基于上下文的表征与NLP预训练模型
当我们在第一节课中学习Word2Vec和GloVe时,这些技术在2013-2015年被视为NLP的重大突破。它们让我们第一次能够用稠密向量表示词语的语义,并通过向量运算捕捉语义关系。 然而,随着研究的深入,一个根本性的问题逐渐浮出水面:静态词向量无法处理一词多义。
考虑英语单词bank这个经典例子。在句子I went to the bank to deposit money(我去银行存钱)中,bank指的是金融机构;而在The kids played by the river bank(孩子们在河岸边玩耍)中,bank指的是河岸。尽管这两个bank的含义完全不同,Word2Vec和GloVe却只能为它赋予同一个固定的向量表示。这就像给一个演员拍一张定妆照,然后无论他在不同电影中扮演什么角色,都用同一张照片来代表他——显然这是不合理的。
这个问题在中文中同样突出。他感冒了,需要打针和他在球场上打篮球中的打字,前者是医疗行为,后者是运动行为,但静态词向量无法区分。更微妙的例子是苹果公司发布新产品和我买了一个苹果——同一个苹果,在不同上下文中的含义截然不同。
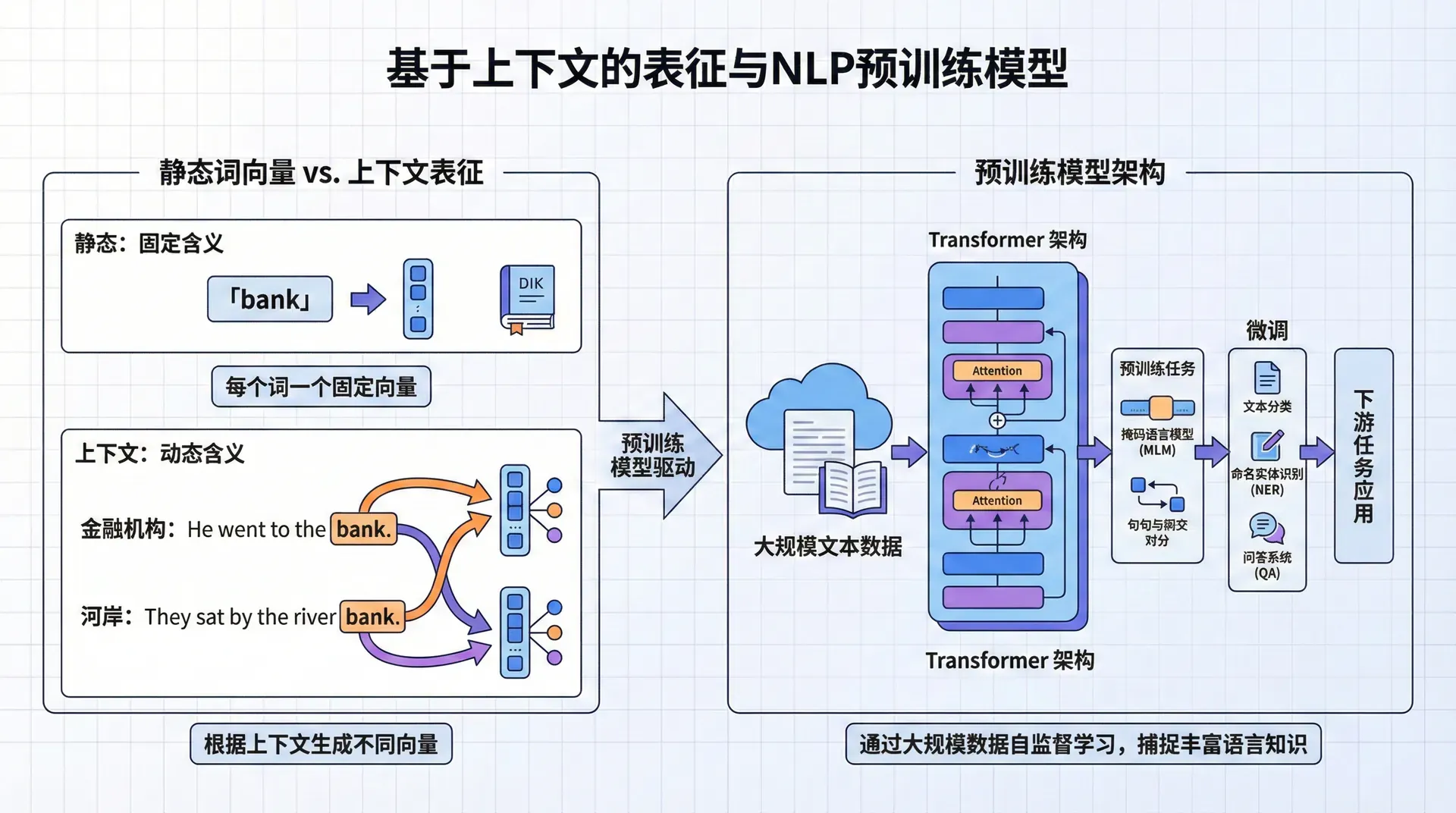
到了2017年,NLP社区意识到,如果我们希望机器真正理解语言,就必须让词的表示依赖于它所在的上下文。正是在这样的背景下,基于上下文的词表示(Contextualized Word Representations)应运而生,开启了NLP预训练模型的新纪元。
从TagLM到ELMo
TagLM
2017年,Matthew Peters等人(也就是后来ELMo的作者)在ACL会议上发表了一篇名为“Semi-supervised sequence tagging with bidirectional language models”的论文,提出了TagLM(Tagged Language Model)方法。这是一次重要的探索:他们意识到,与其从头训练任务特定的模型,不如利用预训练语言模型中蕴含的丰富语言知识。
TagLM的核心思想简单而有效:首先在大规模无标注文本上训练一个双向语言模型,然后将这个语言模型的隐藏状态作为额外特征,拼接到下游任务(如命名实体识别)的模型输入中。这就像给下游任务的模型配备了一个"语言顾问"——当模型需要理解一个词时,可以咨询这个预训练的语言模型对该词的理解。
