Kubernetes 的核心单元 Pod
在本部分,我们将深入探讨其最核心、最基本的构建单元——Pod。我们会先从理论层面理解 Pod 是什么,然后再亲自动手创建并管理它。
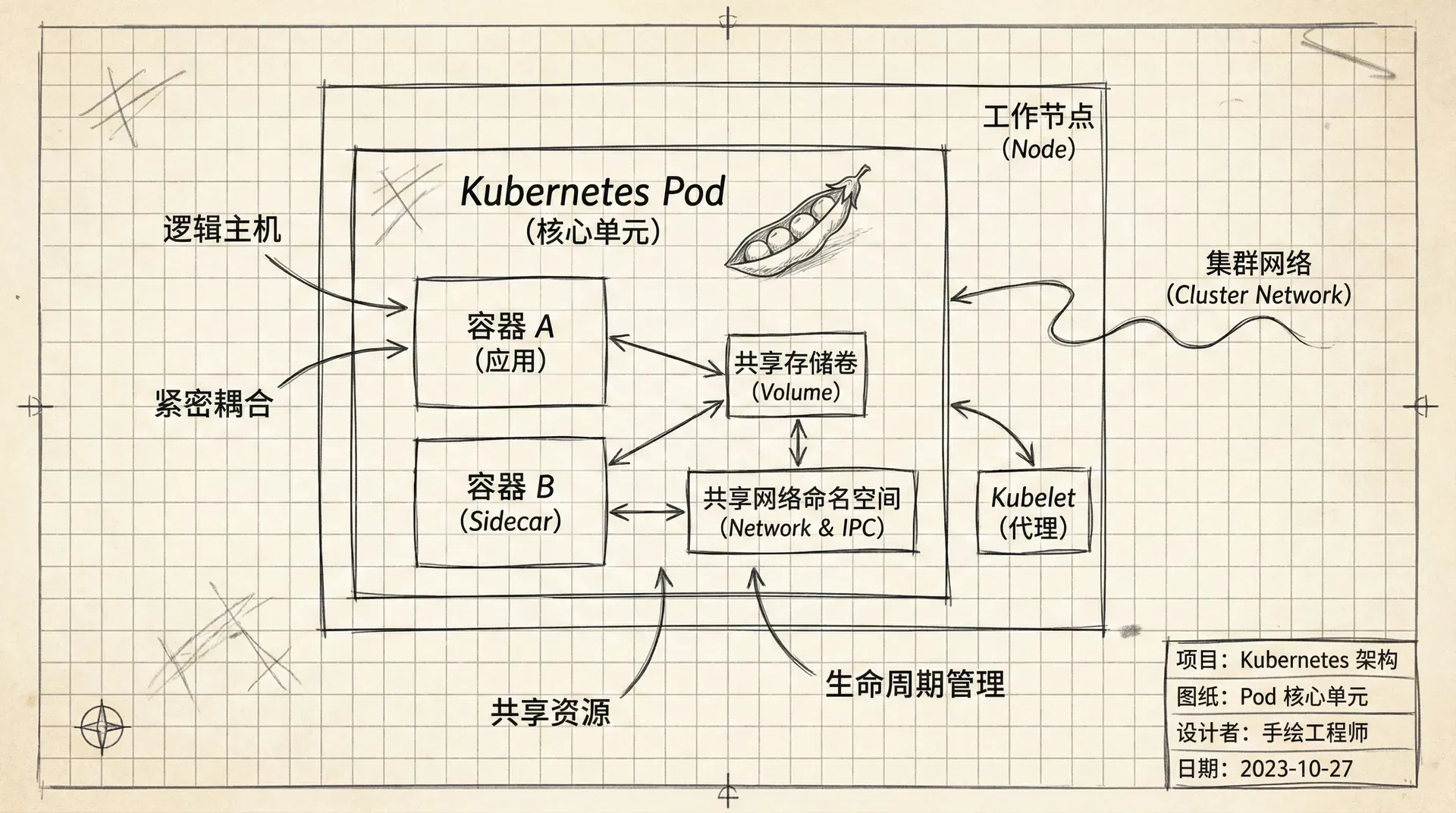
Pod 的理论世界
要理解 Pod,我们可以做一个简单的类比。在传统的虚拟化技术中,我们部署应用的最小单位是虚拟机(VM),它就像一栋独立的房子。在 Docker 的世界里,最小单位是容器(Container),它更像是一间公寓。
而在 Kubernetes 的舞台上,最小的调度和管理单位,既不是虚拟机也不是容器,而是一个全新的概念——Pod。你可以把 Pod 想象成一个“共享公寓”,里面可以住一个或多个关系紧密的容器。 这个概念是理解 Kubernetes 的基石,请务必记住:虚拟化对应虚拟机,Docker 对应容器,而 Kubernetes 对应 Pod。
请始终记住,Pod 本身不是我们的最终目的。它只是一个载体,一个运行我们应用程序的“房间”。我们真正关心的是运行在其中的应用程序。
Pod 与容器的微妙关系
一个 Pod 可以只包含一个容器,这是最常见的模式,就像一个人住一间单身公寓。但 Pod 的真正威力在于它可以容纳多个容器,形成一个“共享公寓”。
这种多容器设计非常适合处理那些需要紧密协作的任务。一个常见的应用场景是“边车模式”(Sidecar Pattern)。想象一下,你的主应用容器是一个赛车手,而边车容器就是他的辅助伙伴,负责处理日志收集、网络代理、数据同步等任务。 将它们放在同一个 Pod 中,就能确保它们总是一起被调度、一起运行,并且可以轻松共享资源。
一个典型的例子是服务网格(Service Mesh),它会向每个应用 Pod 中注入一个网络代理边车,用来处理所有进出 Pod 的网络流量,从而实现流量加密、监控和智能路由等高级功能。 这种“关注点分离”的设计,让每个容器只做一件事并把它做好,是现代云原生应用设计的一个重要原则。
我们如何部署 Pod?
