MongoDB副本集
在现代数据库应用中,数据的安全性和可用性至关重要。如果我们的网店数据库服务器在双十一当天突然宕机,这会造成多大的损失?这就是为什么我们需要学习MongoDB副本集这个高可用性解决方案。
MongoDB副本集本质上是一个智能的数据备份和故障恢复系统。它通过在多台服务器上保存相同数据的副本,确保即使某台服务器出现问题,我们的应用仍然可以正常运行。 在传统的单机模式下,我们只有一个mongod服务器在工作。这种方式虽然简单,但在生产环境中存在很大风险。如果服务器崩溃、硬件故障或网络问题导致数据损坏,我们可能面临数据丢失的灾难。
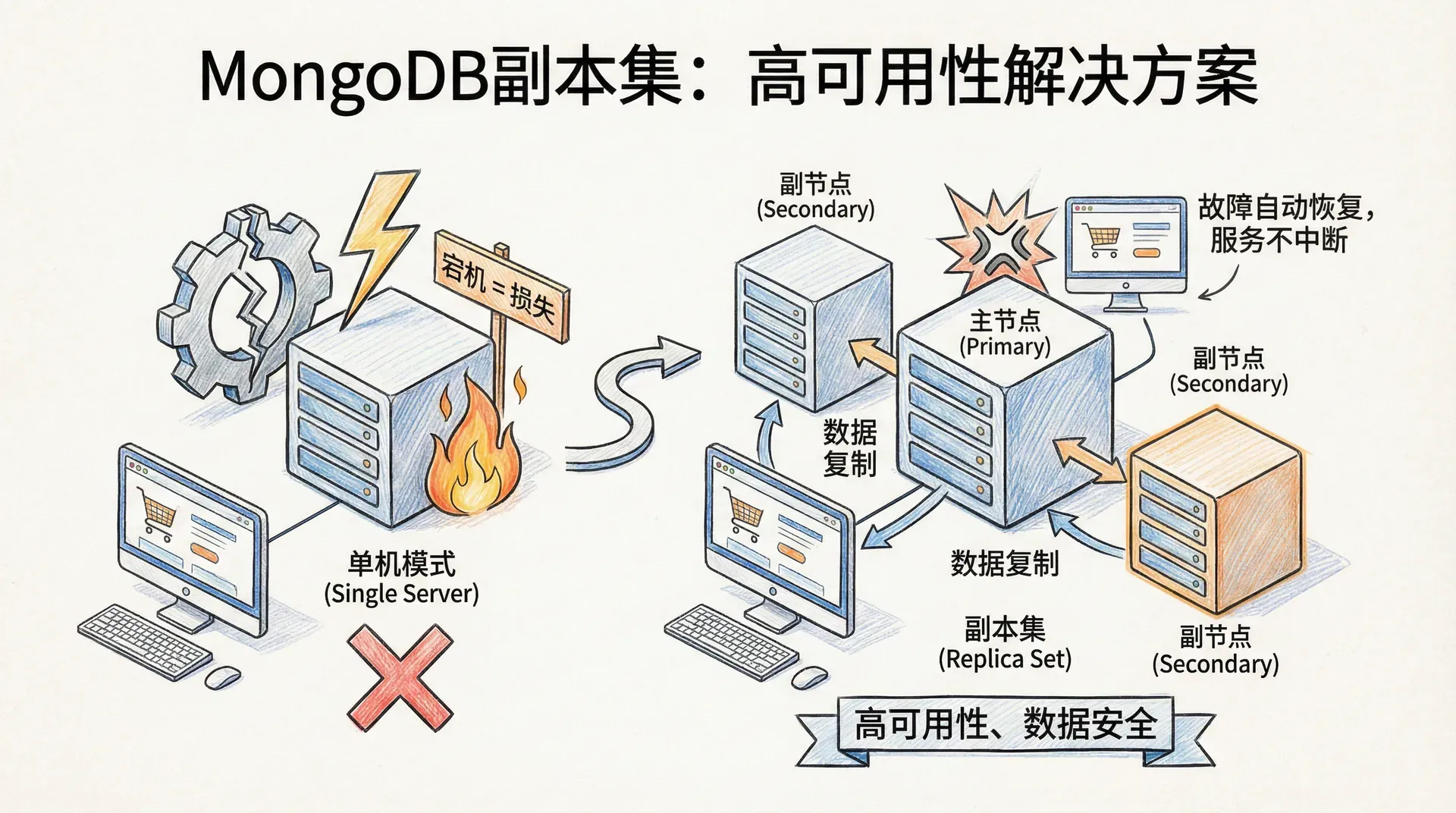
副本集通过创建一个服务器组来解决这个问题。在这个组中,有一个「主节点」(Primary)负责处理所有的写入操作,还有多个「从节点」(Secondary)持续同步主节点的数据。当主节点出现故障时,从节点会自动选举出新的主节点,整个过程对应用程序是透明的。
在生产环境中,我们可以使用MongoDB Atlas云服务或Ops Manager来管理副本集,这样可以简化部署和维护工作,让我们专注于业务逻辑的开发。
准备实验环境
为了更好地理解副本集的工作原理,我们接下来会在本地搭建一个三节点的副本集进行实验。这种实验环境可以帮助我们深入了解副本集的运行机制,包括故障转移、数据同步等关键特性。 虽然我们的实验是在单台机器上运行多个MongoDB实例,但在实际生产环境中,每个副本集成员都应该部署在独立的服务器上,以避免资源竞争和单点故障。
我们需要为每个MongoDB实例创建独立的数据目录。在Linux或macOS系统中,可以使用以下命令创建三个目录:
shell
$ mkdir -p ~/data/rs{1,2,3}这个命令会创建三个目录:~/data/rs1、~/data/rs2和~/data/rs3,分别用于存储三个MongoDB实例的数据。
在Windows系统中,需要使用不同的命令:
shell
> md c:\data\rs1 c:\data\rs2 c:\data\rs3数据目录创建完成后,我们就可以开始启动MongoDB实例了。每个实例需要使用不同的端口和数据目录,这样它们就可以在同一台机器上并行运行而不会产生冲突。 现在我们来启动三个MongoDB实例,它们将构成我们的副本集。每个实例都需要指定一些关键参数来确保它们能正确协作。
在Linux或macOS系统中,我们需要在三个不同的终端窗口中分别运行以下命令:
第一个MongoDB实例:
shell
$ mongod --replSet mdbGuide --dbpath ~/data/rs1 --port 27017 --smallfiles --oplogSize 200第二个MongoDB实例:
shell
$ mongod --replSet mdbGuide --dbpath ~/data/rs2 --port 27018 --smallfiles --oplogSize 200第三个MongoDB实例:
shell
$ mongod --replSet mdbGuide --dbpath ~/data/rs3 --port 27019 --smallfiles --oplogSize 200在Windows系统中,命令基本相同,只是数据路径需要调整:
shell
> mongod --replSet mdbGuide --dbpath c:\data\rs1 --port 27017 --smallfiles --oplogSize 200
> mongod --replSet mdbGuide --dbpath c:\data\rs2 --port 27018 --smallfiles --oplogSize 200
