成的文本质量呢?
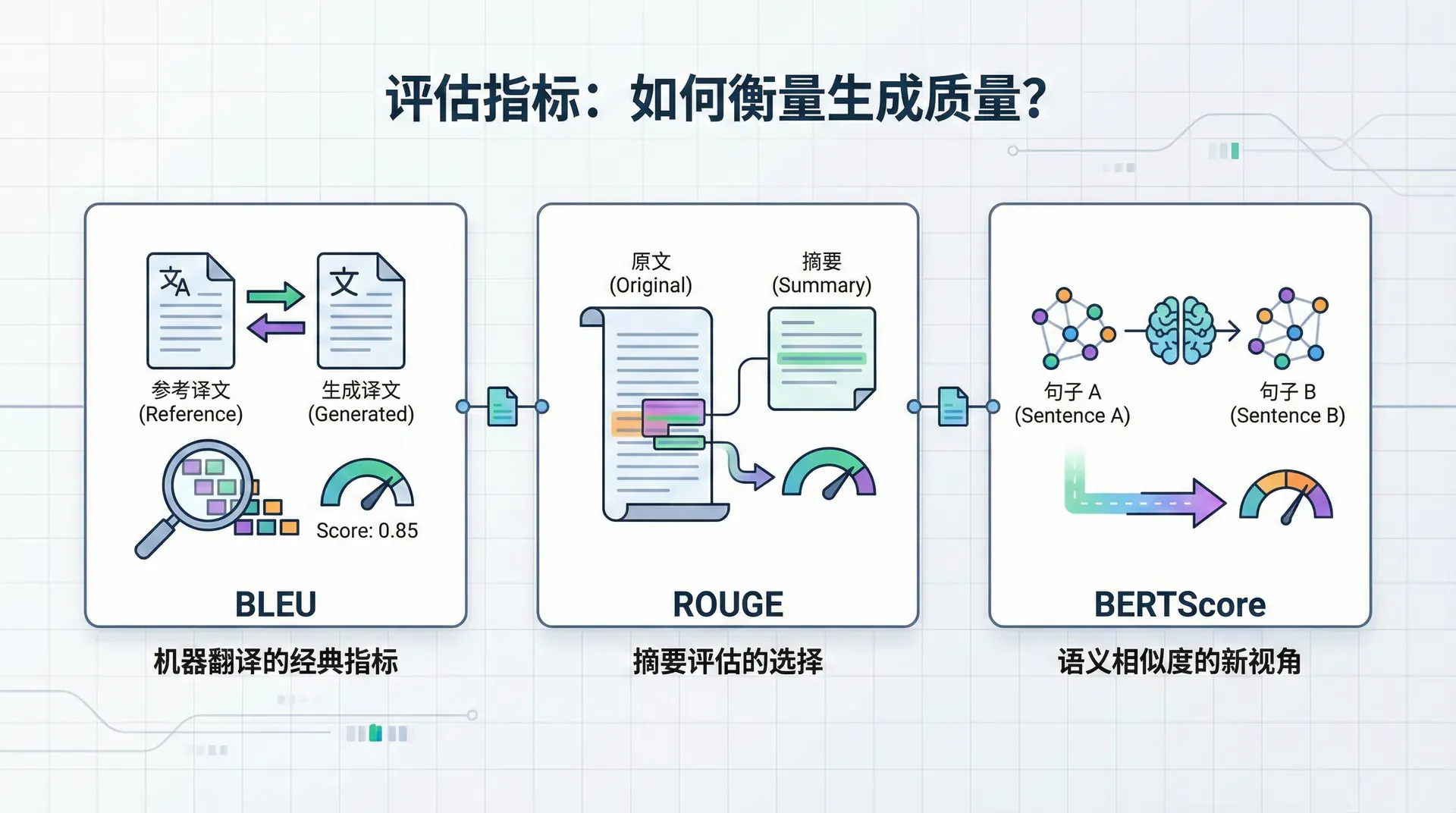
BLEU:机器翻译的经典指标
BLEU(Bilingual Evaluation Understudy) 由IBM在2002年提出,至今仍是机器翻译中最广泛使用的自动评估指标。
BLEU的核心思想是:好的翻译应该与人工翻译有很多共同的n-gram(n元词组)。例如,如果参考翻译是“the cat sat on the mat”,候选翻译“the cat on the mat”与参考共享了许多二元组(“the cat”, “on the”, “the mat”),因此应该得到较高分数。
形式化地,BLEU是修正后的n-gram精确率的几何平均:
其中:
- 是n-gram精确率:候选中有多少比例的n-gram出现在参考中
- 是权重,通常均匀分配(),N通常取4
- 是简短惩罚(Brevity Penalty),防止模型通过生成很短的句子来获得高精确率
简短惩罚的公式是:
其中是候选长度,是参考长度。如果候选短于参考,会受到指数惩罚。
BLEU的优缺点
BLEU的优点是简单、快速、语言无关。它不需要训练,只需要计数n-gram匹配,可以在几秒内评估数千个句子。这使得它成为机器翻译研究中快速迭代的工具。
然而,BLEU有明显的局限:
- 它只考虑词汇重叠,完全忽略语义。"The cat ate the mouse"和"The mouse ate the cat"会得到相同的BLEU分数(如果与"The cat ate the mouse"比较),尽管含义完全相反。
- BLEU对同义词不友好。"big"和"large"在语义上几乎相同,但BLEU会将它们视为完全不同,导致惩罚。
- BLEU对词序变化过于敏感。在某些语言(如德语)中,词序相对灵活,但BLEU会严重惩罚与参考不同的词序,即使句子流畅正确。
- BLEU与人类判断的相关性在句子级别很差。虽然在语料库级别(评估整个系统)时BLEU与人类评分有一定相关,但在单句级别,BLEU可能给流畅的翻译低分,给糟糕的翻译高分。