在 Kubernetes 中,我们不提倡手动、一个一个地去创建 Pod。相反,我们采用一种“声明式”的方法。这意味着你只需要准备一个“蓝图”,告诉 Kubernetes 你想要的最终状态是什么样子,然后 Kubernetes 会负责搞定剩下的一切。
这个“蓝图”通常是一个 YAML 格式的清单文件(Manifest)。你在这份文件里详细描述你的 Pod 应该长什么样,然后把这份“蓝图”提交给 Kubernetes 的大脑——API Server。 控制平面会接收并验证这份蓝图,将其意图保存在集群的“数据库”中,然后由调度器(Scheduler)在集群中寻找一个最合适的节点(Node)来“建造”这个 Pod。
值得一提的是,Pod 的部署是一个原子操作。这意味着部署要么完全成功(所有容器都准备就绪),要么完全失败,不存在一个“部分部署成功”的 Pod。这保证了应用状态的一致性。
Pod 的内部构造
从外部看,Pod 是一个独立的单元,但其内部却是一个为容器打造的共享执行环境。
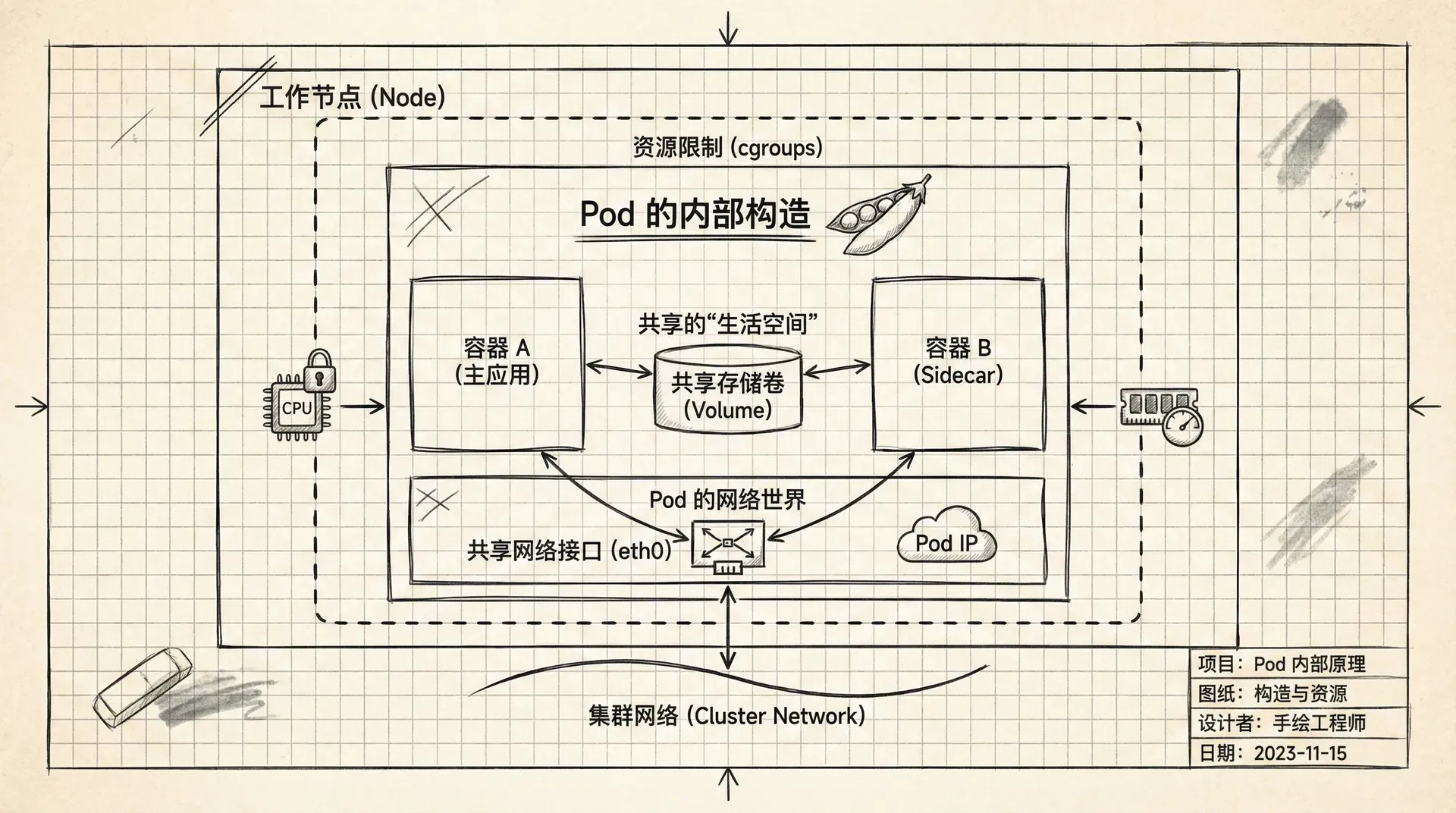
共享的“生活空间”
当一个 Pod 被创建时,它会建立一套自己独有的资源,而这个 Pod 里的所有容器都会共同享有这片“生活空间”。 这意味着它们共享同一个网络环境,包括IP地址和端口范围;它们拥有相同的主机名;它们可以访问同一个配置好的存储卷(Volume)来进行文件共享;并且它们可以利用标准的进程间通信(IPC)机制进行高效的交流。
你可能会好奇这是如何实现的。在底层,Kubernetes(在使用 Docker 作为容器运行时的情况下)会先创建一个叫做 pause 的特殊容器。
这个 pause 容器的作用就是建立并持有上述所有的“共享资源”(在 Linux 中称为命名空间,如网络命名空间、UTS 命名空间等)。
然后,我们定义的业务容器才被创建并加入到这个环境中。所以,从某种意义上说,Pod 里的容器其实是“容器中的容器”,但这只是一个实现细节,你无需过分关注。
Pod 的网络世界
每个 Pod 在被创建时都会获得一个在集群内独一无二的 IP 地址。这个设计极大地简化了网络通信。
- Pod 内部通信:由于 Pod 内的所有容器共享同一个网络环境,它们之间通信就像在一台电脑上的不同进程间通信一样简单。它们可以通过
