入门MongoDB 数据库
在现代软件开发的世界里,数据存储方案的选择往往决定了应用的成败。MongoDB 作为一款新时代的数据库,它不仅具备强大的功能,更重要的是它为开发者提供了一种全新的数据思考方式。
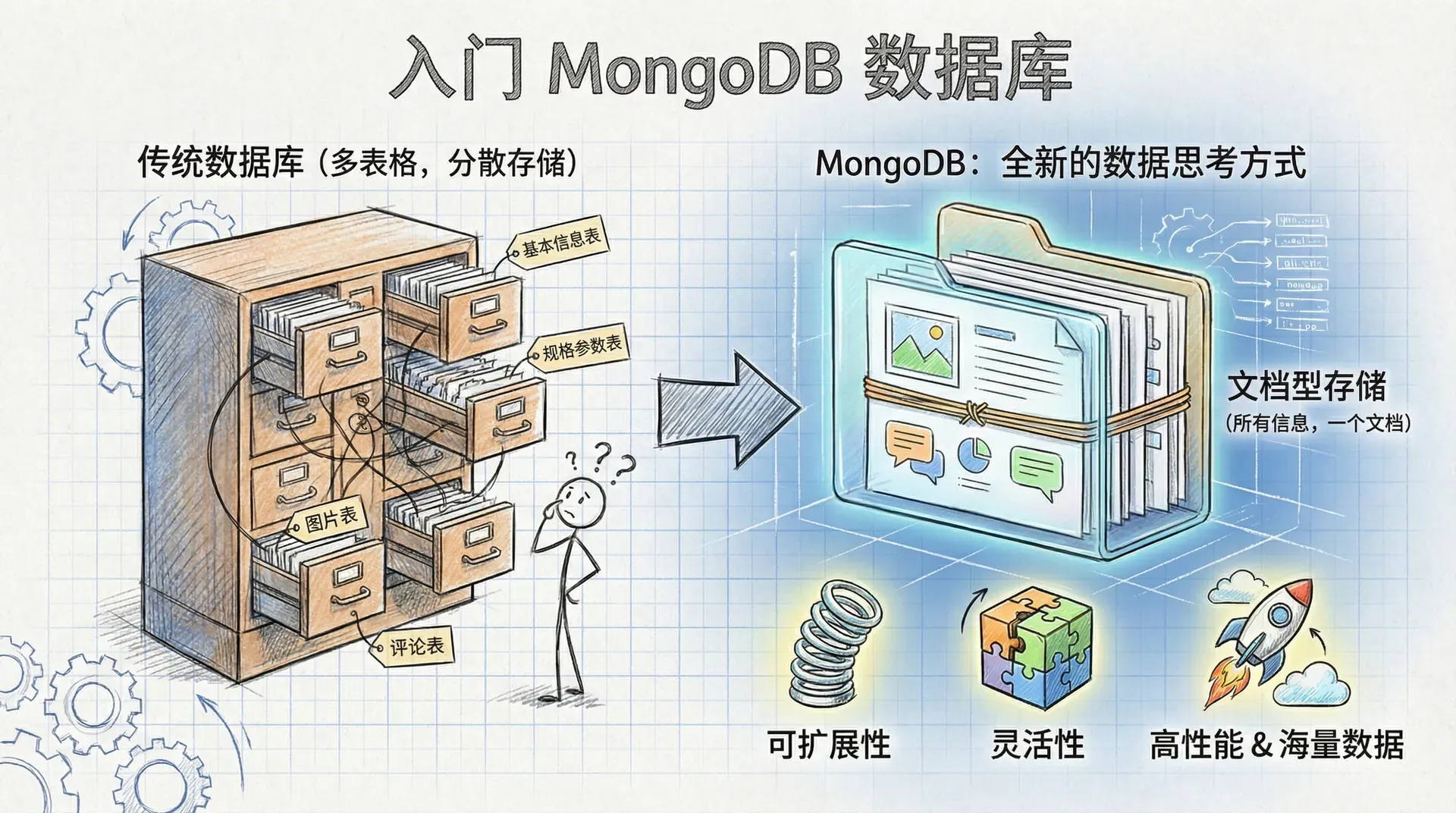
如果我们要为一个电商网站存储商品信息,传统的关系型数据库可能需要我们创建多个表格:商品基本信息表、规格参数表、图片表、评论表等等。但是 MongoDB 让我们可以把一个商品的所有相关信息都存储在一个文档里,就像把一份完整的商品档案放在一个文件夹中一样自然。
MongoDB 的核心优势在于它将可扩展性、灵活性和性能完美地结合在一起。它不仅能够处理传统数据库的基本需求,还能应对现代应用面临的海量数据挑战。
为什么选择文档数据库
传统的关系型数据库基于「表格」的概念,每一行数据都必须遵循严格的列定义。这就像要求每个人都必须填写一模一样的表单,即使有些字段对某些人来说并不适用。
MongoDB 采用了文档导向的设计思路,这种方式更接近我们在日常编程中处理对象的方法。比如,当我们用 JavaScript 描述一个用户时:
javascript
const user = {
name: "张三",
age: 28,
interests: ["阅读", "旅行", "摄影"],
address: {
city: "北京",
district: "朝阳区"
}
}在 MongoDB 中,我们可以直接将这样的对象存储为一个文档,无需拆分成多个表格。这种方式的好处是显而易见的:
开发效率更高,因为数据结构与代码中的对象模型完全一致。当我们需要为用户增加新的属性,比如「职业」或「学历」时,我们不需要修改数据库结构,直接在文档中添加新字段即可。
文档数据库的这种灵活性特别适合快速迭代的现代软件开发模式,让开发团队可以更专注于业务逻辑而不是数据库结构的维护。
横向扩展的设计思路
