逻辑回归
到目前为止,我们学习的都是回归问题——预测连续的数值。但现实世界中,很多问题的答案是离散的类别:这封邮件是不是垃圾邮件?这个肿瘤是良性还是恶性?用户会不会点击这个广告?这些都是分类问题。
逻辑回归(Logistic Regression)是处理分类问题的经典算法。虽然名字中有“回归”二字,但它实际上是分类算法。逻辑回归不仅简单高效,而且是理解更复杂分类器(包括神经网络)的基础。事实上,深度神经网络的每个神经元本质上就是一个逻辑回归单元。
所以这节课我们将学习如何把线性回归的思想扩展到分类问题,如何设计适合分类的代价函数,以及如何将逻辑回归应用到多分类任务。
分类问题的特点
分类与回归的根本区别在于输出的性质。回归预测的是连续值,可以是任意实数;分类预测的是离散的类别标签。
最简单的是二分类(Binary Classification)问题,输出只有两个可能的类别。我们通常用0和1来表示这两个类别:
- :负类(Negative Class),比如"不是垃圾邮件"、"良性肿瘤"
- :正类(Positive Class),比如"是垃圾邮件"、"恶性肿瘤"
选择哪个类别作为正类是人为规定的,通常我们把想要检测的、比较罕见的那一类作为正类。
如果我们直接用线性回归来做分类会怎样?比如预测肿瘤是否恶性,用肿瘤大小作为特征。我们可能会得到一个线性模型 。但这有几个问题:
线性回归的输出可以是任意实数,而我们需要的是0或1。我们可以设定一个阈值,比如0.5,大于0.5就预测为1,否则预测为0。但这很不自然,而且容易受异常值影响。
假设我们的训练数据中,肿瘤大小从1cm到10cm,用线性回归拟合得还不错。突然来了一个极端案例,肿瘤大小30cm,当然是恶性的()。加入这个点后,线性回归的直线会被"拉"向它,导致原来分类正确的点现在分类错了。
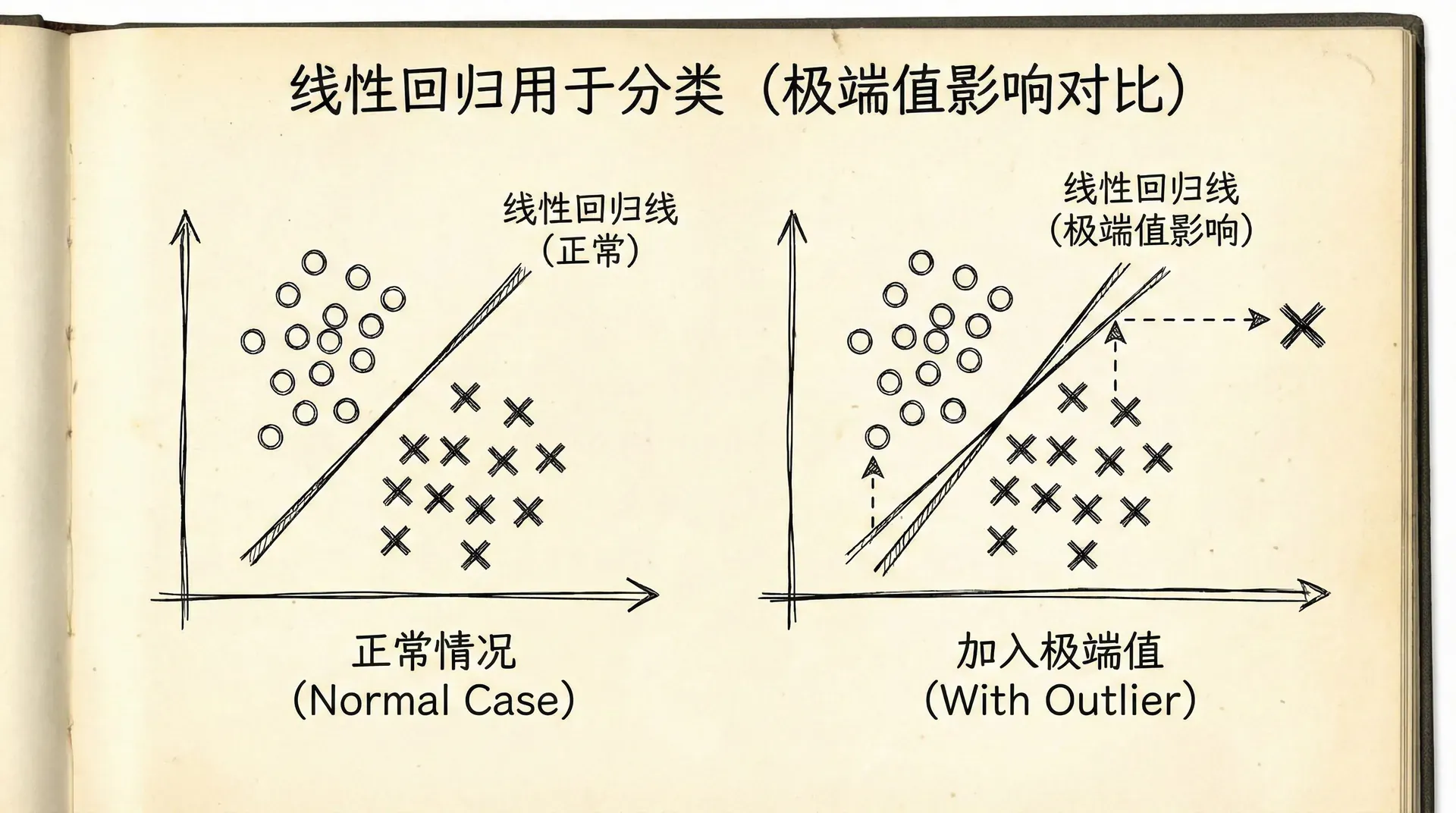
我们需要一个更适合分类的模型,它的输出应该自然地落在0和1之间,可以解释为“属于正类的概率”。这就是逻辑回归。
逻辑回归输出的是概率。输出0.8意味着模型认为有80%的可能性属于正类,20%的可能性属于负类。这比简单的0/1分类提供了更丰富的信息,我们可以根据应用需求选择不同的决策阈值。
逻辑回归的假设函数
逻辑回归的关键是引入S型函数(Sigmoid Function),也称为逻辑函数(Logistic Function):
