Kubernetes 是如何工作的
在这一部分,我们会一起探索构建一个 Kubernetes 集群并部署应用所需的各大核心组件。 我们的目标是让你对这些主要概念有一个宏观的认识。 所以,即使有些地方一开始没完全搞懂也没关系,随着我们深入学习,这些概念会反复出现,你会越来越清晰。
Kubernetes究竟是什么?
从最高的层面来看,Kubernetes 同时扮演着两个角色:它既是一个运行应用程序的集群,又是一个云原生应用的“总指挥”(Orchestrator)。
Kubernetes 作为集群
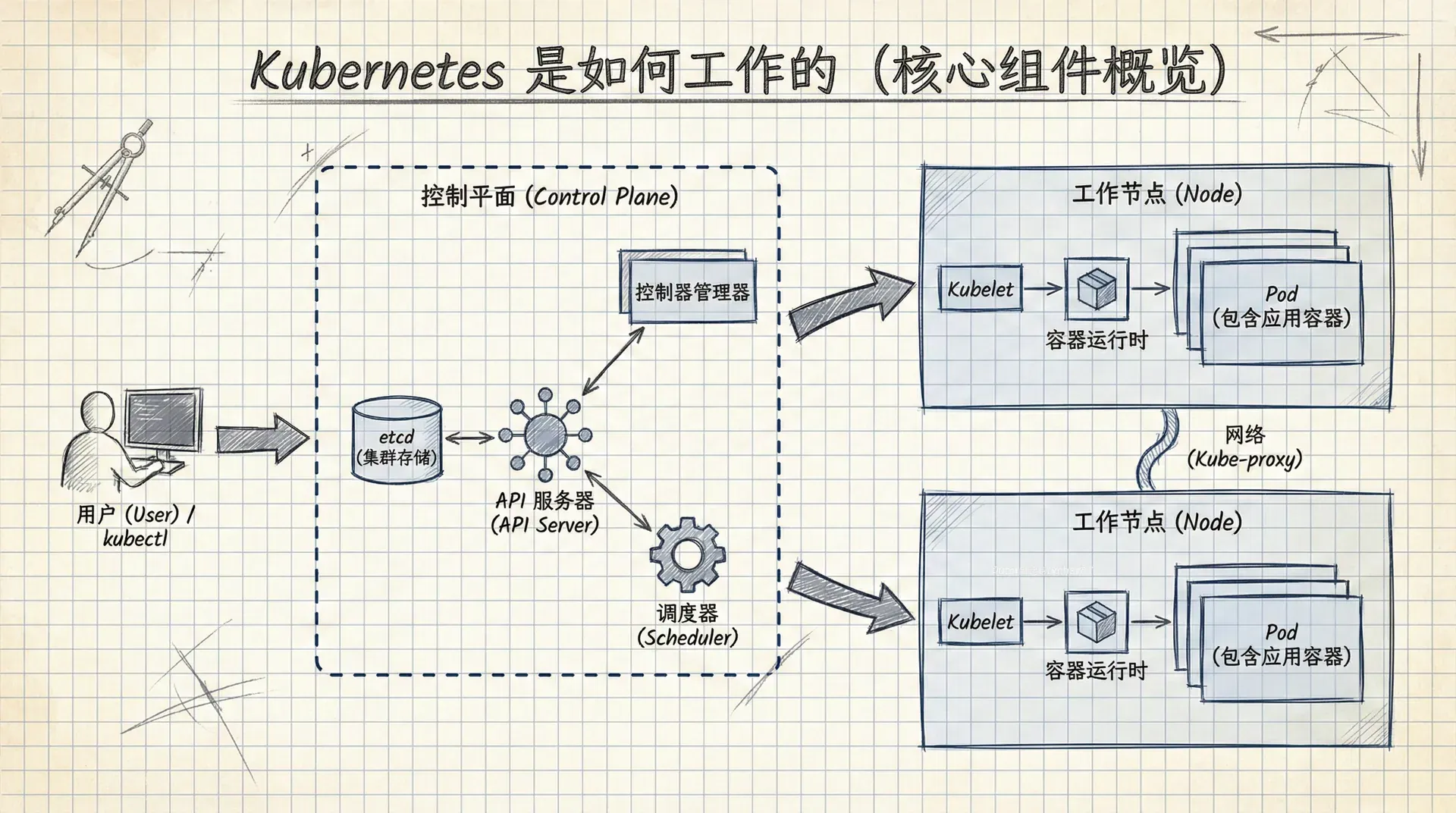
首先,把 Kubernetes 想象成一个计算机集群。它和别的集群一样,由一堆计算机(我们称之为节点)和一个控制平面(Control Plane)组成。 控制平面就像是集群的“大脑”,负责发号施令,比如决定哪个程序该在哪个节点上运行、如何自动扩缩容、如何实现零停机更新等等。 而节点们就是“肌肉”,负责执行“大脑”下达的命令,日复一日地运行着我们的应用程序代码。
这个“大脑”通过一个统一的 API 接口对外提供服务,并将整个集群的状态信息记录在一个持久化的存储里。 所以,你可以把控制平面看作是运筹帷幄的指挥中心,而节点则是冲锋陷阵的士兵。
Kubernetes 作为总指挥
“Orchestrator”(总指挥)这个词听起来可能有点玄乎,但其实它就是指一个能够自动部署和管理应用程序的系统。
让我们用一个生活中的例子来理解它。想象一下一支足球队,队里有前锋、中场、后卫、守门员,每个人都有自己的特长和位置。他们虽然都是独立的个体,但如果没有教练的组织和战术安排,他们就是一盘散沙。 教练的角色就是把这些各怀绝技的球员组织起来,安排阵型,制定战术,让他们作为一个整体去赢得比赛。比赛中,教练还要随时关注场上情况,应对突发事件,比如有球员受伤了,就要马上换人,以保持队伍的战斗力。
在软件世界里,我们开发的微服务应用就像是这些球员。每个服务都有自己的专长,比如有的负责用户认证,有的负责处理数据,有的负责展示网页。 Kubernetes 就扮演了那个“教练”的角色。它把这些独立的服务组织成一个有用的应用程序,确保它们协同工作,平稳运行。当某个服务出现问题(就像球员受伤),Kubernetes 会自动处理,让整个应用保持健康。
在体育界,我们称之为“执教”(Coaching);在软件界,我们称之为“编排”(Orchestration)。Kubernetes 就是云原生应用的编排大师。
Kubernetes 的工作流程
要让 Kubernetes 这位“教练”施展魔法,我们通常遵循一个简单的模式:
编写应用:我们把复杂的应用拆分成一个个小的、独立的微服务。
打包应用:我们将每个微服务打包成一个容器(Container)。容器是一种轻量级的虚拟化技术,可以把应用及其依赖一起打包。