localhost加上对方的端口号直接访问彼此。例如,Web 容器可以通过localhost:8081访问在同一个 Pod 里的日志收集容器。 - Pod 之间通信:因为每个 Pod 都有自己的 IP 地址,并且这个 IP 地址在整个集群的 Pod 网络中都是可路由的,所以任何两个 Pod 之间都可以直接通过对方的 IP 地址进行通信,无需进行复杂的端口映射(NAT)。
Pod 与资源限制 (cgroups)
虽然 Pod 内的容器共享很多资源,但为了防止某个“贪吃”的容器耗尽节点的所有资源,影响到其他邻居,Kubernetes 允许我们为每个容器单独设置资源限制。这是通过 Linux 内核的一个强大功能——控制组(cgroups) 来实现的。
你可以为 Pod 中的每个容器分别定义它能使用的 CPU 和内存的上限。例如,在一个包含 Web 应用和日志收集器的 Pod 中,你可以给日志收集器容器设置一个较低的资源限制(比如 0.1 CPU 核心和 128MB 内存), 而给主 Web 应用分配更多的资源(比如 1 CPU 核心和 512MB 内存)。这样即使日志收集器在处理大量日志时消耗较多资源,也不会影响到核心 Web 服务的性能,从而保证主应用的稳定性。这是一个非常灵活且强大的功能。
Pod 的生命周期
Pod 从创建到消亡会经历几个不同的阶段。当你通过 kubectl 提交了 Pod 的定义后,它首先进入 Pending(准备中)状态。这时,Kubernetes 正在为它寻找合适的节点,并让节点上的 Kubelet 准备容器镜像。
一旦所有准备工作就绪,容器成功启动,Pod 就会进入 Running(运行中)状态。如果 Pod 里的应用完成了它的任务并正常退出,Pod 会进入 Succeeded(已成功)状态。如果中途发生错误导致无法启动或运行失败,它则会进入 Failed(已失败)状态。
Pod 是“脆弱的”,它们随时可能因为节点故障或其他原因而“死亡”。我们应该像对待“牛群”而不是“宠物”一样对待它们。当一个 Pod 死去时,我们不应该去修复它,而是应该创建一个全新的 Pod 来替代它。因此,千万不要在 Pod 内部存储重要状态,也不要依赖某个特定 Pod 的 IP 地址。
正是因为 Pod 本身是不可靠的,我们通常不会直接创建单个的 Pod。在生产环境中,我们总是通过更高级别的控制器(如 Deployment、StatefulSet)来管理 Pod,这些控制器能提供自动扩缩容、故障自愈和滚动更新等强大的功能。
与 Pod 的第一次亲密接触
理论说完了,现在让我们卷起袖子,亲自创建一个 Pod!
Pod 的“设计图”:YAML 清单
我们将使用下面的 YAML 文件来定义我们的第一个 Pod。你可以将它保存为 pod.yml。
yaml
apiVersion: v1
kind: Pod
metadata:
name: hello-pod
namespace: default
labels:
zone: prod
version: v1
spec:
containers:
- name: hello-ctr
image: nigelpoulton/k8sbook:latest
ports:
- containerPort: 8080让我们来更详细地解读一下这份“设计图”:
apiVersion: v1:指定了我们使用的 Kubernetes API 的版本。它的格式通常是<api-group>/<version>。然而,Pod 属于最核心的 API 组,名为core,这个组比较特殊,在书写时可以省略组名,所以我们直接写v1。对于其他资源,你可能会看到类似apps/v1(用于 Deployment)或storage.k8s.io/v1(用于 StorageClass)这样的写法。kind: Pod:明确指出我们要创建的资源类型是 Pod。metadata:这里是 Pod 的元数据,即“身份信息”。name:hello-pod,这是 Pod 的名字,在同一个命名空间内必须是唯一的。namespace:default,指定了 Pod 所属的命名空间。命名空间是逻辑上隔离集群资源的一种方式,可以把它想象成一个虚拟的子集群。如果不指定,默认就是default。在生产环境中,强烈建议使用不同的命名空间来组织资源。labels: 标签是附加到资源上的键值对,对于资源的筛选和组织至关重要。
spec:这是 Pod 的“规格说明”,定义了 Pod 的期望状态。这里我们定义了一个名为hello-ctr的容器,它使用了nigelpoulton/k8sbook:latest这个 Docker 镜像,并声明了容器会监听8080端口。
部署并观察你的 Pod
现在,使用 kubectl 命令来将这份蓝图提交给 Kubernetes 集群。
shell
$ kubectl apply -f pod.yml
pod/hello-pod created虽然系统提示“created”,但这不代表 Pod 已经可以工作了。我们可以用下面的命令来查看它的状态。
shell
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
hello-pod 0/1 ContainerCreating 0 9sget 命令还有一些有用的参数可以提供更多信息。例如,使用 -o wide 参数可以看到 Pod 被调度到了哪个节点上,以及它的 IP 地址。
shell
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE ...
hello-pod 1/1 Running 0 2m 10.1.0.21 k8s-node-1 ...深入 Pod 内部一探究竟
要想获得最详细的信息,kubectl describe 是你的好朋友。它会像一份详细的“体检报告”一样,展示 Pod 的所有信息。
shell
$ kubectl describe pod hello-pod
Name: hello-pod
Namespace: default
Node: k8s-node-1/192.168.1.101
...你甚至可以用 -o yaml 参数,从集群中取回这个 Pod 完整的 YAML 描述,这其中不仅包含了你最初定义的“期望状态”(spec),还包含了集群实时观察到的“当前状态”(status)。
如果你想进入 Pod 内部执行命令,可以使用 kubectl exec。
shell
$ kubectl exec -it hello-pod -- sh
# curl localhost:8080
<html>...Yo Pluralsighters!!!...</html>这里的 -it 参数很重要,-i 表示保持标准输入(STDIN)打开,-t 表示分配一个伪终端(pseudo-TTY),两者结合起来才能获得一个交互式的 Shell 会话。-- 后面的 sh 是你希望在容器内执行的命令。如果 Pod 内有多个容器,你需要使用 --container 或 -c 参数来指定要进入哪个容器,例如:kubectl exec -it my-pod -c my-container -- bash。
要查看容器的标准输出日志,可以使用 kubectl logs。
shell
$ kubectl logs hello-pod清理战场
体验完毕后,别忘了清理我们刚刚创建的资源。
shell
$ kubectl delete -f pod.yml
pod "hello-pod" deleted小结
在这节课中,我们了解到 Pod 是 Kubernetes 中最基本的调度单元。
每个 Pod 都有自己独立的 IP 地址,并且可以包含一个或多个容器。
我们总是通过声明式的 YAML 文件来定义 Pod,并通过 kubectl 将其部署到集群中。
最重要的是,我们认识到 Pod 是脆弱的,通常需要依赖更高级别的控制器来保证应用的健壮性。