TagLM在序列标注任务上取得了显著提升,但它还只是将预训练模型的最后一层表示作为特征使用。研究者们很快意识到,神经网络的不同层可能捕获了不同层次的语言信息,如果只用最后一层,可能错过了许多宝贵的信息。这个洞察催生了更强大的ELMo模型。
ELMo
2018年3月,Peters等人在NAACL会议上发表了题为“Deep Contextualized Word Representations”的论文,正式提出ELMo(Embeddings from Language Models)。这篇论文在NLP社区引起了轰动,因为它首次系统地证明了上下文相关的词表示能够在几乎所有NLP任务上带来显著提升。
ELMo的核心设计哲学在于三个关键洞察:
首先是双向性。人类在理解一个词时,会同时考虑它前面和后面的上下文。例如理解“银行”这个词,我们需要看它前面是“存款到”还是“河边的”,也需要看它后面是“账户”还是“岸边”。ELMo使用双向LSTM,分别从左到右和从右到左各训练一个语言模型,然后将两个方向的表示拼接起来。这样,“bank”在“deposit money to the bank”中获得的表示,会同时受到“deposit money to”和“account”的影响,从而正确地偏向金融含义。
其次是层次化表示。ELMo的一个重要发现是,LSTM的不同层捕获了不同层次的语言特征。通过大量实验和可视化分析,Peters等人发现:
- 底层(接近输入的层)更关注词法和句法特征,比如词性、句法结构
- 高层(接近输出的层)则编码更抽象的语义信息,比如语义角色、指代关系
这个发现意义深远,因为它表明神经网络确实在学习层次化的语言表示,这与语言学理论不谋而合。因此,ELMo不是只取最后一层,而是对所有层的表示进行加权组合:
其中 是第 层在位置 的隐藏状态, 是通过softmax归一化的权重参数, 是任务特定的缩放因子。这些权重是针对每个下游任务学习的,让模型自动决定每一层对当前任务的重要性。实验表明,不同任务确实会学到不同的层权重——句法任务更依赖底层,语义任务更依赖高层。
第三个关键设计是使用字符级卷积作为词表示的基础。传统词向量有一个固定的词表,遇到未见过的词(Out-of-Vocabulary, OOV)就束手无策。ELMo通过字符级CNN将词的字符序列编码为向量,这样即使遇到新词,也能根据其字符组成生成合理的表示。这对于处理形态丰富的语言(如德语、土耳其语)和处理拼写变体、新造词等特别有用。
ELMo的训练目标
ELMo使用的双向语言模型目标函数优雅而强大。对于一个包含 个词的句子 ,模型同时优化前向和后向语言建模的对数似然:
前向LSTM学习根据前文预测当前词,后向LSTM学习根据后文预测当前词。这个训练过程不需要任何人工标注,只需要大量的原始文本。Peters等人在包含8亿词的语料上训练ELMo,使其积累了丰富的语言知识。
有趣的是,前向和后向LSTM的参数是完全独立的,它们不共享任何权重。这与后来的BERT不同——BERT使用掩码语言模型,在单一模型中同时考虑双向上下文。ELMo的设计虽然参数量更多,但训练更简单,因为每个方向都是标准的单向语言模型。
如何使用ELMo
ELMo的使用方式非常灵活,这也是它广受欢迎的原因之一。对于任何下游NLP任务,你可以简单地:
- 将句子输入预训练的ELMo模型,获得每个词的上下文相关表示
- 将ELMo表示与任务模型的其他输入(如GloVe词向量)拼接
- 在下游任务的标注数据上训练或微调模型
AllenNLP团队(ELMo的开发者)提供了易用的Python接口:
python
from allennlp.modules.elmo import Elmo
# 加载预训练ELMo(需要下载权重文件)
elmo = Elmo(options_file, weight_file, num_output_representations=1)
# 对于输入句子,ELMo首先进行字符级编码
character_ids = batch_to_ids(sentences) # 将句子转换为字符ID
# 获取上下文表示
embeddings = elmo(character_ids)['elmo_representations'][0]
# embeddings的形状: (batch_size, sequence_length, embedding_dim)
# 将ELMo表示拼接到任务模型的输入
# 例如,与GloVe词向量拼接
word_embeddings = glove_embeddings(tokens) # 传统词向量
task_input
这种"即插即用"的特性使得ELMo可以轻松集成到现有的NLP系统中。更重要的是,ELMo表示通常被"冻结"——也就是说,在下游任务训练时,ELMo模型的参数保持固定,只训练层权重 和任务模型的参数。这大大减少了计算成本,同时保持了预训练知识的完整性。
ELMo带来的性能革命
ELMo的实验结果令人印象深刻。在2018年的六个NLP任务上,简单地加入ELMo表示就让当时的最佳模型获得了显著提升:
- 在问答系统(SQuAD)上,加入ELMo后错误率相对下降了约25%。原本模型可能因为无法正确理解问题中的关键词而失败,但ELMo提供的上下文表示帮助模型更准确地把握词义。例如,问题“What bank did John visit?”中的“bank”,ELMo会根据上下文(visit这个动词常与建筑物搭配)偏向金融机构的含义。
- 在命名实体识别任务上,F1分数提升了2-3个百分点。这看似不大,但在一个成熟的任务上,每0.5%的提升都需要大量的工程努力。ELMo的贡献主要体现在对罕见实体和歧义实体的识别上。例如,“Jordan”可能是人名(Michael Jordan)也可能是地名(约旦),ELMo的上下文表示能帮助模型区分。
- 在情感分析上的提升则揭示了另一个有趣的现象。情感往往依赖于词语的特定用法和上下文。例如“这部电影杀死了我”在电影评论中通常是正面评价(表示非常精彩),但字面含义是负面的。ELMo通过理解“杀死”在这个特定上下文中的非字面用法,帮助模型做出正确判断。
也许ELMo最令人兴奋的发现是其对数据效率的提升。实验表明,使用ELMo后,模型在只有10-20%标注数据的情况下,就能达到原先使用全部数据80-90%的性能。这对于标注成本高昂的任务(如生物医学文本挖掘)意义重大,它意味着预训练模型确实“学会”了通用的语言理解能力,而不只是记忆特定任务的模式。
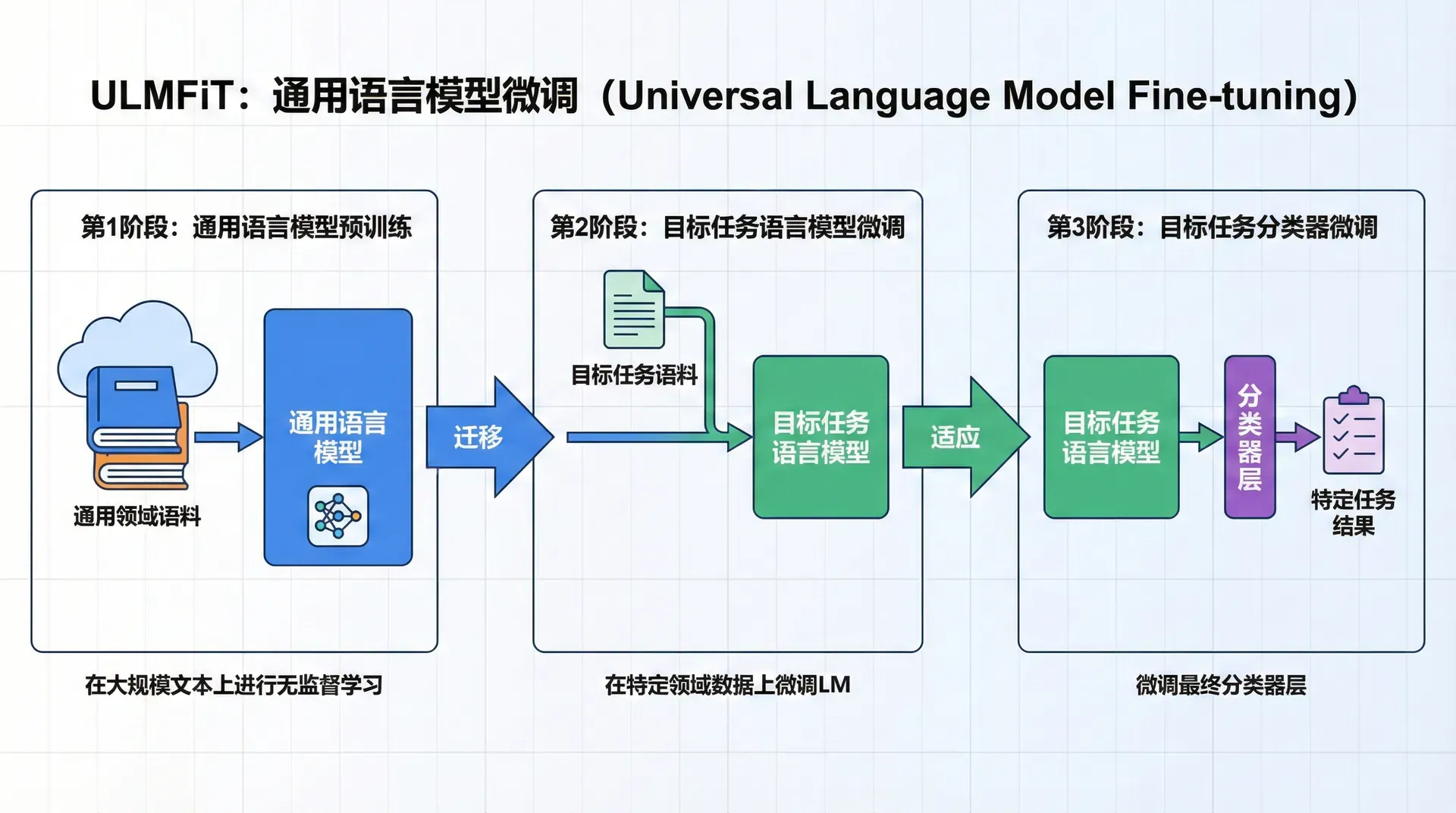
ULMFiT
就在ELMo发表的几个月前,2018年1月,Jeremy Howard和Sebastian Ruder在ACL会议上提出了ULMFiT(Universal Language Model Fine-tuning for Text Classification)。 虽然ULMFiT主要针对文本分类任务,但它的重要贡献在于系统化了NLP中的迁移学习流程,提出了一套完整的方法论。
计算机视觉的启发
ULMFiT的灵感来自计算机视觉领域的成功经验。在计算机视觉中,研究者早已习惯在ImageNet上预训练一个卷积神经网络,然后将其迁移到各种下游任务(物体检测、语义分割等)。这种"预训练-微调"范式极大地推动了视觉任务的发展,让人们可以用较少的标注数据训练出高性能模型。
然而,在2017年之前,NLP领域的迁移学习远不如视觉领域成功。虽然我们可以使用预训练的Word2Vec词向量,但这只是迁移了词级别的表示,而词向量之上的句子编码器、分类器等组件仍然需要从头训练。Howard和Ruder认为,我们需要迁移的不只是词的表示,而是整个语言模型——包括其对句子结构、语义组合、上下文依赖的理解。
三阶段训练流程
ULMFiT提出了一个清晰的三阶段训练范式,每个阶段都有其明确的目的:
阶段一:通用领域预训练。在这个阶段,我们在大规模通用语料(如Wikipedia的10亿词文本)上训练一个语言模型。ULMFiT使用的是AWD-LSTM(Average SGD Weight-Dropped LSTM),这是一个经过精心优化的LSTM变体,包含多种正则化技术。语言模型的任务很简单:给定前面的词,预测下一个词。虽然任务简单,但为了做好这个任务,模型必须学会语法、语义、常识等各种语言知识。
这个阶段的关键在于“通用性”。我们不针对任何特定领域或任务,而是让模型在尽可能多样化的文本上学习通用的语言理解能力。Wikipedia是理想的选择,因为它涵盖了科技、历史、文化、地理等各个领域的知识。
阶段二:目标任务领域适应。通用领域的语言模型已经具备了广泛的语言知识,但如果我们的目标任务是在特定领域(比如医疗文本或法律文档),那么领域之间的语言风格差异可能会影响性能。医疗文本充满了专业术语和特殊的表达方式,这些在Wikipedia中较少出现。
因此,ULMFiT的第二阶段是在目标领域的无标注数据上继续训练语言模型。这个过程被称为“领域适应”。例如,如果我们要做医疗文本分类,就在大量医疗文章(即使没有标注)上继续训练语言模型,让它熟悉医疗领域的语言特点。这个阶段不需要标注数据,因为语言模型的训练是自监督的。
阶段三:目标任务微调。最后,我们在目标任务的标注数据上微调模型。此时,我们需要为语言模型添加一个任务特定的输出层(如文本分类的分类层),然后在标注数据上训练整个模型。由于模型已经在前两个阶段学习了丰富的语言知识,这个阶段即使标注数据不多,也能取得很好的效果。
三大技术创新
ULMFiT不只是简单地串联三个训练阶段,Howard和Ruder还提出了几个关键的技术创新,使得迁移学习更加有效:
判别式微调(Discriminative Fine-tuning) 是第一个创新。传统的微调会对所有层使用相同的学习率,但ULMFiT认为这不合理。神经网络的不同层捕获了不同层次的特征:底层捕获通用的词法和句法特征,这些特征在不同任务间是共享的;高层捕获任务特定的语义特征。因此,在微调时,底层应该变化较小(使用较小的学习率),而高层可以变化较大(使用较大的学习率)。
具体地,ULMFiT对第 层使用不同的学习率 :
通常,学习率按层递减。如果最后一层的学习率是 ,那么第 层的学习率是 。这个设计让模型在微调时能够适应新任务,同时保留预训练阶段学到的通用知识。