封装成 Pod:我们将每个容器封装在一个叫做 Pod 的对象里。Pod 是 Kubernetes 中部署和管理的最小单位。
部署到集群:我们通过更高级的控制器(比如 Deployment)来部署这些 Pod。
现在你可能对这些新名词感到陌生,别担心。简单来说,Deployment 提供了弹性伸缩和滚动更新的能力,让你的应用能应对高并发,并且在更新时不会中断服务。
Kubernetes 喜欢一种叫做声明式(Declarative)的管理方式。你不需要一步步告诉 Kubernetes “先做什么,再做什么”,而是像下订单一样,在一个 YAML 文件里描述清楚你“想要”的应用状态。比如,“我想要我的应用运行 3 个副本,使用这个版本的镜像,开放这个端口”。
然后,你把这个“订单”(YAML 文件)交给 Kubernetes,它就会像一个尽职尽-责的管家,帮你把一切都安排得妥妥当当。不仅如此,它还会持续监控,确保应用的实际状态始终和你声明的“期望状态”保持一致。如果发现有出入,它会马上采取行动,自动修复。
这就是 Kubernetes 工作模式的概览。接下来,让我们深入了解一下它的核心组件。
核心组件:Master 和 Node
一个完整的 Kubernetes 集群由 Master 节点(现在更常称为控制平面)和工作节点(Node)组成。它们都是 Linux 主机,可以是物理服务器,也可以是云上的虚拟机。
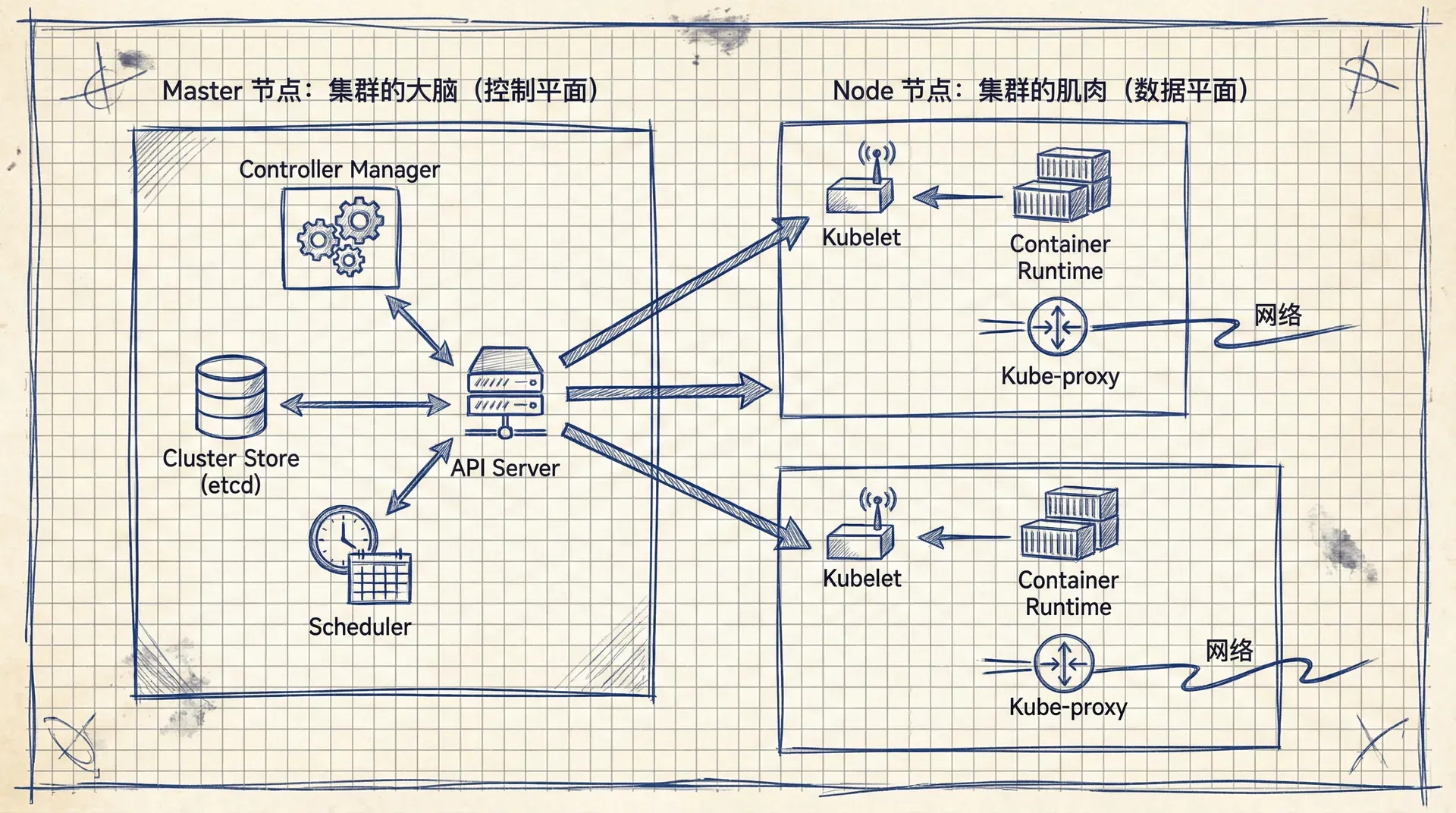
Master 节点:集群的大脑(控制平面)
Master 节点是集群的控制中心,它由一系列系统服务组成,共同构成了控制平面。
在一个小型的测试环境里,你可以在一台机器上运行所有的 Master 服务。但在生产环境中,为了保证高可用性,通常会部署多个 Master 节点,组成一个高可用(HA)集群。 这就是为什么主流的云服务商(如 AWS, Azure, Google Cloud)提供的 Kubernetes 服务都默认是高可用架构。
通常,我们不会在 Master 节点上运行我们自己的应用程序。这样可以让 Master 专心致志地管理集群,保证整个系统的大脑时刻保持清醒和高效。
控制平面主要由以下几个关键服务构成:
API Server
API Server 是 Kubernetes 的“中央车站”。所有组件之间,以及用户和集群之间的所有通信,都必须经过它。它提供了一个标准的 RESTful API,我们通过向这个 API 发送 YAML 文件来表达我们的“期望状态”。API Server 在接收到请求后,会进行身份验证和权限检查,然后将配置信息存入集群的数据库,并通知其他组件开始工作。
Cluster Store (etcd)
Cluster Store 是控制平面中唯一一个有状态的部分,它持久化地存储了整个集群的配置和状态。目前,它基于一个叫做 etcd 的分布式数据库实现。etcd 是整个集群的“真理之源”,如果它损坏了,集群就无法正常工作了。因此,etcd 的高可用和数据备份至关重要。
Controller Manager
Controller Manager 是所有“控制器”的管理者。在 Kubernetes 内部,有许多独立的控制循环(Control Loop)在后台默默工作,持续监控集群状态。比如,有专门管理节点的控制器,有管理副本数量的控制器等等。Controller Manager 的职责就是启动和管理这些控制器。
每个控制器都在执行一个简单的逻辑:
获取期望状态。
观察当前状态。
比较两者差异。
采取行动,消除差异。
这个“期望状态 -> 当前状态 -> 协调”的循环,是 Kubernetes 声明式设计的核心。
Scheduler
Scheduler(调度器)负责“排兵布阵”。它会持续关注 API Server,看有没有新的任务(比如一个新的 Pod 需要运行)。一旦有新任务,调度器就会根据一系列复杂的算法,为这个任务挑选一个最合适的 Node 节点。
调度器在做决策时会考虑很多因素,比如:这个节点资源够不够?有没有特殊限制?哪个节点运行这个任务最高效?如果找不到合适的节点,任务就会暂时处于“待定”(Pending)状态。
Node 节点:集群的肌肉(数据平面)
Node 节点是集群中的“工兵”,它们负责真正运行应用程序。每个 Node 都很简单,主要做三件事:
- 向 Master 汇报自己的状态。
- 时刻关注 Master 分配的新任务。
- 执行任务(比如启动或销毁容器)。
每个 Node 上都运行着以下几个关键组件:
Kubelet
Kubelet 是每个 Node 上的“首席代理”。它负责与 Master 节点的 API Server 通信,管理在该节点上运行的容器。当 Kubelet 收到一个新任务时,它会指示容器运行时(Container Runtime)去启动相应的容器。
Container Runtime
容器运行时是负责管理容器生命周期的软件,比如拉取镜像、启动和停止容器等。Kubernetes 支持多种容器运行时,最著名的是 Docker,但现在 containerd 等更轻量级的运行时越来越受欢迎。
Kube-proxy
Kube-proxy 负责处理节点上的网络通信。它为每个 Node 配置网络规则,确保 Pod 之间可以相互通信,并负责将外部流量正确地路由到内部的 Pod。
应用的打包与部署
我们已经了解了集群的结构,现在来看看如何把我们的应用放上去。
从代码到容器,再到 Pod
我们的应用代码首先被打包成一个容器镜像。然后,这个容器被封装在一个 Pod 里。
Pod 是 Kubernetes 中最基本、最小的部署单元。你可以把 Pod 想象成一个豆荚,里面可以包含一个或多个豆子(容器)。虽然一个 Pod 里可以运行多个容器,但最常见的做法是“一个 Pod 一个容器”。
Pod 为容器提供了一个独立的运行环境,包括自己的 IP 地址和网络空间。同一个 Pod 里的容器共享这个环境,可以非常方便地进行通信和数据共享。
用 Deployment 管理 Pod
虽然我们可以直接创建一个 Pod,但这在实际生产中很少见。因为 Pod 是“脆弱的”,它们可能会因为各种原因死掉。如果一个 Pod 死了,它就不会再回来了。
为了让我们的应用更加健壮,我们会使用更高级的控制器来管理 Pod,最常用的就是 Deployment。
Deployment 就像是 Pod 的“守护者”。你在 Deployment 的 YAML 文件里声明:“我希望我的应用有 3 个 Pod 副本”。Deployment 就会创建 3 个 Pod,并持续监控它们。如果有一个 Pod 挂了,Deployment 会立刻创建一个新的来替代它,始终保持副本数量为 3。此外,Deployment 还支持应用的滚动更新和版本回滚,让应用发布变得既安全又简单。
Service:为应用提供稳定的网络
我们知道,Pod 的生命是短暂的,而且每次创建新的 Pod,它的 IP 地址都会改变。这就带来一个问题:如果一组提供后端服务的 Pod 地址一直在变,那么前端应用该如何找到它们呢?
为了解决这个问题,Kubernetes 引入了 Service 这个概念。 Service 为一组功能相同的 Pod 提供了一个统一、稳定的访问入口。它有一个固定的 IP 地址和 DNS 名称,并且会自动将收到的请求负载均衡到它背后所有健康的 Pod 上。
当 Pod 因为故障被替换,或者因为扩缩容而数量发生变化时,Service 会自动感知这些变化,并更新它的后端端点列表。对于访问这个 Service 的其他应用来说,这一切都是透明的,它们只需要和这个稳定的 Service 地址打交道即可。
Service 通过标签(Labels)和选择器(Selectors)来识别它应该管理哪些 Pod。你可以给你的 Pod 贴上标签,比如 app=backend, version=v1,然后在 Service 的配置中定义一个选择器,来匹配这些标签。这样,Service 就知道该把流量转发给谁了。
小结
在本节中,我们深入探讨了 Kubernetes 的核心运作机制。Kubernetes 集群由控制平面(Master 节点)和数据平面(Node 节点)构成,其中控制平面负责全局的决策和调度,而数据平面则负责具体的任务执行。
我们详细了解了如何将应用程序打包为容器,并将其封装在 Pod 中,通过 Deployment 进行管理,以实现应用的弹性伸缩和自愈能力。这种架构设计使得应用的部署和管理更加高效和可靠。 此外,我们还探讨了 Service 的重要性。Service 为动态变化的 Pod 提供了一个稳定的网络访问入口,并实现了负载均衡,确保了应用的高可用性和可扩展性。
接下来,我们将深入研究每个组件的细节,以便更好地掌握 Kubernetes 的强大功能。