尽管有这些局限,BLEU仍然广泛使用,主要因为它简单且有历史惯性。研究者们报告BLEU分数,以便与以往工作比较。但明智的研究者会结合人工评估和其他指标来全面评估模型。
ROUGE:摘要评估的选择
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是针对文本摘要任务设计的指标。与BLEU强调精确率不同,ROUGE强调召回率——参考摘要中有多少信息被候选摘要捕获。
ROUGE有几个变体:
ROUGE-N测量n-gram召回率:
分子是候选和参考共享的n-gram数,分母是参考中的总n-gram数。
ROUGE-L基于最长公共子序列(LCS),考虑词的顺序而不仅仅是n-gram匹配。这对捕捉句子级的相似性更有效。
ROUGE-S考虑skip-bigram(跳跃二元组),允许词之间有间隔。例如,"the cat"和"the black cat"共享skip-bigram "the...cat"。
ROUGE的设计哲学是:一个好的摘要应该覆盖原文的主要信息。因此,强调召回率比精确率更重要——遗漏关键信息比包含少量冗余更糟糕。
然而,ROUGE也继承了BLEU的问题:只看词汇重叠,不理解语义。而且,ROUGE严重依赖参考摘要的质量。如果参考摘要本身不佳,ROUGE分数就失去了意义。
BERTScore:语义相似度的新视角
2019年,Zhang等人提出了BERTScore,这是第一个基于预训练语言模型的评估指标。BERTScore的核心思想是:不要比较词的表面形式,而是比较词的语义表示。
算法流程:
- 用BERT为候选和参考的每个词生成上下文相关的嵌入
- 对候选中的每个词,找到参考中余弦相似度最高的词
- 计算匹配分数的平均值
形式化地:
类似地可以定义Precision和F1。
BERTScore的优势是捕捉语义相似性。"big"和"large"会得到很高的BERTScore,因为它们的BERT嵌入非常接近。即使词序不同,只要语义相近,BERTScore也会给出高分。