逐层解冻(Gradual Unfreezing) 是第二个创新。在微调开始时,如果立即更新所有层的参数,可能会由于梯度过大而破坏预训练的知识(这被称为"灾难性遗忘")。ULMFiT采用了一个渐进的策略:首先只解冻并训练最后一层,等训练稳定后,再解冻倒数第二层,如此逐步向下。这种策略确保了微调过程的稳定性,让模型有时间逐步适应新任务。
倾斜三角学习率(Slanted Triangular Learning Rates, STLR) 是第三个创新。在微调阶段,ULMFiT使用了一个特殊的学习率调度策略:学习率先快速线性增加到某个峰值,然后缓慢线性衰减。增加阶段使模型能够快速适应新任务,而衰减阶段使模型能够收敛到更好的局部最优。这个策略在实践中被证明比常用的学习率衰减策略更有效。
ULMFiT的影响与局限
ULMFiT在文本分类任务上取得了出色的结果,在多个数据集上达到了当时的最佳性能,同时大幅减少了所需的标注数据量。更重要的是,ULMFiT提供了一个清晰的方法论,让研究者和工程师能够系统地应用迁移学习。
然而,ULMFiT也有其局限性。它主要针对文本分类任务设计,对于序列标注、问答等任务的效果不如ELMo。此外,ULMFiT使用的是单向LSTM语言模型,只能从左到右理解文本,这限制了它捕获双向上下文的能力。这些局限性在后来的BERT中得到了解决。
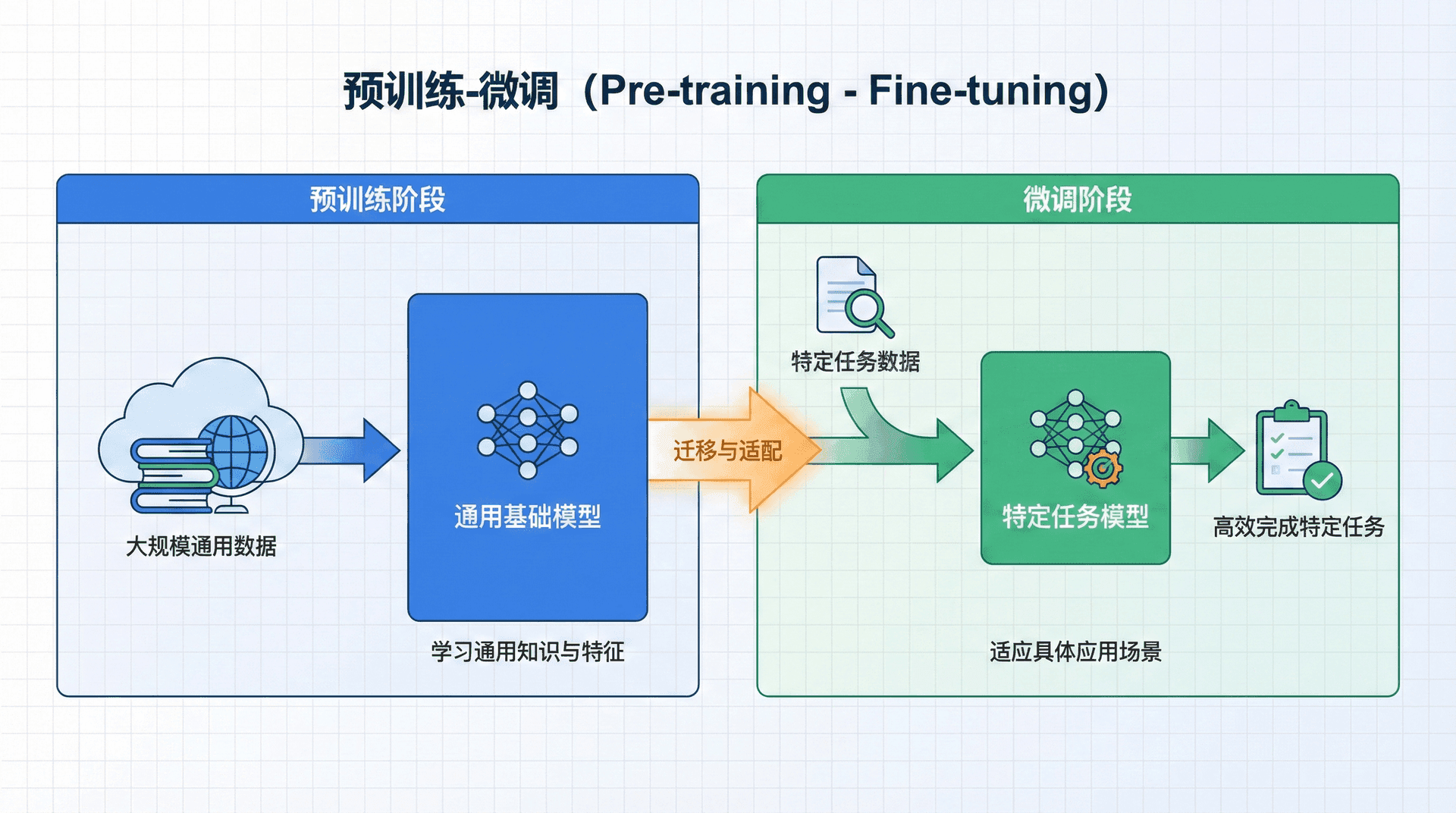
预训练-微调
ELMo和ULMFiT的成功标志着NLP进入了一个新时代。它们共同确立了预训练-微调(Pre-training and Fine-tuning) 范式,这个范式在接下来的几年中主导了NLP研究。
范式转变的本质
让我们回顾一下NLP方法论的演变历程。在深度学习之前,NLP系统主要依赖人工设计的特征和规则。深度学习的引入让我们可以端到端地学习特征表示,但每个任务仍然需要从头训练模型。Word2Vec的出现让我们可以复用预训练的词向量,但这只是迁移了最底层的词级表示。
预训练-微调范式代表了一个更彻底的转变:
传统方法:
text
随机初始化模型 → 在任务数据上训练 → 任务模型预训练-微调:
text
在大规模无标注数据上预训练 → 在任务数据上微调 → 任务模型这个转变看似简单,但其背后的哲学深刻。传统方法假设模型需要针对每个任务从零开始学习;预训练-微调范式则假设,存在一个通用的语言理解能力,可以在无标注数据上学习,然后针对特定任务进行适应。
为什么预训练有效?