> mongod --replSet mdbGuide --dbpath c:\data\rs3 --port 27019 --smallfiles --oplogSize 200让我们详细解释一下这些启动参数的含义:
在生产环境中,请务必为每个副本集成员分配独立的服务器,避免在同一台机器上运行多个实例。因为如果一个服务器宕机,那么整个副本集将无法正常工作,而我们创建副本集的目的就是为了保证数据的安全性和可用性。
当三个实例都启动成功后,你会看到每个终端窗口都显示MongoDB的启动日志。此时,虽然三个MongoDB实例都在运行,但它们还没有形成副本集,需要我们进行进一步的配置才能让它们协作工作。
网络配置
在我们的实验环境中,所有MongoDB实例都运行在同一台机器上,网络配置相对简单。但在实际的生产部署中,网络配置是一个需要特别注意的关键问题。
网络连通性要求:副本集中的每个成员都必须能够与其他所有成员建立网络连接,包括与自己的连接。如果你在设置过程中遇到成员无法相互通信的错误,很可能是网络配置问题导致的。
从MongoDB 3.6版本开始,mongod进程默认只绑定到本地回环地址(127.0.0.1),这是一个重要的安全改进。如果副本集成员需要部署在不同的服务器上,我们必须明确指定可以被其他成员访问的IP地址。
假设我们有一台服务器的IP地址是192.168.1.100,并且我们希望它作为副本集的一个成员,那么启动命令应该包含--bind_ip参数:
shell
$ mongod --bind_ip localhost,192.168.1.100 --replSet mdbGuide --dbpath ~/data/rs1 --port 27017 --smallfiles --oplogSize 200这个配置告诉MongoDB同时监听本地回环地址和指定的网络接口,这样其他副本集成员就可以通过网络IP地址连接到这个实例。
在配置网络绑定时,建议同时保留localhost绑定,这样本地的管理工具和脚本仍然可以正常连接到数据库实例。
在配置网络访问前,需优先充分评估和落实数据库的安全防护措施。MongoDB实例一旦绑定至公网IP,便可能暴露在外部网络环境,从而面临诸多安全威胁。
- 身份认证机制:生产环境下必须启用MongoDB的用户认证(Authentication),确保仅有具备合法凭据的客户端可以访问数据库资源。这是抵御未经授权访问的基础措施。
- 数据传输加密:副本集各成员节点之间会同步数据、交换心跳信号等,在生产应用中建议强制开启TLS/SSL,对所有节点间网络通信进行加密,有效防止数据在传输过程中遭受中间人攻击或被非法窃取。
- 存储加密:除了传输层加密,同样应当启用存储层加密(如MongoDB的加密存储引擎),对落地到磁盘的数据进行加密保护,以防止数据因物理介质泄露、丢失等风险而被非法获取。
上述安全配置超出了我们这节课的范畴,但在将副本集应用于生产环境前,务必对认证、加密等关键安全措施作充分评估与严格落实!
初始化副本集
现在我们的三个MongoDB实例已经在运行,但它们还不知道彼此的存在。接下来我们需要创建一个配置文档来告诉它们如何协作,并将这个配置发送给其中一个实例,让它负责将配置传播给其他成员。
首先,我们需要启动mongo shell并连接到其中一个MongoDB实例。打开一个新的终端窗口,使用以下命令连接到运行在27017端口的实例:
shell
$ mongo --port 27017连接成功后,我们会进入MongoDB的交互式shell环境。现在需要创建一个副本集配置文档,这个文档定义了副本集的结构和成员信息。 在mongo shell中输入以下配置:
javascript
> rsconf = {
_id: "mdbGuide",
members: [
{_id: 0, host: "localhost:27017"},
{_id: 1, host: "localhost:27018"},