实验表明,BERTScore与人类判断的相关性显著高于BLEU和ROUGE。在许多任务上,它已成为补充甚至替代传统指标的选择。
然而,BERTScore也有局限:计算成本高(需要运行BERT),对超长文本不友好,而且仍然是基于词级匹配,可能忽略句子级的逻辑和连贯性。
人工评估:最终的标准
尽管自动指标方便快捷,人工评估仍然是衡量文本生成质量的"黄金标准"。人类评估者可以判断:
- 流畅性:文本是否语法正确、读起来自然
- 充分性:是否充分表达了源信息(翻译、摘要)
- 连贯性:是否逻辑连贯、上下文呼应
- 相关性:是否切题、符合要求
人工评估通常让多位评估者对同一个输出打分,然后取平均或计算一致性。但人工评估成本高、速度慢、主观性强、不可重现。因此,实践中通常结合自动指标(用于快速迭代)和人工评估(用于最终验证)。
文本生成的挑战
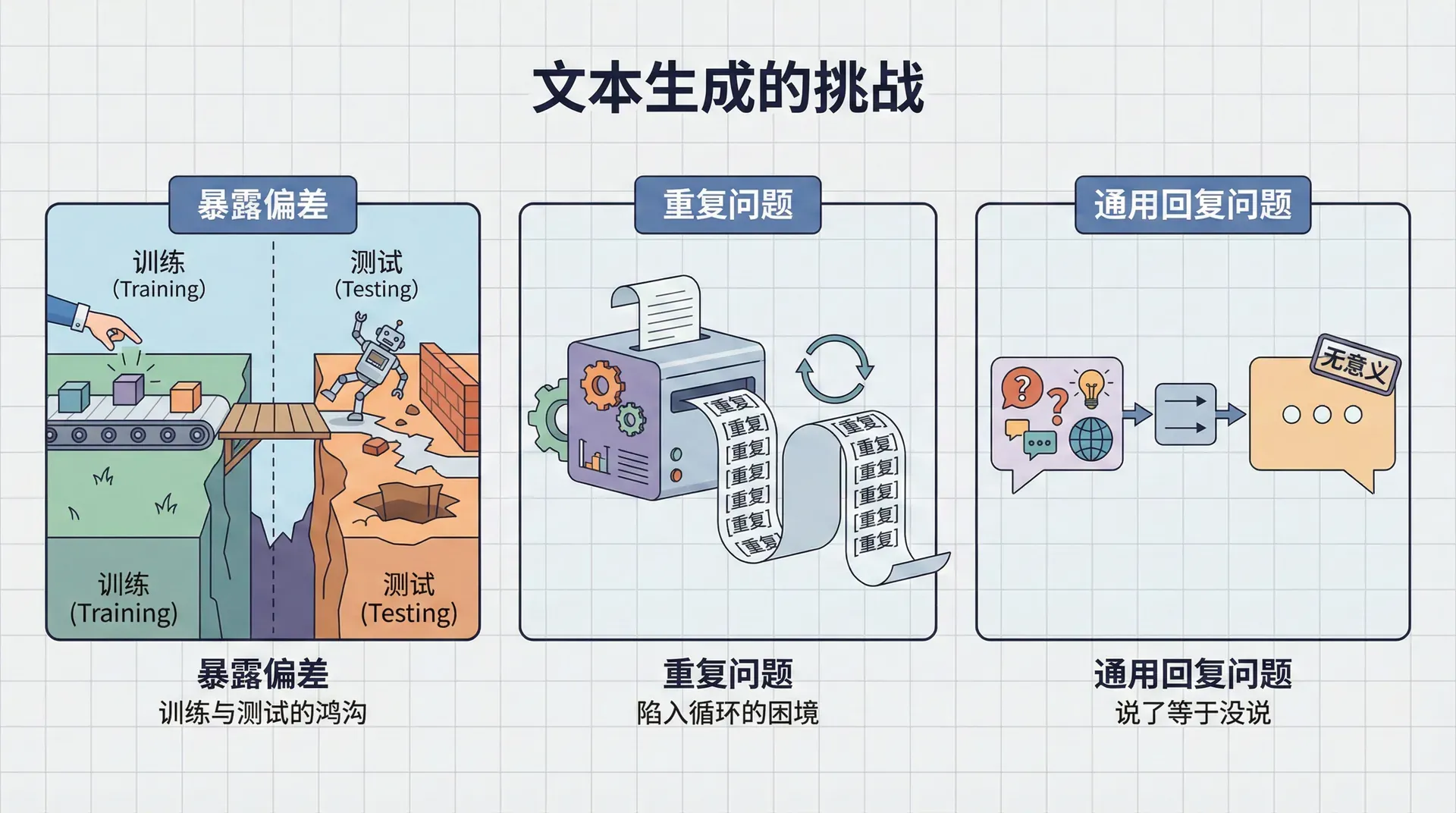
暴露偏差:训练与测试的鸿沟
文本生成模型训练时使用教师强制(Teacher Forcing):在预测第个词时,模型看到的前文是正确的参考序列。这加速了训练并使其稳定。
但在测试(生成)时,模型看到的是自己之前生成的词。如果早期生成了错误的词,后续的输入就与训练时看到的分布不同,模型可能不知道如何应对。这就是暴露偏差(Exposure Bias) 问题。
想象你训练一个人学开车,但总是在理想的路况下练习(平坦的路、完美的天气、没有其他车辆)。当他第一次在真实世界开车时(颠簸的路、下雨、拥挤的交通),可能会手足无措,因为从未见过这种情况。
暴露偏差的后果是模型的错误会累积。一个小错误导致输入分布偏移,使得下一步更容易出错,这又导致进一步偏移,最终生成的文本可能完全失控。这在长序列生成中尤为明显。
缓解方法
- Scheduled Sampling(计划采样)是一种折中方案:训练时,以某个概率使用模型自己的预测而非正确答案作为输入。随着训练进行,逐渐增加,让模型逐步适应自己的预测。这减轻了暴露偏差,但增加了训练的不稳定性。