随着互联网应用越来越多,大家需要存储的数据也越来越大,动不动就是几百GB、几TB。这时候,数据库怎么扩容、怎么让它能撑住压力,就成了关键问题。
过去常见的做法叫「纵向扩展」,其实就是把服务器换成更强的,比如给电脑加内存、换更快的CPU,就像家里人多了就直接换个大房子。但这样做会越来越贵,而且总有花再多钱也买不到更大房子的一天。
MongoDB 一开始就打定主意用「横向扩展」的方法。你可以理解为,不用一家人都住在一栋大房子里,而是大家分开,住在多个小房子,每个房子只负责一部分事情。这样只要需要,就不断多建几间小房子,省钱又灵活,还没有上限。
这种分片机制的巧妙之处在于,应用程序完全感觉不到数据被分散存储。无论是查询用户「张三」的信息还是「王五」的订单,MongoDB 都会自动将请求路由到正确的分片上,并返回结果。
丰富的功能特性
MongoDB 不仅仅是一个简单的文档存储系统,它提供了现代应用所需的各种高级功能。
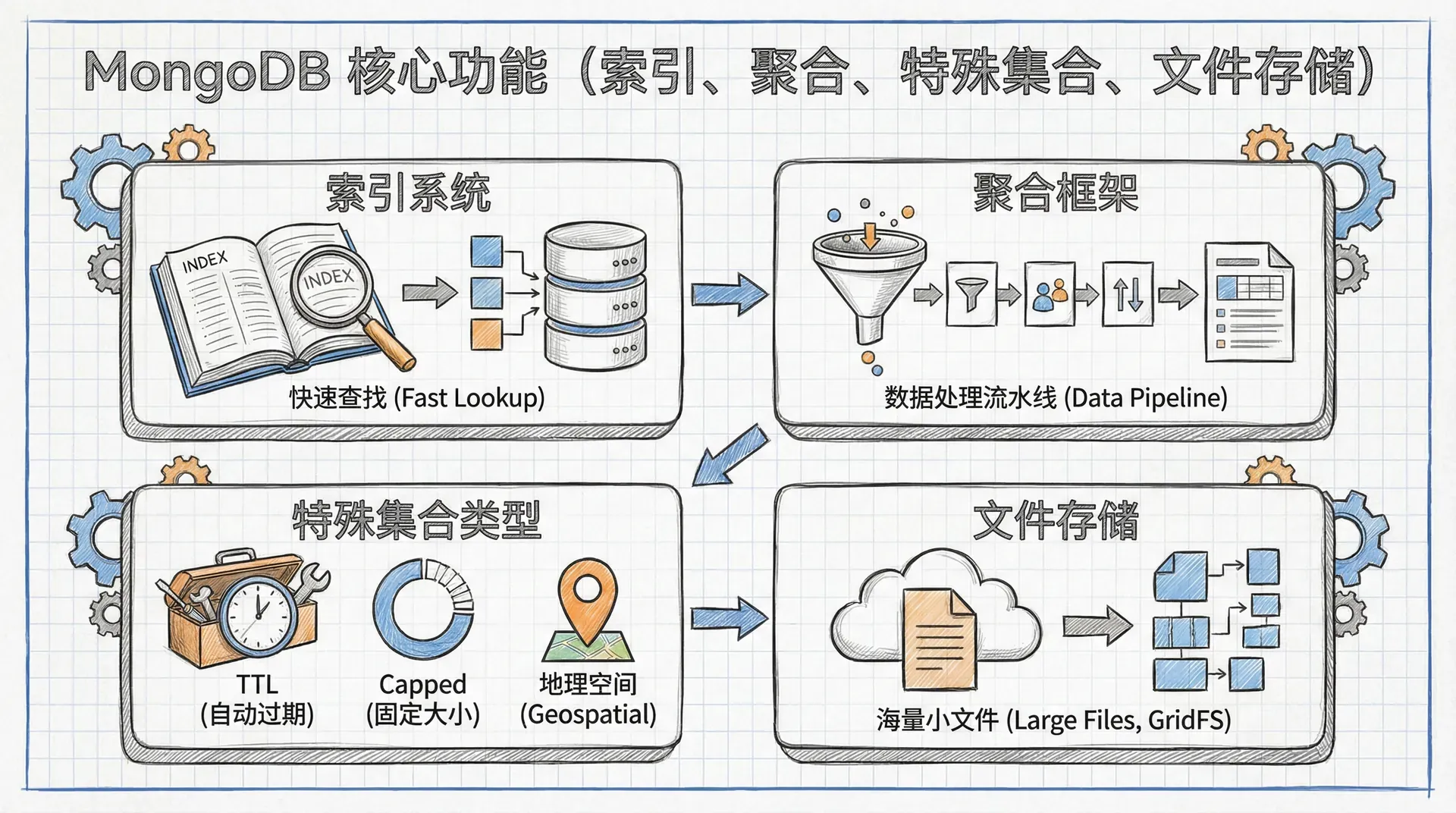
索引系统
MongoDB 提供了强大的索引系统,显著提升了数据检索的效率。常见索引类型包括:
- 复合索引:支持在多个字段上同时建立索引,适用于例如按「城市」与「年龄」组合查询用户等复杂检索场景。
- 地理空间索引:针对地理位置数据的高效索引,广泛应用于如“查询指定坐标范围内数据点”或“检索附近餐厅”等空间查询。
- 文本索引:内置全文检索能力,可以在庞大的文本字段(如商品描述)中高效定位关键词,满足搜索场景需求。
聚合框架
MongoDB 的聚合框架为复杂的数据处理与分析提供了高效的管道式操作方式。通过定义一系列数据转换与分组步骤,可以实现统计分析、数据清洗等高级需求。 例如,统计各城市用户的平均年龄:
javascript
db.users.aggregate([
{ $group: { _id: "$city", avgAge: { $avg: "$age" } } },