{_id: 2, host: "localhost:27019"}
]
}该配置文档各字段含义如下:
- _id: "mdbGuide":副本集名称。此字段必须与所有成员启动时指定的
--replSet参数严格一致,是副本集全局唯一的标识。该名称用于实现成员间身份确认与集群归属校验,确保仅相同标识的mongod实例能够组成同一副本集。 - members数组:成员列表。该数组声明了副本集内所有成员的详细信息,每一项为一个节点配置对象,需至少包含以下核心字段:
- _id:成员ID。该值在副本集内必须为唯一的非负整数,主要用于集群内部对成员节点进行快速索引和选举管理。
- host:成员主机地址。采用
主机名:端口号的规范格式(如"localhost:27017"),用于定位和连接具体实例。所有参与节点的host信息应能够保证网络互通性。
如需哪天更高阶的配置,可扩展上述成员对象,增加如priority优先级、arbiterOnly仲裁角色等高级参数,实现更灵活的集群行为控制。
在我们的实验中使用localhost作为主机名是可以的,但MongoDB不允许在同一个副本集中混合使用localhost和其他主机名。在生产环境中,我们应该使用实际的服务器主机名或IP地址。
配置文档创建完成后,我们使用rs.initiate()命令来初始化副本集:
javascript
> rs.initiate(rsconf)
{ "ok" : 1, "operationTime" : Timestamp(1234567890, 1) }如果命令执行成功,会返回一个包含「ok: 1」的响应。此时,连接到27017端口的MongoDB实例会解析这个配置,并向其他成员发送消息,通知它们新的副本集配置。 所有成员加载配置后,它们会开始选举过程来确定哪个成员成为主节点。这个过程通常在几秒钟内完成,之后副本集就可以开始处理读写操作了。
你可以使用rs.status()命令来查看副本集的当前状态:
javascript
> rs.status()这个命令会返回详细的状态信息,包括每个成员的角色(主节点或从节点)、同步状态、以及各种时间戳。在输出中,你会看到其中一个成员的「stateStr」字段显示为「PRIMARY」,其他成员显示为「SECONDARY」。
如果你看到shell提示符变成了类似「mdbGuide:PRIMARY>」的形式,说明副本集初始化成功,并且你当前连接的实例已经成为主节点。
副本集辅助函数
MongoDB提供了一系列以「rs」开头的辅助函数来简化副本集管理。这些函数实际上是对底层数据库命令的封装,让我们能够更方便地操作副本集。
例如,rs.initiate(config)函数等价于以下数据库命令:
javascript
> db.adminCommand({"replSetInitiate" : config})了解这些底层命令很有用,因为在某些情况下,直接使用命令可能比使用辅助函数更灵活。你可以使用rs.help()来查看所有可用的副本集辅助函数。
当副本集成功初始化后,你就拥有了一个完全功能的高可用性数据库集群。即使其中一台服务器出现故障,剩余的服务器也能够继续提供服务,确保应用程序的持续运行。
现在让我们通过实际操作来观察副本集是如何工作的。如果你的shell提示符显示当前连接的是主节点,我们就可以开始进行写入操作了。如果不是,请退出shell并连接到主节点。 首先,让我们向主节点写入一些测试数据:
javascript
> use test
> for (i = 0; i < 1000; i++) {
db.products.insert({productId: i, name: "商品" + i, price: Math.random() * 1000})
}这个循环会在test数据库的products集合中插入1000个商品文档。我们可以验证数据是否成功写入:
javascript
> db.products.count()
1000现在让我们来验证这些数据是否已经自动复制到从节点。我们需要连接到其中一个从节点来检查。在当前的shell中,我们可以创建一个到从节点的新连接,这里我们选择连接到27018端口:
javascript
> secondaryConn = new Mongo("localhost:27018")
> secondaryDB = secondaryConn.getDB("test")现在尝试从从节点读取数据:
javascript
> secondaryDB.products.find()执行上述命令后,您可能会遇到如下错误信息:「not master and slaveOk=false」。这是MongoDB设计中的一项关键安全机制,用于防止客户端默认从可能存在数据延迟的从节点读取数据。
为何从节点默认拒绝读取请求?
因为在分布式系统中,从节点的数据同步存在一定延迟,尤其在网络波动或主节点写入压力较大时更为明显。如果应用未明确指定容忍延迟而直接从从节点读取,可能导致读取到未经最新同步的数据,影响数据一致性,进而产生潜在业务风险。 因此,MongoDB强制要求用户明确授权从节点可被读取,即只有在设置了slaveOk标志后,才允许从节点响应读请求。
如需在从节点上执行查询操作,我们则需要手动设置slaveOk标志:
javascript
> secondaryConn.setSlaveOk()注意这个设置是针对连接(secondaryConn)而不是数据库(secondaryDB)的。现在我们就可以正常查询从节点了:
javascript
> secondaryDB.products.find().limit(5)
{ "_id" : ObjectId("..."), "productId" : 0, "name" : "商品0", "price" : 123.45 }
{ "_id" : ObjectId("..."), "productId" : 1, "name" : "商品1", "price" : 678.90 }
...太好了!现在我们可以看到数据已经成功复制到从节点。让我们来验证数据数量是否一致:
javascript
> secondaryDB.products.count()
1000副本集的数据同步是自动且持续进行的。当我们在主节点写入数据时,这些变更会通过操作日志(oplog)快速传播到所有从节点。
现在让我们来尝试向从节点写入数据,看看会发生什么:
javascript
> secondaryDB.products.insert({productId: 1001, name: "测试商品", price: 999})
WriteResult({ "writeError" : { "code" : 10107, "errmsg" : "not master" } })正如预期的那样,从节点拒绝了写入操作。这个限制确保了数据的一致性,所有的写入操作都必须通过主节点进行,然后再同步到从节点。
故障转移
副本集具备高可用性的关键机制之一是自动故障转移。当现有主节点发生异常或失联时,剩余的从节点会通过选举流程自动推举出新的主节点,以保障整体服务的可用性和数据一致性。下面我们来演示一遍这个过程。
首先我们可以通过执行 db.isMaster() 命令,实时查看当前副本集的主节点与成员状态:
javascript
> db.isMaster()
{
"hosts" : [
"localhost:27017",
"localhost:27018",
"localhost:27019"
],
"setName" : "mdbGuide",
"ismaster" : true,
"primary" : "localhost:27017",
"me" : "localhost:27017",
...