这个函数有很好的性质:
- 当 时,
- 当 时,
逻辑回归的假设函数是:
我们先用线性组合 计算一个实数值,然后用sigmoid函数把它映射到(0, 1)区间。 可以解释为:给定输入 和参数 , 的概率。
相应地, 的概率是 。
举个例子,假设我们预测肿瘤是否恶性,特征是肿瘤大小。如果对于某个肿瘤,,那么:
模型认为这个肿瘤有88%的概率是恶性的。如果我们的决策阈值是0.5,我们会预测它是恶性。
决策边界(Decision Boundary)是使 的点的集合。由于当 时 ,决策边界就是 。
- 当 时,,预测
对于二维特征 和 ,如果 (包括截距项),决策边界是:
即 ,这是一条直线。在这条线的一边,预测为正类;另一边预测为负类。
逻辑回归的决策边界是线性的。但通过引入多项式特征(就像我们在线性回归中做的),可以得到非线性的决策边界。比如使用特征 ,参数 ,决策边界是:
即 ,这是一个圆!圆内预测为一类,圆外预测为另一类。
逻辑回归的代价函数
为什么不能用线性回归的均方误差作为逻辑回归的代价函数?因为逻辑回归的假设函数是非线性的(包含sigmoid),如果用均方误差,代价函数会是非凸的,有很多局部最小值,梯度下降可能无法找到全局最优解。
我们需要设计一个凸函数作为代价函数。对于单个样本,我们定义损失函数(Loss Function):
理解这个定义:
- 当真实标签 时,如果我们预测 (正确),损失接近0;如果预测 (错误),损失趋向无穷大,给予严厉惩罚。
这个损失函数巧妙地实现了:预测正确时损失小,预测错误时损失大,而且是凸函数,便于优化。
对于整个训练集,代价函数是所有样本损失的平均:
这个公式巧妙地把两种情况合并了:当 时,第二项为0;当 时,第一项为0。
用向量化表示更简洁:
其中 是所有样本的预测概率向量。
逻辑回归的代价函数来源于最大似然估计。从概率的角度,它衡量的是“在当前参数下,观测到训练数据的可能性有多大”。最小化这个代价函数,等价于最大化数据的似然,这是统计学中估计参数的经典方法。
梯度下降与优化
逻辑回归的代价函数看起来复杂,但求梯度后形式却很简洁。通过求导(这里省略推导过程),我们得到:
用向量化表示:
这个形式和线性回归的梯度惊人地相似!唯一的区别是这里的 是sigmoid函数,而线性回归中是线性函数。
梯度下降的更新规则:
实现代码:
python
import numpy as np
def sigmoid(z):
"""Sigmoid函数"""
return 1 / (1 + np.exp(-z))
def computeCost(X, y, theta):
"""计算逻辑回归的代价函数"""
m = len(y)
h = sigmoid(X @ theta)
# 避免log(0)的情况,加一个很小的数
epsilon = 1e-10
cost = (-
逻辑回归也可以使用高级优化算法,它们通常比梯度下降更快:
- 共轭梯度法(Conjugate Gradient):不需要手动选择学习率,收敛更快。
- BFGS和L-BFGS:拟牛顿法,利用二阶导数信息,收敛速度快,适合中大规模问题。
这些算法的原理比较复杂,但在实践中我们可以直接调用库函数。在Octave中:
octave
% 定义代价函数和梯度函数
function [J, grad] = costFunction(theta, X, y)
m = length(y);
h = sigmoid(X * theta);
J = (-1/m) * (y' * log(h) + (1-y)' * log(1-h));
grad = (1/m) * X' * (h - y);
end
% 使用高级优化算法
options = optimset('GradObj', 'on', 'MaxIter', 400);
[theta, cost] = fminunc(@(t)(costFunction(t, X, y)), initial_theta, options);fminunc 是无约束优化函数,它会自动选择优化算法并调整参数,我们只需要提供代价函数和梯度的计算方法。
多元分类:一对多策略
到目前为止我们处理的都是二分类。如果有多个类别怎么办?比如手写数字识别,有0-9共10个类别;邮件分类,可能有工作、私人、促销、垃圾邮件等多个类别。
一种自然的扩展是一对多(One-vs-All或One-vs-Rest)策略。基本思想是:对于K个类别,训练K个二分类器,第i个分类器把类别i作为正类,其他所有类别作为负类。
具体步骤:
- 对每个类别 ,训练一个逻辑回归分类器 ,预测 的概率
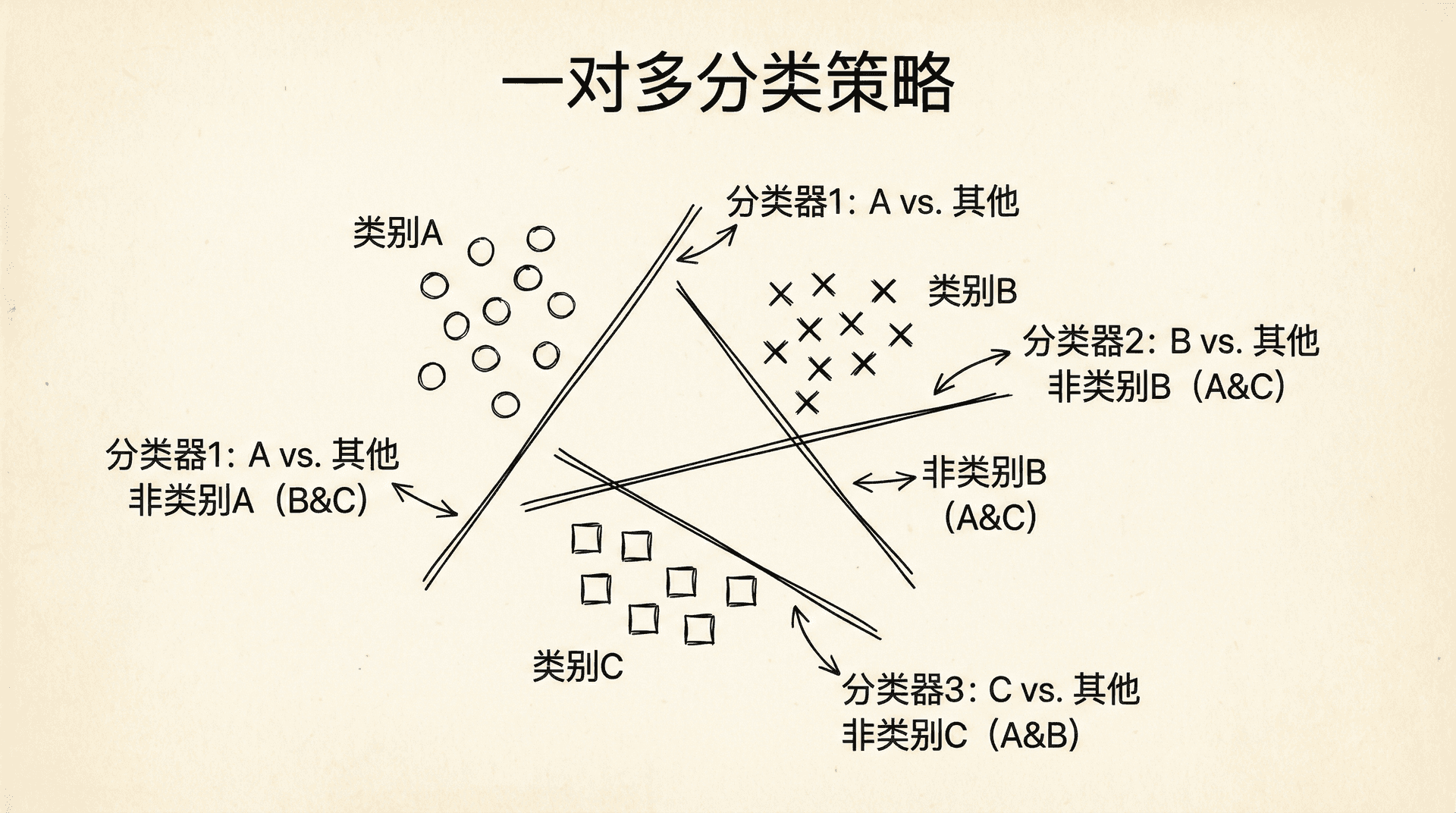