- 强化学习是更激进的方法:将生成过程视为序列决策问题,用策略梯度直接优化最终的评估指标(如BLEU)。这完全消除了教师强制,但训练变得更困难、更慢、更不稳定。
重复问题:陷入循环的困境
重复是神经文本生成的顽疾。模型可能生成“I don't know. I don't know. I don't know.”或“the the the the”这样的退化输出。Holtzman等人(2019)将这种现象称为“神经文本退化(Neural Text Degeneration)”。
重复有多种表现形式:
- 词级重复:“the the the”
- 短语级重复:“thank you thank you thank you”
- 句子级重复:整个句子重复出现
重复的原因复杂:
从模型角度看,一旦某个词或短语被生成,它就成为上下文的一部分。如果这个词在当前上下文中概率本来就高,再次出现后,上下文进一步强化了它的概率,形成正反馈循环。这在最大化似然训练中是合理的——训练数据中确实存在重复现象(如强调),但模型学会了过度利用这个模式。
从解码角度看,贪婪解码和束搜索都倾向于重复。贪婪解码因为没有探索性,容易陷入局部最优模式。束搜索则更糟——不同的束往往会收敛到相似的前缀,因为它们都在追求高概率,而重复的模式通常概率较高。
缓解策略
- N-gram阻塞是简单有效的方法:在生成时,禁止生成已经出现过的n-gram。例如,3-gram阻塞会确保每个三词组合最多出现一次。这强制多样性,但可能过于生硬,有时合理的重复(如“New York, New York”)也会被禁止。
- Coverage机制(来自指针网络)让模型追踪已经关注过的源文本部分,惩罚重复关注同一位置。这在摘要任务中很有效,减少了重复提取相同信息。
- Unlikelihood训练(Welleck et al., 2020)是一种新方法:在训练时,不仅最大化正确词的概率,还最小化不想要的词(如刚刚生成的词)的概率。这直接在模型层面减少重复倾向。