预训练-微调范式的成功引发了一个深刻的问题:为什么在无标注数据上训练的语言模型能够帮助各种下游任务?这涉及到三个相互关联的机制:
更好的初始化是最直观的解释。神经网络的训练本质上是在一个高维参数空间中搜索最优解。如果我们从随机初始化开始,模型需要经过漫长的探索才能找到好的解。但如果我们从一个已经学到了语言知识的模型开始,就相当于从接近最优解的地方开始搜索,这大大加快了收敛速度并提高了最终性能。
想象你要在一个陌生城市找到一家餐厅。如果你从一个随机位置开始,可能需要走很长时间。但如果你从市中心(一个"好的初始位置")开始,就更容易找到目标。预训练模型就像这个市中心,它不是目标本身,但离目标更近。
正则化效应是第二个机制。在深度学习中,过拟合是一个常见问题,尤其是当标注数据有限时。预训练模型在大规模数据上学习的表示包含了丰富的先验知识,这相当于对模型施加了一个软约束:模型的参数不能偏离预训练参数太远。这种约束防止模型过度拟合任务数据中的噪声和偶然模式。
从贝叶斯的角度看,预训练提供了一个强先验分布。微调过程就是在这个先验和任务数据(似然)之间找到平衡,得到后验分布。当任务数据较少时,先验起主导作用,防止过拟合;当任务数据充足时,数据的信息占主导。
语言知识迁移是最深层的机制。语言模型的训练任务——预测下一个词——看似简单,实则要求模型理解语法、语义、常识等各方面的语言知识。为了预测"银行"后面的词,模型需要理解当前上下文中"银行"是指金融机构还是河岸,需要知道与金融机构搭配的词(账户、存款)和与河岸搭配的词(水流、岸边)有何不同。
这些在预训练中学到的知识,对于下游任务是有用的。命名实体识别需要理解词的类型和上下文;文本分类需要理解句子的语义;问答系统需要理解问题和文章之间的语义关系。这些能力在语言模型预训练中都有所体现,因此可以迁移到下游任务。
理论视角:通用语言表示假设
预训练-微调范式的成功支持了一个假设:存在一个通用的语言表示,它对各种NLP任务都有用。这个假设可以类比于计算机视觉中的观察:在ImageNet上学到的特征(如边缘、纹理、形状)对于各种视觉任务都有用。
然而,这个假设并非显而易见。语言比视觉更抽象、更灵活、更依赖于任务。一个表示对于情感分析有用,未必对句法分析有用。ELMo的层次化发现部分解答了这个疑问:不同的表示层次对不同任务有用,通过学习合适的加权,可以让一个预训练模型适应多个任务。
PyTorch实现:构建简化版ELMo
理解了ELMo的原理后,让我们通过代码来加深理解。下面的实现是ELMo的简化版,保留了核心思想但去除了一些工程细节。
双向语言模型
python
import torch
import torch.nn as nn
class BiLM(nn.Module):
"""双向语言模型(简化版ELMo的核心)"""
def __init__(self, vocab_size, embed_size, hidden_size, num_layers=2, dropout=0.5):
"""
Args:
vocab_size: 词表大小
embed_size: 词嵌入维度
hidden_size: LSTM隐藏层维度
num_layers: LSTM层数
dropout: Dropout概率
"""
super().
ELMo嵌入层
python
class ELMoEmbedding(nn.Module):
"""ELMo式的上下文嵌入层"""
def __init__(self, bilm_model, num_layers):
"""
Args:
bilm_model: 预训练的双向语言模型
num_layers: 要组合的层数
"""
super().__init__()
self.bilm = bilm_model
self.num_layers = num_layers
# 可学习的层权重(针对每个任务学习)
self.layer_weights
这个实现展示了ELMo的核心思想:通过双向语言模型学习上下文相关的表示,然后将不同层的表示加权组合用于下游任务。虽然简化了很多细节(如字符级编码、多层表示的完整提取等),但核心机制是完整的。
预训练模型的影响
性能提升的量化分析
ELMo和ULMFiT在2018年的出现,引发了NLP领域的一场性能竞赛。在几个月内,各大NLP任务的排行榜被刷新。让我们看一些具体数字:
- 在SQuAD问答任务上,加入ELMo使得当时最佳模型(BiDAF++)的F1分数从81.1提升到85.8,错误率相对下降约25%。这意味着模型能够更准确地从文章中定位答案,尤其是在问题包含多义词的情况下。
- 在命名实体识别(CoNLL 2003数据集)上,ELMo使F1分数从90.94提升到92.22,提升了1.28个百分点。虽然看似不大,但在一个已经非常成熟的任务上,这样的提升相当于节省了数年的研究努力。
- 在情感分类(SST-5)上,ELMo使准确率从53.7%提升到54.7%。情感分类是一个主观性很强的任务,准确率本身不高,但ELMo仍然能带来改进,说明上下文表示确实帮助模型理解了情感的微妙之处。
最令人印象深刻的是在文本蕴含(SNLI)任务上,准确率从88.0%提升到88.7%。文本蕴含需要深入理解两个句子之间的逻辑关系,ELMo的改进表明它捕获了深层的语义信息。
数据效率的革命性提升
也许预训练模型更重要的贡献是对数据效率的提升。多项研究表明,使用ELMo或ULMFiT后,模型在只有10-20%标注数据的情况下,就能达到原先使用全部数据80-90%的性能。
这对实际应用意义重大。在许多垂直领域(如生物医学、法律、金融),标注数据的获取成本极高,需要领域专家花费大量时间。预训练模型让我们可以用少得多的标注数据达到实用性能,大大降低了NLP技术的应用门槛。
想象你要为一家医院开发病历分析系统。如果没有预训练,你可能需要数万份标注的病历才能训练出可用的模型,这可能需要医生花费数千小时。但有了预训练模型,也许只需要几千份,甚至几百份标注病历就能达到相似的性能。这可能是可行与不可行之间的差别。
迈向BERT的铺垫
ELMo和ULMFiT为2018年底BERT的横空出世铺平了道路。它们证明了预训练-微调范式的有效性,也暴露了一些可以改进的地方:
ELMo的前向和后向LSTM是独立的,它们虽然都看到了全部上下文,但没有在同一个模型中进行深度交互。BERT通过掩码语言模型(Masked Language Model)解决了这个问题,让模型在单一架构中同时考虑双向上下文。
ULMFiT提出了完整的微调方法论,但它使用的LSTM架构在长文本和并行计算上有局限。BERT采用Transformer架构,完全解决了这些问题。
ELMo为每个词生成固定长度的向量,但没有显式建模词与词之间的关系。BERT的自注意力机制让模型能够显式地学习任意两个词之间的关联。
站在2018年的时间点,我们可以说ELMo和ULMFiT开启了预训练时代,而它们暴露的局限性为后续的创新指明了方向。在接下来的一节课中,我们将看到这些思想如何在Transformer和BERT中得到综合和升华。
练习与思考
-
用一个具体的例子(可以自己构造)解释为什么上下文相关的词表示比静态词向量更好。你的例子应该展示静态词向量会失败而上下文表示会成功的场景。
-
ELMo使用字符级CNN作为输入,而不是直接使用词嵌入。这样做有什么优势?在什么情况下这个优势特别明显?
-
ELMo论文发现,不同层的表示对不同任务有不同的有用性(底层对句法任务更有用,高层对语义任务更有用)。为什么会出现这种现象?这个现象对我们设计和使用预训练模型有什么启示?
-
ULMFiT提出了判别式微调、逐层解冻、倾斜三角学习率三个技术。如果你要在一个新的领域(如法律文本)应用预训练模型,你会如何使用这些技术?哪个技术最重要?
-
预训练-微调范式假设存在通用的语言理解能力。但不同任务对语言的需求很不同(比如情感分析关注情感词,命名实体识别关注实体边界)。为什么一个在语言模型上预训练的模型能够同时帮助这些不同的任务?这个假设在什么情况下可能失效?
-
如果你有一个标注数据很少(只有100个样本)的文本分类任务,你会选择使用ELMo特征还是从头训练?为什么?你会如何评估预训练模型是否真的有帮助?
-
这节课我们介绍了2018年左右的技术。现在我们已经有了BERT、GPT-3等更强大的模型。回顾ELMo和ULMFiT,你认为它们的哪些思想在当前仍然重要?哪些已经被后续技术超越?