}假设当前主节点是localhost:27017,我们现在模拟这个节点的故障。在连接到主节点的shell中执行 db.adminCommand({"shutdown" : 1}) 命令,该命令会关闭主节点:
javascript
> db.adminCommand({"shutdown" : 1})执行这个命令后,主节点会关闭,你会看到shell连接中断的错误信息。不用担心,这是正常现象。 现在让我们观察故障转移过程。使用之前创建的从节点连接来检查副本集状态:
javascript
> secondaryDB.isMaster()你可能需要等待几秒钟,然后重复执行这个命令。很快你会看到输出中的「primary」字段指向了一个新的节点(比如localhost:27018),这表明选举过程已经完成,新的主节点已经产生。
在实际应用中,客户端驱动程序会自动检测主节点变更并重新连接到新的主节点,整个过程对应用程序基本透明。
现在我们可以重新启动之前关闭的MongoDB实例。找到运行27017端口实例的终端窗口,使用相同的启动命令重新启动它:
shell
$ mongod --replSet mdbGuide --dbpath ~/data/rs1 --port 27017 --smallfiles --oplogSize 200这个实例重新启动后,会自动作为从节点加入副本集,并开始同步在其离线期间错过的数据变更。 通过这个演示,我们看到了副本集如何在几秒钟内自动处理节点故障,确保数据库服务的持续可用性。这种自动故障转移能力是副本集在生产环境中如此重要的原因。
动态配置
副本集支持在不中断服务的情况下动态调整配置,包括添加、移除或修改成员,极大地提升了系统在生产环境中的可维护性与扩展性。
添加新成员
当业务发展需要提升系统的读性能或增强高可用性时,可以通过rs.add()方法向副本集添加新的成员:
javascript
> rs.add("localhost:27020")这个命令会将运行在27020端口的MongoDB实例添加到副本集中。当然,你需要确保这个实例已经启动并使用相同的副本集名称。 新成员加入后,它会自动开始从其他成员同步数据。这个过程叫做「初始同步」,这个过程通常需要一些时间,具体取决于数据量的大小。
移除成员
如果某个成员不再需要或需要进行维护,我们可以使用rs.remove()函数将其从副本集中移除:
javascript
> rs.remove("localhost:27017")
{ "ok" : 1, "operationTime" : Timestamp(1234567890, 2) }移除成员是一个不可逆的操作,被移除的成员将停止接收数据同步。在生产环境中执行此操作前,请确保你真的不再需要这个成员在进行移除的操作。
查看和修改配置
如果你想查看当前的副本集配置,可以通过执行 rs.config() 命令以查询当前副本集的详细配置信息:
javascript
> rs.config()
{
"_id" : "mdbGuide",
"version" : 3,
"protocolVersion" : NumberLong(1),
"members" : [
{
"_id" : 1,
"host" : "localhost:27018",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {},
"slaveDelay" : NumberLong(0),
"votes" : 1
},
{
"_id" : 2,
"host" : "localhost:27019",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {},
"slaveDelay" : NumberLong(0),
"votes" : 1
},
{
"_id" : 3,
"host" : "localhost:27020",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {},
"slaveDelay" : NumberLong(0),
"votes" : 1
}
],
"settings" : {
"chainingAllowed" : true,
"heartbeatIntervalMillis" : 2000,
"heartbeatTimeoutSecs" : 10,
"electionTimeoutMillis" : 10000,
"catchUpTimeoutMillis" : -1,
"getLastErrorModes" : {},
"getLastErrorDefaults" : {
"w" : 1,
"wtimeout" : 0
},
"replicaSetId" : ObjectId("...")
}
}注意配置中的「version」字段,它在每次配置变更时都会递增。这个版本号帮助副本集成员跟踪配置变更的历史。
高级配置修改
对于更复杂的配置修改,我们可以直接编辑配置文档并使用rs.reconfig()函数应用变更。
比如,假设我们想要修正一个成员的主机名(在实际场景中,这可能是因为服务器迁移或DNS变更):
javascript
> var config = rs.config()
> config.members[0].host = "newserver.example.com:27017"
> rs.reconfig(config)这种方法可以用于任何复杂的配置变更,比如同时添加多个成员、修改成员属性等。rs.reconfig()函数比单独使用rs.add()和rs.remove()更加强大和灵活,因为它可以用于任何合法的配置变更。
在进行配置变更时,系统会自动验证新配置的有效性。如果配置有问题(比如重复的成员ID或无效的主机名),变更会被拒绝。如果配置没有问题,变更则会被应用。
副本集设计原则
多数决策机制
MongoDB副本集采用多数决策原则来保证数据一致性和系统可靠性。无论是主节点(Primary)的选举、主节点的存续,还是写操作的“多数确认”,均要求超过半数成员的同意。只有在获得集群多数成员认可的前提下,相关操作才会被视为成功,从而有效防止脑裂等分布式系统常见问题。
下表展示了不同规模副本集的多数要求:
这个多数是基于副本集配置中的总成员数计算的,不管有多少成员当前不可用。
为什么需要多数决策?
让我们通过一个具体场景来理解这个设计的重要性。假设我们有一个5成员的副本集,其中3个成员突然失去连接(宕机):
在这种情况下,剩余的2个成员无法达到多数要求(至少需要3个),因此它们无法选举出主节点。这看起来可能令人沮丧,但实际上这是一个非常明智的设计,因为如果允许少数派选举主节点,就会出现灾难性的「脑裂」现象:两个分区都有自己的主节点,都在接受写入操作,导致数据不一致,进而产生潜在业务风险。
网络分区的挑战
考虑另一种可能的情况:也许那3个成员并没有真正宕机,而是由于网络故障导致了网络分区(网络隔离):
在这种网络分区的情况下,如果我们允许少数派选举主节点,也会出现刚才我们提到的的「脑裂」现象。 通过要求多数决策,数据中心B的3个成员可以正常选举主节点并继续服务,而数据中心A的2个成员则会保持从节点状态,拒绝写入操作。这样就避免了数据分歧的风险。
基于多数决策的原则,有几种推荐的副本集部署模式:
- 主数据中心模式:将多数成员部署在主数据中心,少数成员部署在备用数据中心。这种模式适合有明确主备数据中心的场景。只要主数据中心正常,副本集就能正常运行。但如果主数据中心出现问题,副本集将变为只读状态。
- 三地部署模式:在两个主要数据中心各部署相等数量的成员,然后在第三个地点部署一个「仲裁者」成员。这种模式下,任何一个数据中心出现问题,剩余的成员仍能形成多数,保证服务的连续性。
深入选举机制
副本集的选举过程是一个精心设计的分布式共识算法,基于RAFT协议的思想但针对MongoDB的特殊需求进行了定制。 选举在以下情况下会被触发:
- 主节点不可达:当从节点无法在指定时间内(默认10秒)收到主节点的心跳信号时,它们会认为主节点已经失效并开始选举过程。
- 副本集初始化:当新建立的副本集首次启动时,需要通过选举确定第一个主节点。
- 主节点主动让位:在某些维护场景下,主节点可能会主动让位,触发新的选举。
选举过程遵循严格的步骤:
发起选举:当从节点检测到需要选举时,它会联系所有其他可达的成员,请求它们投票支持自己成为主节点。
资格检查:其他成员会进行多项检查:
- 候选者的数据是否足够新(不能比其他成员落后太多)
- 候选者的优先级是否足够高
- 当前是否已有其他主节点存在
投票和等待:符合条件的成员会投票给候选者。候选者需要获得多数票才能成为主节点。
主节点确认:新主节点开始发送心跳信号,其他成员确认其权威性并转变为从节点。
心跳和健康检测
MongoDB 副本集成员间基于定期心跳(默认每2秒一次)机制实现健康检查与状态同步。心跳消息除传递节点可达性信息外,还包含成员当前角色、oplog 位点以及数据滞后情况等关键元数据,支撑集群一致性与高可用运维。
若某一节点连续10秒未收到心跳响应,则被其他成员认定为不可达,从而可能发起自动主节点选举。此超时窗口在降低误判概率、平衡服务可用性与网络波动容忍度之间做出权衡。只有在节点长时间失联才会触发选举,避免因瞬时抖动导致频繁的主从切换,保障业务连续性。
副本集成员配置
截至目前,副本集成员通常采用默认配置,即所有节点具有相同的角色与权重。然而在生产环境中,常常需要针对特定成员进行定制化配置,以实现更精细的集群管理。 例如,可以为核心节点分配更高的主节点优先级,或将部分成员设为对客户端不可见的隐藏节点,从而满足容灾、备份、只读分析等多样化业务需求。
优先级配置
优先级是一个数值(0到100),用来表示成员「想要」成为主节点的强烈程度。默认值是1,优先级为0的成员永远不会成为主节点,被称为「被动成员」。
设置高优先级成员
假设我们有一台性能更强的服务器,希望它优先成为主节点:
javascript
> rs.add({"host": "powerfulserver:27017", "priority": 1.5})一旦这个高优先级成员完成数据同步并追上其他成员的进度,当前的主节点会自动让位,让这个新成员成为主节点。这个过程是平滑的,不会导致数据丢失。
配置被动成员
有时我们希望某些成员永远不成为主节点,比如用于备份或分析的服务器:
javascript
> var config = rs.config()
> config.members[2].priority = 0
> rs.reconfig(config)优先级的绝对数值不重要,重要的是相对大小。优先级为100、1、1的副本集与优先级为2、1、1的副本集行为完全相同。
隐藏成员
隐藏成员是一种特殊的从节点,它们对客户端应用不可见,也不会被优先选择作为数据同步源。这种配置适用于备份服务器或性能较低的机器。 要将一个成员设置为隐藏,必须同时将其优先级设为0,即成为「被动成员」:
javascript
> var config = rs.config()
> config.members[2].hidden = true
> config.members[2].priority = 0
> rs.reconfig(config)配置完成后,使用db.isMaster()命令时,隐藏成员不会出现在hosts列表中:
javascript
> db.isMaster()
{
"hosts" : [
"server1:27017",
"server2:27017"
// 隐藏成员不会显示在这里
],
...
}但在rs.status()和rs.config()的输出中仍然可以看到隐藏成员,因为这些是管理命令,会显示所有成员的信息。
仲裁者成员
仲裁者是一种特殊的副本集成员,它们不存储数据,唯一的作用就是参与选举投票。这种设计主要为了解决两成员副本集的多数决策问题。
在只有两个数据存储节点的小型部署中,添加仲裁者可以满足多数决策的要求。仲裁者可以运行在相对低配的服务器上,因为它不需要存储数据或处理查询,也不会被客户端连接。
javascript
> rs.addArb("arbiter-server:27017")或者使用完整的配置格式:
javascript
> rs.add({"_id": 4, "host": "arbiter-server:27017", "arbiterOnly": true})仲裁者一旦添加就无法改变角色,不能将普通成员改为仲裁者,也不能将仲裁者改为数据成员。
仲裁者的数量应该控制在最多一个。添加多个仲裁者不仅没有好处,反而可能降低集群的稳定性。例如,在三成员集群中添加仲裁者会使多数要求从2个增加到3个,实际上降低了可用性。
在生产环境中,如果可能的话,尽量使用奇数个数据存储成员而不是仲裁者。这样可以提供更好的数据安全性和操作灵活性。
索引构建控制
在某些场景下,我们可能不希望某个从节点构建索引,比如专门用于数据备份或离线批处理的节点。
javascript
> var config = rs.config()
> config.members[3].buildIndexes = false
> config.members[3].priority = 0 // 必须同时设为0
> rs.reconfig(config)这个设置是永久性的。一旦配置了buildIndexes: false,该成员就无法再被重新配置为构建索引。如果需要改变这个设置,必须将成员从副本集中移除,删除其所有数据,然后重新添加并让其完全重新同步。
延迟从节点
MongoDB支持配置延迟从节点,可使指定成员有意延后主节点一定时间应用oplog,从而实现数据延迟同步。这一机制常用于防止误操作导致的数据丢失,为数据恢复提供额外的安全保障:
javascript
> var config = rs.config()
> config.members[4].slaveDelay = 3600 // 延迟1小时
> config.members[4].priority = 0
> config.members[4].hidden = true
> rs.reconfig(config)成员标签
副本集成员还可以配置标签,用于更精细的读写偏好控制和数据分布策略。标签是任意的键值对,可以表示地理位置、硬件类型等属性:
javascript
> var config = rs.config()
> config.members[0].tags = {"datacenter": "east", "usage": "production"}
> config.members[1].tags = {"datacenter": "east", "usage": "production"}
> config.members[2].tags = {"datacenter": "west", "usage": "backup"}
> rs.reconfig(config)通过本部分的学习,我们了解了MongoDB副本集的方方面面,从基础概念到高级配置,从实际操作到设计原则。副本集是MongoDB高可用性的基石,正确理解和使用这些知识对于构建稳定可靠的数据库系统至关重要。 即使现在你觉得它可能没什么用,也许在未来的某一天,你会需要使用MongoDB副本集来构建一个高可用性的数据库系统。