- 采样方法(尤其是nucleus采样)天然地缓解了重复,因为随机性会"打破"重复循环。这也是为什么采样在开放式生成中通常优于束搜索。
通用回复问题:说了等于没说
在对话系统中,模型常常生成“I don't know”、“I'm not sure”、“OK”、“Thank you”这样的通用回复。这些回复在语法上正确,在大多数上下文中都适用,但缺乏信息量,让对话无法深入。
这个问题源于最大似然训练的固有偏见。训练数据中,通用回复出现频率很高——它们是“安全”的回应,适用于各种情况。模型学会了这个统计规律,倾向于生成高频但无聊的回复。
更深层的原因是目标函数的错位。最大似然最优化的是,但我们真正想要的可能是——给定回复,它传达了多少关于上下文的信息?通用回复在前者下概率高,在后者下概率低。
缓解方法
MMI解码(Maximum Mutual Information)尝试优化互信息:
其中是回复,是上下文。第二项惩罚了给定回复后上下文仍不确定的情况,从而惩罚通用回复。
多样性奖励在强化学习框架下,给予不同于已生成回复的新回复额外奖励,鼓励模型探索更多样的表达。
人格嵌入让模型学习特定的对话风格或人格,减少对通用回复的依赖。例如,一个幽默人格的模型会更倾向于开玩笑,而非说“I don't know”。
可控生成
随着GPT-3等大型语言模型的出现,一个新问题浮现:如何控制生成的内容?我们希望模型生成特定风格(正式/非正式、乐观/悲观)的文本,避免有害内容(仇恨言论、虚假信息),遵循特定约束(包含关键词、保持主题一致)。 这就是可控文本生成(Controlled Text Generation) 领域。
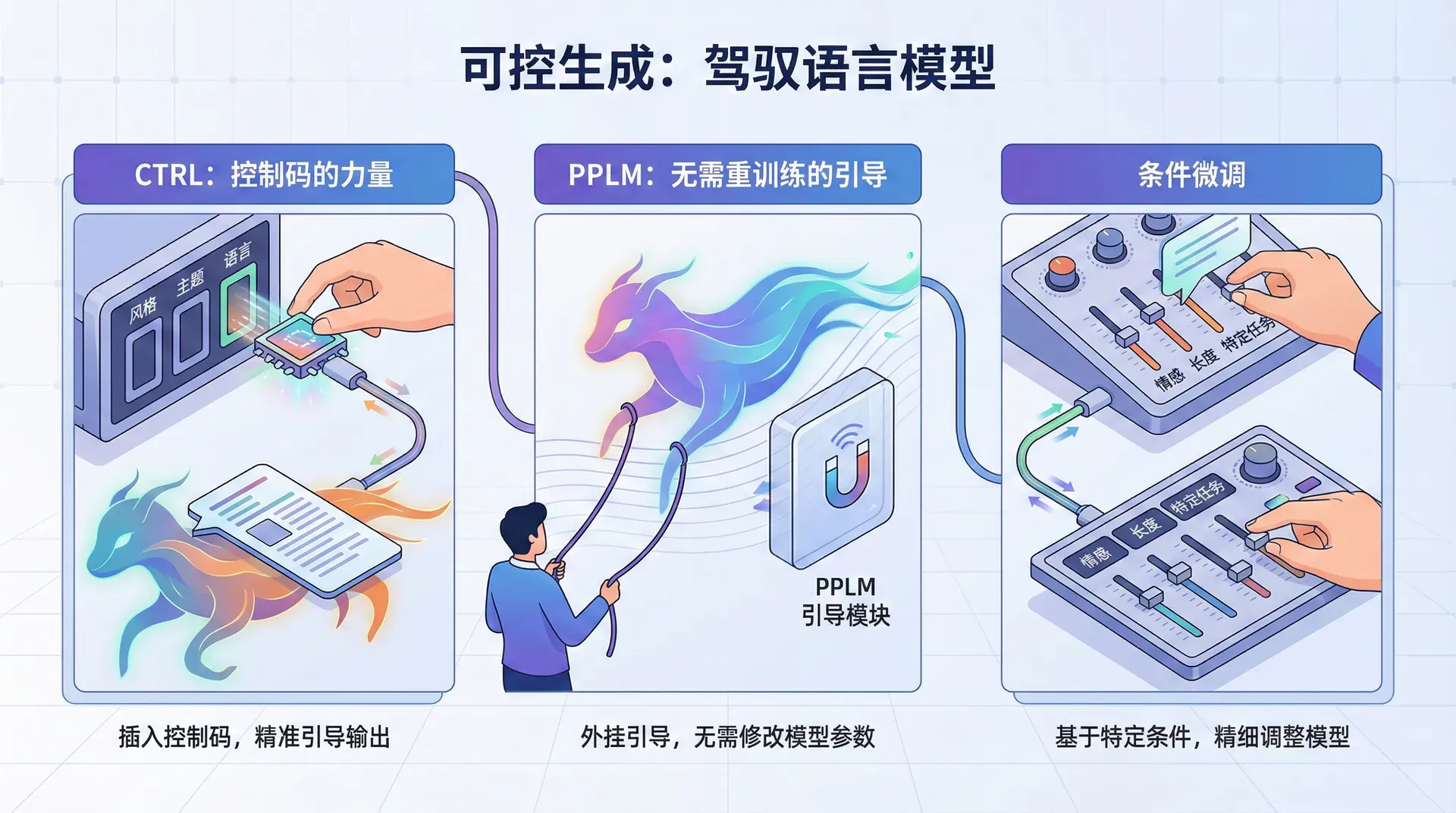
CTRL:控制码的力量
Salesforce在2019年提出的CTRL模型采用了一个简单而有效的想法:在训练时,为每个文本片段添加一个控制码,标识其来源或属性。例如:
text
<WIKIPEDIA> Albert Einstein was a German-born theoretical physicist...
<REDDIT> Today I learned that octopuses have three hearts...
<LEGAL> The party of the first part hereby agrees to...模型学会了将控制码与特定写作风格关联。生成时,用户可以通过指定控制码来引导生成:
text
<WIKIPEDIA> Quantum computing模型会生成Wikipedia风格的文本——正式、客观、信息丰富。
text
<REDDIT> Quantum computing模型会生成Reddit风格的文本——非正式、主观、可能带有幽默。
这种方法的优点是简单、可解释、灵活。缺点是需要重新训练模型,而且控制粒度有限(只能控制预定义的属性)。
PPLM
PPLM(Plug and Play Language Model)(Dathathri et al., 2020)提出了一个激进的想法:能否在不重新训练的情况下控制预训练模型的生成?
PPLM的做法是在生成过程中“扰动”模型的隐藏状态,让其朝着期望的方向移动。具体地:
- 正常前向传播,得到当前隐藏状态
- 定义一个属性分类器,评估隐藏状态是否具有期望属性
- 计算梯度,指示如何调整隐藏状态以增强属性
- 用梯度更新隐藏状态:
- 基于更新后的隐藏状态继续生成
这个“即插即用”的方法让我们可以用任何属性分类器(情感分类器、主题分类器等)来引导预训练模型,而无需重新训练。
条件微调
最直接的可控生成方法是条件微调:在特定风格或主题的数据上微调预训练模型。例如,要生成正式商务英语,就在商务邮件语料上微调GPT。
这种方法简单有效,但需要领域数据,而且可能导致灾难性遗忘——模型在新领域变好,但在原领域变差。
实践:构建文本生成器
理论理解后,让我们通过代码实现一个完整的文本生成器,集成多种解码策略:
python
import torch
import torch.nn.functional as F
class TextGenerator:
"""集成多种解码策略的文本生成器"""
def __init__(self, model, tokenizer, device='cuda'):
"""
Args:
model: 预训练的语言模型
tokenizer: 分词器
device: 运行设备
"""
self.model = model.to(device)
self.tokenizer = tokenizer
self.device = device
self.model.eval()
def generate_greedy(self, prompt, max_length=50):
"""贪婪解码"""
tokens = self.tokenizer.encode(prompt, return_tensors='pt').to(self.device)
for _ in range(max_length):
with torch.no_grad():
logits = self.model(tokens).logits[:, -1, :]
next_token = logits.argmax(dim=-1, keepdim=True)
if next_token.item() == self.tokenizer.eos_token_id:
break
tokens = torch.cat([tokens, next_token], dim=1)
return self.tokenizer.decode(tokens[0], skip_special_tokens=True)
def generate_beam_search(self, prompt, beam_size=5, max_length=50, length_penalty=0.6):
"""束搜索解码"""
initial_tokens = self.tokenizer.encode(prompt, return_tensors='pt').to(self.device)
# 初始化束:(序列张量, 累积对数概率)
beams = [(initial_tokens, 0.0)]
for _ in range(max_length):
candidates = []
for seq, score in beams:
# 如果已经生成结束符,保留此序列
if seq[0, -1].item() == self.tokenizer.eos_token_id:
candidates.append((seq, score))
continue
# 预测下一词
with torch.no_grad():
logits = self.model(seq).logits[:, -1, :]
log_probs = F.log_softmax(logits, dim=-1)
# 获取top-beam_size个候选
top_log_probs, top_indices = log_probs.topk(beam_size, dim=-1)
for log_prob, token_id in zip(top_log_probs[0], top_indices[0]):
new_seq = torch.cat([seq, token_id.unsqueeze(0).unsqueeze(0)], dim=1)
new_score = score + log_prob.item()
candidates.append((new_seq, new_score))
# 选择top-beam_size个最佳候选
# 应用长度归一化
candidates = sorted(candidates,
key=lambda x: x[1] / (x[0].size(1) ** length_penalty),
reverse=True)
beams = candidates[:beam_size]
# 返回最佳序列
best_seq = beams[0][0]
return self.tokenizer.decode(best_seq[0], skip_special_tokens=True)
def generate_nucleus(self, prompt, max_length=50, p=0.9, temperature=1.0):
"""Nucleus (top-p) 采样"""
tokens = self.tokenizer.encode(prompt, return_tensors='pt').to(self.device)
for _ in range(max_length):
with torch.no_grad():
logits = self.model(tokens).logits[:, -1, :] / temperature
probs = F.softmax(logits, dim=-1)
# 排序
sorted_probs, sorted_indices = torch.sort(probs, descending=True, dim=-1)
cumulative_probs = torch.cumsum(sorted_probs, dim=-1)
# 找到累积概率超过p的位置
sorted_indices_to_remove = cumulative_probs > p
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = 0
# 移除低概率词
indices_to_remove = sorted_indices[sorted_indices_to_remove]
probs[0, indices_to_remove] = 0
# 重新归一化并采样
probs = probs / probs.sum()
next_token = torch.multinomial(probs, 1)
if next_token.item() == self.tokenizer.eos_token_id:
break
tokens = torch.cat([tokens, next_token], dim=1)
return self.tokenizer.decode(tokens[0], skip_special_tokens=True)
def generate_top_k(self, prompt, max_length=50, k=40, temperature=1.0):
"""Top-k采样"""
tokens = self.tokenizer.encode(prompt, return_tensors='pt').to(self.device)
for _ in range(max_length):
with torch.no_grad():
logits = self.model(tokens).logits[:, -1, :] / temperature
# 只保留top-k个最高概率的词
top_k_logits, top_k_indices = torch.topk(logits, k, dim=-1)
# 创建一个全为-inf的张量,然后填入top-k的值
filtered_logits = torch.full_like(logits, float('-inf'))
filtered_logits[0, top_k_indices[0]] = top_k_logits[0]
# 计算概率并采样
probs = F.softmax(filtered_logits, dim=-1)
next_token = torch.multinomial(probs, 1)
if next_token.item() == self.tokenizer.eos_token_id:
break
tokens = torch.cat([tokens, next_token], dim=1)
return self.tokenizer.decode(tokens[0], skip_special_tokens=True)
# 使用示例
if __name__ == "__main__":
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# 加载预训练模型
model = GPT2LMHeadModel.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
generator = TextGenerator(model, tokenizer, device='cuda')
prompt = "Once upon a time, in a land far away,"
print("Greedy Decoding:")
print(generator.generate_greedy(prompt))
print("\nBeam Search:")
print(generator.generate_beam_search(prompt, beam_size=5))
print("\nNucleus Sampling:")
print(generator.generate_nucleus(prompt, p=0.9, temperature=0.8))
print("\nTop-k Sampling:")
print(generator.generate_top_k(prompt, k=40, temperature=0.8))这个实现展示了四种主要的解码策略,你可以在不同场景下比较它们的效果。通常会发现:贪婪和束搜索生成的文本更保守、重复更多;采样方法生成的文本更多样、更有创意,但偶尔可能不太连贯。
练习与思考
-
用一个具体例子说明贪婪解码的“短视”问题。构造一个场景,其中贪婪解码会选择当前概率最高但导致全局次优的路径。
-
束搜索的时间复杂度是多少?如果束大小为,序列长度为,词表大小为,每步需要多少计算?在什么情况下束搜索比贪婪解码快/慢?
-
Nucleus采样的参数如何影响生成质量?如果会怎样?如果会怎样?在什么任务中应该使用较小/较大的?
-
BLEU在什么情况下可能给出误导性的分数?举例说明一个BLEU高但质量差的翻译,以及一个BLEU低但质量好的翻译。
-
为什么束搜索在开放式文本生成中常常导致重复,但在机器翻译中效果不错?这两个任务有什么根本差异?
-
你要为一个新闻摘要系统选择解码策略。给定一篇文章,需要生成3-5句的摘要。你会选择哪种策略?为什么?需要调节哪些超参数?
-
现代语言模型(如ChatGPT)是如何避免传统解码策略的问题(如重复、通用回复)的?RLHF(基于人类反馈的强化学习)在其中起什么作用?