{ $sort: { avgAge: -1 } }
])这个管道首先按城市分组计算平均年龄,然后按平均年龄降序排列。
特殊集合类型
MongoDB 提供了多种支持专业场景的特殊集合类型:
- TTL(Time-To-Live)集合:可针对含有生命周期的数据(如会话、缓存、临时令牌等)设定生存时间,超时后数据库将自动清理过期文档,无需手动维护,有效降低数据冗余和存储压力。
- 固定集合(Capped Collection):分配固定存储空间,采用循环覆盖策略写入数据。该类型适用于日志、审计信息等只需保留最新 N 条记录的场景,能保证高性能顺序写入和恒定存储占用。
文件存储
针对非结构化大对象(如图片、音视频、文档等),MongoDB 提供 GridFS 文件存储机制。GridFS 能自动将大文件拆分为多个数据块进行存储,并支持流式的上传和下载访问,兼顾了文件的高效管理和扩展性,适合存储超出 BSON 单文档限制(16MB)的文件。
高性能架构设计
MongoDB 以高性能为核心,通过多项架构设计实现高效数据处理:
MongoDB 的设计目标之一是降低数据管理的复杂性,将更多数据处理和一致性保障交由数据库层负责,让开发者专注于核心业务逻辑,提升开发效率和系统稳定性。
MongoDB 的设计理念
回顾 MongoDB 的架构和功能设计,可以归纳出其核心理念:
MongoDB 的定位并非取代所有类型数据库,而是作为面向灵活数据建模、大规模扩展和高实时性需求场景的优选解决方案。它特别适用于支持敏捷开发、非结构化数据管理和弹性水平扩展的现代应用。 对于初学者而言,理解 MongoDB 背后的架构理念和技术权衡比掌握具体 API 更为重要。只有深入理解其设计动机,才能在实际项目中发挥其最大优势并且知道在什么时候使用它。
从这一刻起,你将能亲手体验 MongoDB 在实际开发中的强大与灵活。让我们带着对高效数据管理的全新理解,开启后续课程的征程吧!