代码实现:
python
def oneVsAll(X, y, numLabels, lambda_reg):
"""
训练多个一对多分类器
X: 特征矩阵
y: 标签(1, 2, ..., numLabels)
numLabels: 类别数量
lambda_reg: 正则化参数
返回:所有分类器的参数矩阵
"""
m, n = X.shape
all_theta = np.zeros((numLabels, n))
for i in range(numLabels):
# 创建二分类标签:类别i为1,其他为0
binary_y = (y == i).astype(int)
# 训练第i个分类器
initial_theta
一对多策略简单有效,适用于类别不太多的情况。但当类别数量很大时,需要训练很多分类器,计算和存储开销会增大。这时可以考虑其他方法,比如softmax回归(多分类逻辑回归的直接扩展)或多类支持向量机。
使用一对多策略时,要注意类别不平衡的问题。如果某个类别的样本很少,对应的分类器可能训练不好。这时可以考虑重采样(过采样少数类或欠采样多数类)或调整分类阈值。
接下来
在下一个部分,我们将学习正则化技术。我们会看到,过于复杂的模型容易过拟合,而正则化可以控制模型复杂度,提高泛化能力。正则化不仅适用于线性回归,也适用于逻辑回归和其他算法,是机器学习实践中的重要技术。
逻辑回归虽然简单,但它的思想深刻而广泛。sigmoid函数、最大似然估计、概率解释、一对多策略,这些概念会在后续的神经网络、深度学习中反复出现。深度神经网络可以看作是多层逻辑回归的堆叠和组合。掌握逻辑回归,你就为理解更复杂的模型打下了坚实基础。
小练习
-
计算逻辑回归的代价函数:给定训练数据,手动计算逻辑回归的代价函数值。
数据:
模型参数:,
答案:
步骤1:计算每个样本的预测值
样本1:
-
实现一对多分类:假设你要实现一个识别数字0-2的分类器(3个类别)。
给定一个样本 ,三个二分类器的输出分别为:
- 分类器1(类别0 vs 其他):
答案:
一对多(One-vs-All)分类策略:
在一对多分类中,我们训练 K 个二分类器(K是类别数量)。每个分类器负责识别一个类别:
- 分类器1:判断是否为类别0
- 分类器2:判断是否为类别1
- 分类器3:判断是否为类别2
分类规则: 选择输出概率最高的分类器对应的类别: