并发编程
在我们日常生活中,其实“并发”这个词并不神秘。想象一下我们在家里做饭:一边煮饭,一边炒菜,还能顺手洗点水果。每件事都像是一个“小工人”在同时工作,互不干扰,但最终都为一顿美味的晚餐服务。 这种把一件大事拆分成多个可以同时进行的小任务,就是并发的思想。
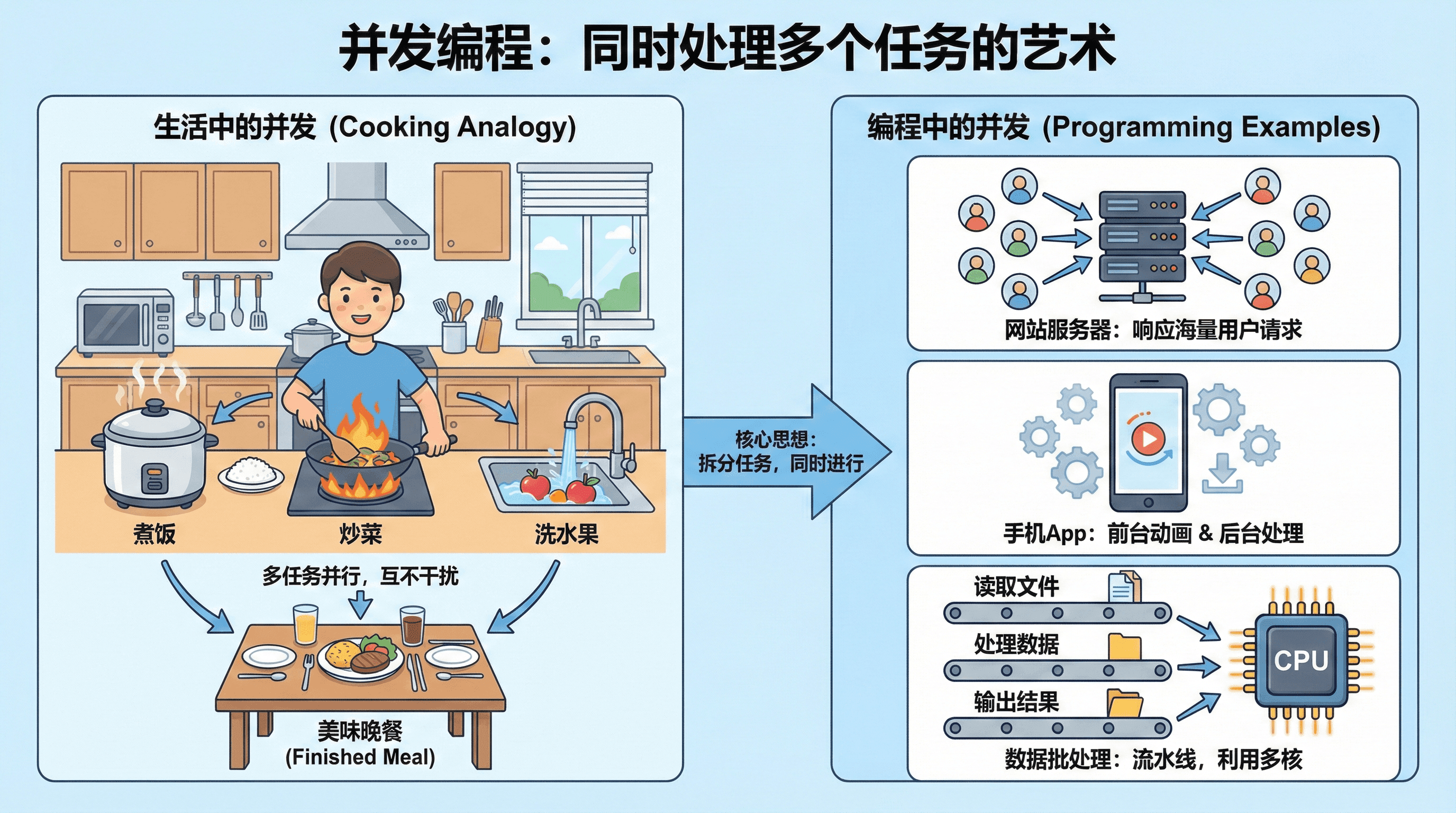
在现代编程里,并发编程变得越来越重要。比如,网站服务器要同时响应成千上万的用户请求;我们的手机App在界面上展示动画的同时,还要在后台下载数据或者处理消息。 甚至像批量处理数据这种看似简单的任务,也会用并发来加快速度,比如一边读取文件,一边处理数据,一边输出结果。这样可以充分利用现在电脑的多核处理器,让每个“核心”都不闲着。
Goroutines
在Go语言中,每个并发执行的活动称为一个goroutine。想象一下,我们在同时做几件事情:一边煮咖啡,一边听音乐,一边查看邮件。 在传统的顺序程序中,我们必须先完成一件事,再开始下一件。但在Go的并发世界中,我们可以同时进行多个活动。
Goroutine是Go语言中的轻量级线程。如果我们在其他语言中使用过线程,就可以将goroutine理解为更轻便、更高效的线程。 与操作系统线程相比,goroutine的创建和销毁成本极低,我们可以轻松创建成千上万个goroutine而不会耗尽系统资源。
创建Goroutine
当我们的Go程序启动时,它只有一个goroutine——调用main函数的那个,我们称它为主goroutine。要创建新的goroutine,只需在函数调用前加上关键字go:
go
// 普通函数调用 - 会阻塞等待完成
processData()
// 创建新的goroutine - 立即返回,不等待
go processData()为了更好地理解goroutine的用法,我们可以结合一个生活化的场景来举例说明。 比如说,我们要开发一个文件管理工具,这个工具不仅要实时监控文件的变化,还要持续记录系统日志,同时还要响应用户的各种输入操作。 每一项任务都可以独立进行,互不干扰,这正是并发的魅力所在。接下来,我们就用Go语言的goroutine来模拟这样一个多任务并行的系统。
go
package main
import (
"fmt"
"time"
"strings"
)
func main() {
// 启动文件监控goroutine
go monitorFiles()
// 启动日志记录goroutine
go logActivity()
// 主goroutine处理用户输入
processUserInput()
}
func monitorFiles() {
for {
fmt.Println("📁 监控文件系统变化...")
time.Sleep(2 * time.Second)
}
}
func logActivity() {
for {
fmt.Println("📝 记录系统活动...")
time.Sleep(1 * time.Second)
}
}
func processUserInput() {
fmt.Println("🎯 开始处理用户输入...")
time.Sleep(5 * time.Second)
fmt.Println("✅ 用户输入处理完成")
}运行这个程序,我们会看到三个活动同时进行:
console
🎯 开始处理用户输入...
📁 监控文件系统变化...
📝 记录系统活动...
📝 记录系统活动...
📁 监控文件系统变化...
📝 记录系统活动...
📝 记录系统活动...
📁 监控文件系统变化...
✅ 用户输入处理完成接下来,我们通过一个具体的例子来详细说明:在面对大量需要处理的数据时,如何利用goroutine实现并行计算,从而显著提升程序的执行效率。
go
package main
import (
"fmt"
"time"
"sync"
)
func main() {
start := time.Now()
// 创建数据批次
data := make([]int, 1000)
for i := range data {
data[i] = i
}
// 使用goroutines并行处理数据
results := processDataConcurrently(data)
fmt.Printf("处理完成!耗时: %v\n", time.Since(start))
fmt.Printf("处理了 %d 个数据项\n", len(results))
}
func processDataConcurrently(data []int) []int {
const numWorkers = 4
batchSize := len(data) / numWorkers
var wg sync.WaitGroup
results := make([]int, len(data))
for i := 0; i < numWorkers; i++ {
wg.Add(1)
start := i * batchSize
end := start + batchSize
if i == numWorkers-1 {
end = len(data)
}
go func(start, end int) {
defer wg.Done()
for j := start; j < end; j++ {
// 模拟复杂的计算
time.Sleep(1 * time.Millisecond)
results[j] = data[j] * data[j] + 1
}
fmt.Printf("工作器处理了 %d 到 %d 的数据\n", start, end-1)
}(start, end)
}
wg.Wait()
return results
}这个例子展示了如何将大量数据分成多个批次,每个批次由一个goroutine处理。输出可能如下:
console
工作器处理了 250 到 499 的数据
工作器处理了 0 到 249 的数据
工作器处理了 500 到 749 的数据
工作器处理了 750 到 999 的数据
处理完成!耗时: 250ms
处理了 1000 个数据项用户界面响应性例子
在开发图形界面程序时,我们经常会遇到这样一种需求:既要执行一些耗时的后台任务,比如数据处理或网络请求,又希望界面能够持续响应用户的操作,不会出现卡顿。 这时候,goroutine 就派上了大用场。我们可以把耗时的操作放到 goroutine 里去执行,让主线程专注于界面更新和用户交互,这样用户体验就会非常流畅。 例如,假设我们正在做一个图片处理软件,用户点击“开始处理”按钮后,图片的处理过程可以放到 goroutine 里跑,而主界面还能正常响应用户的其他操作,比如点击菜单、拖动窗口等。
go
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("🚀 启动应用程序...")
// 启动后台任务,不阻塞主界面
go performBackgroundTask()
// 主界面保持响应
for i := 0; i < 5; i++ {
fmt.Printf("💻 界面保持响应... (%d/5)\n", i+1)
time.Sleep(500 * time.Millisecond)
}
fmt.Println("✅ 应用程序完成")
}
func performBackgroundTask() {
fmt.Println("🔄 开始后台任务...")
for i := 0; i < 10; i++ {
fmt.Printf("⏳ 后台任务进度: %d%%\n", (i+1)*10)
time.Sleep(200 * time.Millisecond)
}
fmt.Println("✅ 后台任务完成")
}运行结果:
console
🚀 启动应用程序...
💻 界面保持响应... (1/5)
🔄 开始后台任务...
⏳ 后台任务进度: 10%
💻 界面保持响应... (2/5)
⏳ 后台任务进度: 20%
💻 界面保持响应... (3/5)
⏳ 后台任务进度: 30%
💻 界面保持响应... (4/5)
⏳ 后台任务进度: 40%
💻 界面保持响应... (5/5)
⏳ 后台任务进度: 50%
⏳ 后台任务进度: 60%
⏳ 后台任务进度: 70%
⏳ 后台任务进度: 80%
⏳ 后台任务进度: 90%
⏳ 后台任务进度: 100%
✅ 后台任务完成
✅ 应用程序完成通过goroutines,我们可以轻松地将顺序程序转换为并发程序,充分利用多核处理器的能力,提高程序的性能和响应性。
示例:简单的并发任务调度器
在实际的软件开发中,我们经常需要同时处理多个任务。比如,一个在线商店的后台系统可能需要同时处理订单、更新库存、发送通知邮件,还要定期备份数据。如果这些任务都按顺序执行,用户等待的时间会很长,体验会很差。 接下来,我们通过一个简单的任务调度器来演示如何使用goroutine实现并发处理。这个调度器可以同时处理多个不同类型的任务,每个任务都在独立的goroutine中运行。
go
package main
import (
"fmt"
"sync"
"time"
)
// 任务类型定义
type Task struct {
ID int
Type string
Duration time.Duration
}
func main() {
// 创建任务队列
tasks := []Task{
{ID: 1, Type: "数据处理", Duration: 2 * time.Second},
{ID: 2, Type: "文件备份", Duration: 3 * time.Second},
{ID: 3, Type: "发送邮件", Duration: 1 * time.Second},
{ID: 4, Type: "更新缓存", Duration: 2 * time.Second},
{ID: 5, Type: "生成报告", Duration: 4 * time.Second},
}
fmt.Println("🚀 开始并发任务调度...")
start := time.Now()
// 使用WaitGroup等待所有任务完成
var wg sync.WaitGroup
for _, task := range tasks {
wg.Add(1)
go processTask(task, &wg)
}
// 等待所有任务完成
wg.Wait()
fmt.Printf("✅ 所有任务完成!总耗时: %v\n", time.Since(start))
}
func processTask(task Task, wg *sync.WaitGroup) {
defer wg.Done()
fmt.Printf("📋 开始处理任务 %d (%s)...\n", task.ID, task.Type)
// 模拟任务处理时间
time.Sleep(task.Duration)
fmt.Printf("✅ 任务 %d (%s) 完成\n", task.ID, task.Type)
}运行这个程序,我们会看到所有任务几乎同时开始,但完成时间不同:
console
🚀 开始并发任务调度...
📋 开始处理任务 1 (数据处理)...
📋 开始处理任务 2 (文件备份)...
📋 开始处理任务 3 (发送邮件)...
📋 开始处理任务 4 (更新缓存)...
📋 开始处理任务 5 (生成报告)...
✅ 任务 3 (发送邮件) 完成
✅ 任务 1 (数据处理) 完成
✅ 任务 4 (更新缓存) 完成
✅ 任务 2 (文件备份) 完成
✅ 任务 5 (生成报告) 完成
✅ 所有任务完成!总耗时: 4.1s如果我们不使用并发,而是按顺序处理这些任务,总耗时会是所有任务时间的总和(12秒)。通过使用goroutine,我们大大提高了程序的效率。
带资源限制的并发处理
在实际开发过程中,我们经常会遇到这样一种情况:虽然并发可以大幅提升程序的处理效率,但如果同时启动太多goroutine,反而可能让系统资源吃紧,甚至导致程序崩溃。 举个例子,假如我们要批量处理成百上千个文件,如果不加限制地为每个文件都启动一个goroutine,内存和CPU很快就会被耗尽。
为了解决这个问题,我们可以采用“信号量”机制来给并发数量设定一个上限。信号量本质上就是一个带缓冲的channel,我们可以把它想象成一个容量有限的通道,只有拿到“通行证”的goroutine才能进入工作。 当通道满了,新的goroutine就会被阻塞,直到有任务完成释放出“通行证”,下一个才能继续。
下面我们就用一个具体的例子来演示如何用信号量来控制并发的goroutine数量,让我们的程序既高效又安全。
go
package main
import (
"fmt"
"sync"
"time"
)
func main() {
tasks := []Task{
{ID: 1, Type: "下载文件", Duration: 2 * time.Second},
{ID: 2, Type: "处理图片", Duration: 3 * time.Second},
{ID: 3, Type: "压缩数据", Duration: 1 * time.Second},
{ID: 4, Type: "上传结果", Duration: 2 * time.Second},
{ID: 5, Type: "清理临时文件", Duration: 1 * time.Second},
{ID: 6, Type: "发送通知", Duration: 1 * time.Second},
}
fmt.Println("🚀 开始限制并发数的任务处理...")
start := time.Now()
// 限制最多同时运行3个任务
const maxWorkers = 3
semaphore := make(chan struct{}, maxWorkers)
var wg sync.WaitGroup
for _, task := range tasks {
wg.Add(1)
go processTaskWithLimit(task, &wg, semaphore)
}
wg.Wait()
fmt.Printf("✅ 所有任务完成!总耗时: %v\n", time.Since(start))
}
func processTaskWithLimit(task Task, wg *sync.WaitGroup, semaphore chan struct{}) {
defer wg.Done()
// 获取信号量(限制并发数)
semaphore <- struct{}{}
defer func() { <-semaphore }() // 释放信号量
fmt.Printf("📋 开始处理任务 %d (%s)...\n", task.ID, task.Type)
time.Sleep(task.Duration)
fmt.Printf("✅ 任务 %d (%s) 完成\n", task.ID, task.Type)
}这个版本通过信号量控制最多只有3个任务同时运行,输出可能如下:
console
🚀 开始限制并发数的任务处理...
📋 开始处理任务 1 (下载文件)...
📋 开始处理任务 2 (处理图片)...
📋 开始处理任务 3 (压缩数据)...
✅ 任务 3 (压缩数据) 完成
📋 开始处理任务 4 (上传结果)...
✅ 任务 1 (下载文件) 完成
📋 开始处理任务 5 (清理临时文件)...
✅ 任务 2 (处理图片) 完成
📋 开始处理任务 6 (发送通知)...
✅ 任务 5 (清理临时文件) 完成
✅ 任务 4 (上传结果) 完成
✅ 任务 6 (发送通知) 完成
✅ 所有任务完成!总耗时: 5.2s通过这个简单的例子,我们可以看到goroutine如何帮助我们构建高效的并发程序。无论是处理网络请求、执行后台任务,还是进行数据计算,goroutine都能让我们的程序更加高效和响应迅速。
Channels
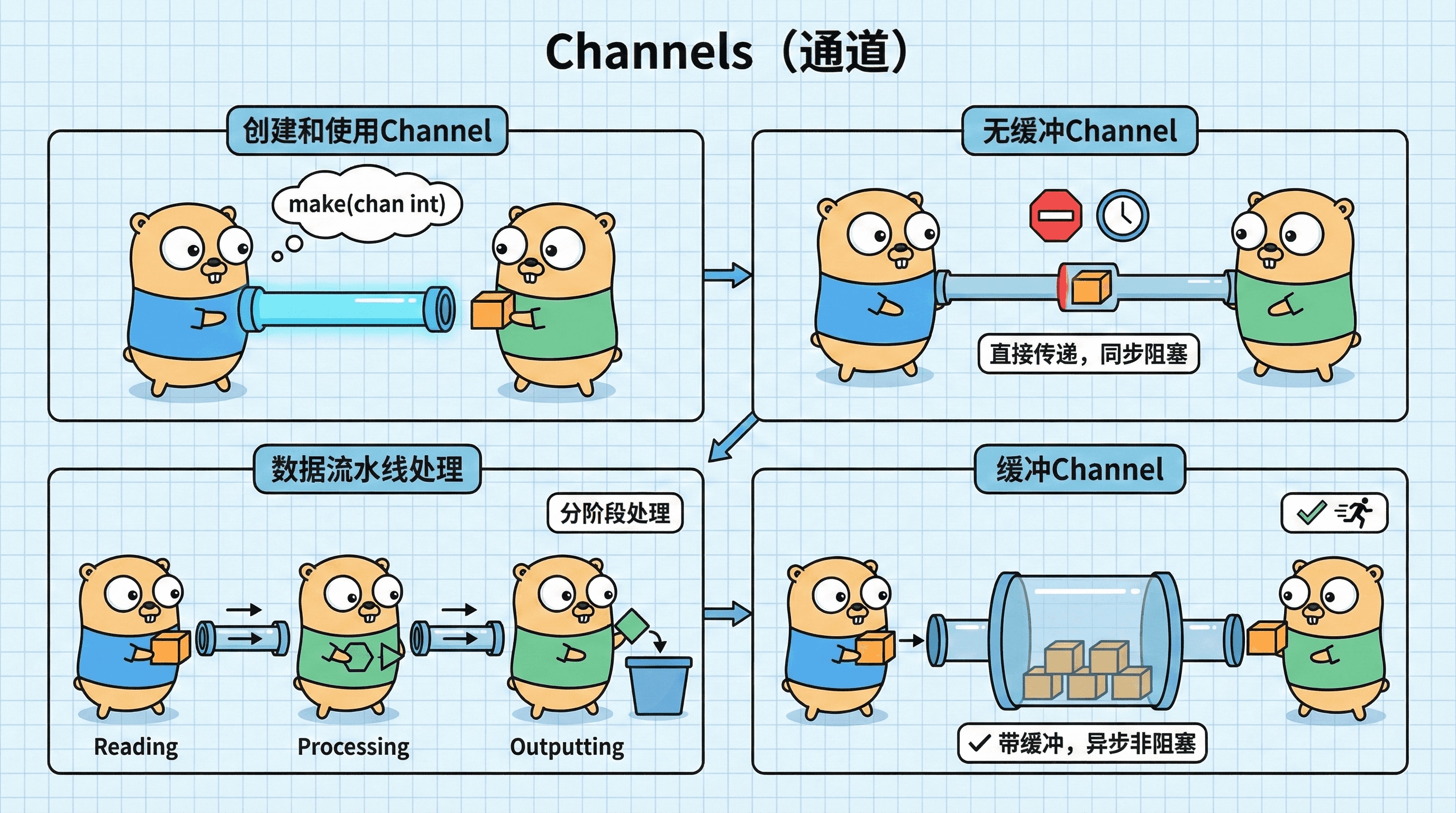
在Go语言中,goroutine 是程序并发执行的基本单元,而 channel 则是实现 goroutine 之间安全通信与数据同步的核心机制。 可以将 channel 看作连接多个并发任务的数据通道,通过它,不同 goroutine 能以类型安全、无锁的方式进行消息传递和协作,有效避免共享内存带来的竞争问题。
Channel是一种类型化的管道,允许一个goroutine向另一个goroutine发送特定类型的值。每个channel都有一个元素类型,比如chan int表示只能传输整数类型的channel。
创建和使用Channel
如果我们希望让不同的goroutine之间能够安全地传递数据,就需要用到channel。那我们该如何创建一个channel呢?其实很简单,我们只需要用Go内置的make函数来完成。
比如说,如果我们想让多个任务协作处理整数数据,可以这样声明和初始化一个channel:
go
ch := make(chan int) // 创建一个无缓冲的整数channelChannel支持三种基本操作:发送、接收和关闭。发送和接收都使用<-操作符:
go
ch <- 42 // 发送值到channel
value := <-ch // 从channel接收值
close(ch) // 关闭channel无缓冲Channel
无缓冲channel可以理解为“面对面”直接交接物品的场景。比如我们在搬家时,一个人把箱子递给另一个人,只有当对方伸手接住,递的人才能松手继续搬下一个。这种机制保证了每次数据的传递都是同步的:发送方必须等到接收方准备好,接收方也必须等到发送方真的有东西要给。
这种同步特性在并发编程中非常有用。它不仅能保证数据不会丢失,还能让不同的goroutine在关键时刻“握手”,实现协作。比如我们可以用无缓冲channel来实现两个任务的严格先后顺序,或者让主程序等待某个后台任务完成。
下面我们用一个生活化的例子来演示无缓冲channel的同步效果:
go
package main
import (
"fmt"
"time"
)
func main() {
// 创建一个无缓冲channel
messageChan := make(chan string)
// 启动发送者goroutine
go sender(messageChan)
// 启动接收者goroutine
go receiver(messageChan)
// 等待一段时间让goroutines完成
time.Sleep(3 * time.Second)
fmt.Println("程序结束")
}
func sender(ch chan string) {
messages := []string{"你好", "世界", "Go语言", "并发编程"}
for _, msg := range messages {
fmt.Printf("📤 发送: %s\n", msg)
ch <- msg // 发送消息到channel
time.Sleep(500 * time.Millisecond)
}
close(ch) // 发送完成后关闭channel
fmt.Println("✅ 发送者完成")
}
func receiver(ch chan string) {
for {
msg, ok := <-ch
if !ok {
fmt.Println("📭 Channel已关闭,接收者退出")
return
}
fmt.Printf("📥 接收: %s\n", msg)
time.Sleep(300 * time.Millisecond)
}
}运行这个程序,我们会看到发送和接收是同步进行的:
console
📤 发送: 你好
📥 接收: 你好
📤 发送: 世界
📥 接收: 世界
📤 发送: Go语言
📥 接收: Go语言
📤 发送: 并发编程
📥 接收: 并发编程
✅ 发送者完成
📭 Channel已关闭,接收者退出
程序结束数据流水线处理
Channel(通道)在并发编程中有一个非常实用的场景,就是用来搭建“数据流水线”。 我们可以把流水线想象成工厂里的传送带:原材料从一端进入,经过多个工序的加工,最后变成成品。每个工序都由独立的工人负责,这些工人可以同时工作,互不干扰。
在Go语言中,我们可以用多个goroutine分别负责流水线的不同阶段,每个阶段之间通过channel传递数据。这样一来,数据就像在传送带上一样,自动流转到下一个处理环节。 比如,我们可以先生成一批原始数据,然后对数据进行加工处理,最后再格式化输出,每一步都可以并发进行,互不阻塞。
接下来,我们用一个具体的例子来演示如何用channel和goroutine实现一个三段式的数据流水线:
go
package main
import (
"fmt"
"strings"
)
func main() {
// 创建流水线的各个阶段
rawData := make(chan string)
processedData := make(chan string)
finalData := make(chan string)
// 启动数据生成器
go dataGenerator(rawData)
// 启动数据处理器
go dataProcessor(rawData, processedData)
// 启动数据格式化器
go dataFormatter(processedData, finalData)
// 主goroutine负责输出结果
for result := range finalData {
fmt.Printf("📊 最终结果: %s\n", result)
}
}
func dataGenerator(out chan<- string) {
defer close(out)
data := []string{
"apple,red,fruit",
"banana,yellow,fruit",
"carrot,orange,vegetable",
"tomato,red,vegetable",
}
for _, item := range data {
fmt.Printf("🌱 生成数据: %s\n", item)
out <- item
}
}
func dataProcessor(in <-chan string, out chan<- string) {
defer close(out)
for item := range in {
// 模拟数据处理
parts := strings.Split(item, ",")
if len(parts) == 3 {
processed := fmt.Sprintf("%s是%s色的%s", parts[0], parts[1], parts[2])
fmt.Printf("🔧 处理数据: %s -> %s\n", item, processed)
out <- processed
}
}
}
func dataFormatter(in <-chan string, out chan<- string) {
defer close(out)
for item := range in {
// 添加格式化
formatted := fmt.Sprintf("【%s】", item)
fmt.Printf("✨ 格式化: %s -> %s\n", item, formatted)
out <- formatted
}
}运行结果:
console
🌱 生成数据: apple,red,fruit
🔧 处理数据: apple,red,fruit -> apple是红色的fruit
✨ 格式化: apple是红色的fruit -> 【apple是红色的fruit】
📊 最终结果: 【apple是红色的fruit】
🌱 生成数据: banana,yellow,fruit
🔧 处理数据: banana,yellow,fruit -> banana是黄色的fruit
✨ 格式化: banana是黄色的fruit -> 【banana是黄色的fruit】
📊 最终结果: 【banana是黄色的fruit】
🌱 生成数据: carrot,orange,vegetable
🔧 处理数据: carrot,orange,vegetable -> carrot是橙色的vegetable
✨ 格式化: carrot是橙色的vegetable -> 【carrot是橙色的vegetable】
📊 最终结果: 【carrot是橙色的vegetable】
🌱 生成数据: tomato,red,vegetable
🔧 处理数据: tomato,red,vegetable -> tomato是红色的vegetable
✨ 格式化: tomato是红色的vegetable -> 【tomato是红色的vegetable】
📊 最终结果: 【tomato是红色的vegetable】缓冲Channel
我们可以把缓冲 channel 想象成一个带格子的信箱。每当我们往 channel 里发送数据时,只要信箱还有空位,数据就会被直接放进去,不需要等接收方马上来取。 例如,如果我们创建了一个容量为 3 的缓冲 channel,那么最多可以连续发送 3 条消息而不会阻塞。只有当信箱满了,发送方才会被阻塞,直到有接收方把消息取走腾出空间。 这样,发送和接收就可以在一定程度上解耦,提高了程序的并发效率。
go
package main
import (
"fmt"
"time"
)
func main() {
// 创建一个容量为3的缓冲channel
bufferChan := make(chan string, 3)
// 启动快速发送者
go fastSender(bufferChan)
// 启动慢速接收者
go slowReceiver(bufferChan)
// 等待完成
time.Sleep(5 * time.Second)
fmt.Println("程序结束")
}
func fastSender(ch chan<- string) {
messages := []string{"消息1", "消息2", "消息3", "消息4", "消息5"}
for i, msg := range messages {
fmt.Printf("📤 发送 %d: %s\n", i+1, msg)
ch <- msg
time.Sleep(200 * time.Millisecond) // 快速发送
}
close(ch)
fmt.Println("✅ 发送者完成")
}
func slowReceiver(ch <-chan string) {
for {
msg, ok := <-ch
if !ok {
fmt.Println("📭 接收者完成")
return
}
fmt.Printf("📥 接收: %s\n", msg)
time.Sleep(800 * time.Millisecond) // 慢速接收
}
}运行结果:
console
📤 发送 1: 消息1
📤 发送 2: 消息2
📤 发送 3: 消息3
📥 接收: 消息1
📤 发送 4: 消息4
📥 接收: 消息2
📤 发送 5: 消息5
📥 接收: 消息3
✅ 发送者完成
📥 接收: 消息4
📥 接收: 消息5
📭 接收者完成
程序结束注意观察:发送者可以连续发送前3个消息而不被阻塞,因为缓冲channel有足够的空间。只有当缓冲区满了之后,发送者才会等待接收者处理消息。
并行循环
在实际编程中,我们经常需要对大量数据进行相同的操作。比如,我们需要处理一批图片、计算一组数字的平方根,或者验证多个文件的完整性。如果这些操作之间没有依赖关系,我们就可以使用并行循环来大大提高处理速度。 让我们通过几个简单的例子来学习如何将普通的循环转换为并行循环。
简单的并行计算
我们先从一个非常常见的需求入手:假设我们有一组整数,需要分别计算它们的平方。通常情况下,我们会用一个for循环,依次处理每个数字。 但如果这些计算之间互不影响,其实完全可以让它们同时进行,这样整体速度会快很多。接下来,我们就用并行的方式来处理这批数字的平方运算,看看并发能带来多大的提升。
go
package main
import (
"fmt"
"sync"
"time"
)
func main() {
numbers := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
fmt.Println("🚀 开始并行计算...")
start := time.Now()
// 顺序计算
sequentialResults := make([]int, len(numbers))
for i, num := range numbers {
sequentialResults[i] = num * num
time.Sleep(100 * time.Millisecond) // 模拟计算时间
}
fmt.Printf("⏱️ 顺序计算耗时: %v\n", time.Since(start))
// 并行计算
start = time.Now()
parallelResults := parallelSquare(numbers)
fmt.Printf("⚡ 并行计算耗时: %v\n", time.Since(start))
fmt.Printf("📊 结果: %v\n", parallelResults)
}
func parallelSquare(numbers []int) []int {
results := make([]int, len(numbers))
var wg sync.WaitGroup
for i, num := range numbers {
wg.Add(1)
go func(index int, value int) {
defer wg.Done()
// 模拟计算时间
time.Sleep(100 * time.Millisecond)
results[index] = value * value
fmt.Printf("🔢 计算 %d 的平方 = %d\n", value, value*value)
}(i, num)
}
wg.Wait()
return results
}使用Channel收集结果
在实际开发中,很多时候我们希望每当某个任务有结果时就能立刻处理,而不是等到所有任务都结束后再统一处理。 比如说,我们在并发下载多个网页时,希望哪个网页先下载完就先显示它的结果,这样可以让程序更加高效和灵活。 这个时候,channel就非常适合用来做并发结果的实时收集。我们来看一个具体的例子,演示如何用channel边处理边收集多个任务的执行结果:
go
package main
import (
"fmt"
"sync"
"time"
)
func main() {
urls := []string{
"https://example.com/page1",
"https://example.com/page2",
"https://example.com/page3",
"https://example.com/page4",
"https://example.com/page5",
}
fmt.Println("🌐 开始并行下载网页...")
start := time.Now()
results := downloadPagesParallel(urls)
fmt.Printf("⏱️ 总耗时: %v\n", time.Since(start))
for _, result := range results {
if result.Success {
fmt.Printf("✅ %s: 下载成功, 大小: %d 字节\n",
result.URL, result.Size)
} else {
fmt.Printf("❌ %s: %s\n", result.URL, result.Error)
}
}
}
type DownloadResult struct {
URL string
Success bool
Size int
Error string
}
func downloadPagesParallel(urls []string) []DownloadResult {
results := make(chan DownloadResult, len(urls))
var wg sync.WaitGroup
// 启动下载协程
for _, url := range urls {
wg.Add(1)
go func(pageURL string) {
defer wg.Done()
// 模拟下载过程
time.Sleep(time.Duration(300+len(pageURL)*10) * time.Millisecond)
// 模拟成功或失败
success := len(pageURL)%4 != 0 // 每4个URL失败一个
var result DownloadResult
if success {
result = DownloadResult{
URL: pageURL,
Success: true,
Size: 1024 + len(pageURL)*100,
}
} else {
result = DownloadResult{
URL: pageURL,
Success: false,
Error: "网络连接超时",
}
}
results <- result
}(url)
}
// 等待所有下载完成
go func() {
wg.Wait()
close(results)
}()
// 收集结果
var allResults []DownloadResult
for result := range results {
allResults = append(allResults, result)
}
return allResults
}限制并发数量
在如果我们让所有任务都同时启动goroutine,虽然可以最大化并发,但也可能因为goroutine数量过多而让内存、CPU等资源被迅速耗尽,甚至影响到系统的稳定性。 举个例子,假如我们要批量处理成百上千个文件,如果不加限制地为每个文件都启动一个goroutine,机器很快就会“吃不消”。 因此,我们通常会给并发的goroutine数量设定一个上限,比如只允许最多5个任务同时进行,等有任务完成后再让下一个任务加入,这样既能保证效率,又能保护系统资源不被过度占用。
go
package main
import (
"fmt"
"sync"
"time"
)
func main() {
tasks := make([]int, 20)
for i := range tasks {
tasks[i] = i + 1
}
fmt.Println("🔧 开始限制并发的任务处理...")
start := time.Now()
// 限制最多同时运行5个任务
results := processWithLimit(tasks, 5)
fmt.Printf("⏱️ 总耗时: %v\n", time.Since(start))
fmt.Printf("📊 处理了 %d 个任务\n", len(results))
}
func processWithLimit(tasks []int, maxConcurrency int) []int {
results := make([]int, len(tasks))
semaphore := make(chan struct{}, maxConcurrency)
var wg sync.WaitGroup
for i, task := range tasks {
wg.Add(1)
go func(index, value int) {
defer wg.Done()
// 获取信号量
semaphore <- struct{}{}
defer func() { <-semaphore }()
// 模拟处理时间
time.Sleep(200 * time.Millisecond)
// 处理任务
results[index] = value * value
fmt.Printf("✅ 处理任务 %d -> %d\n", value, value*value)
}(i, task)
}
wg.Wait()
return results
}并行循环是Go语言中非常强大的并发模式,它让我们能够充分利用多核处理器的能力,大大提高程序的执行效率。关键是要根据具体的应用场景选择合适的并发策略,并注意处理错误和资源管理。
go 并发调度可视仪
习题
- 在Go语言中,启动goroutine使用哪个关键字?
- 在Go语言中,用于goroutine之间通信的机制是?
- 在Go语言中,如何创建一个channel?
- 在Go语言中,用于channel发送和接收的操作符是?
- 在Go语言中,用于等待多个goroutine完成的同步原语是?
- 在Go语言中,哪些类型的channel可以关闭?
- 在Go语言中,用于处理多个channel操作的语句是?
- 在Go语言中,从无缓冲channel接收数据时,如果没有数据可接收,会发生什么?
9. 基础goroutine和channel练习
编写程序,使用goroutine并行处理字符串,并使用channel收集结果。
go
package main
import (
"fmt"
"strings"
"sync"
)
// 处理单个字符串
func processString(str string, resultChan chan<- string, wg *sync.WaitGroup) {
defer wg.Done()
// 转换为大写
upper := strings.ToUpper(str)
// 反转字符串
runes := []rune(str)
reversed := ""
for i := len(runes) - 1; i >= 0; i-- {
reversed += string(runes[i])
}
// 计算长度
length := len(str)
result := fmt.Sprintf("原字符串: %s, 大写: %s, 反转: %s, 长度: %d",
str, upper, reversed, length)
resultChan <- result
}
func main() {
strings := []string{"hello", "world", "golang", "concurrency"}
// 创建channel和WaitGroup
resultChan := make(chan string, len(strings))
var wg sync.WaitGroup
// 启动goroutine处理每个字符串
for _, str := range strings {
wg.Add(1)
go processString(str, resultChan, &wg)
}
// 等待所有goroutine完成
go func() {
wg.Wait()
close(resultChan)
}()
// 收集结果
fmt.Println("处理结果:")
for result := range resultChan {
fmt.Println(result)
}
}console
处理结果:
原字符串: hello, 大写: HELLO, 反转: olleh, 长度: 5
原字符串: world, 大写: WORLD, 反转: dlrow, 长度: 5
原字符串: golang, 大写: GOLANG, 反转: gnalog, 长度: 6
原字符串: concurrency, 大写: CONCURRENCY, 反转: ycnerrucnoc, 长度: 11说明:
- 使用
go关键字启动goroutine - 使用
make(chan Type)创建channel - 使用
sync.WaitGroup等待所有goroutine完成 defer wg.Done()确保goroutine完成时调用Done()- 使用
close(channel)关闭channel,for range会自动处理关闭的channel
10. 使用WaitGroup等待goroutine完成
编写程序,使用sync.WaitGroup等待多个goroutine完成。
go
package main
import (
"fmt"
"sync"
"time"
)
func worker(id int, wg *sync.WaitGroup) {
defer wg.Done() // goroutine完成时调用Done()
fmt.Printf("Worker %d 开始工作\n", id)
time.Sleep(time.Second) // 模拟工作
fmt.Printf("Worker %d 完成工作\n", id)
}
func main() {
var wg sync.WaitGroup
numWorkers := 3
// 启动多个goroutine
for i := 1; i <= numWorkers; i++ {
wg.Add(1) // 增加等待计数
go worker(i, &wg)
}
fmt.Println("等待所有worker完成...")
wg.Wait() // 等待所有goroutine完成
fmt.Println("所有worker已完成!")
}console
等待所有worker完成...
Worker 1 开始工作
Worker 2 开始工作
Worker 3 开始工作
Worker 1 完成工作
Worker 2 完成工作
Worker 3 完成工作
所有worker已完成!说明:
sync.WaitGroup用于等待一组goroutine完成Add(n)增加等待计数Done()减少等待计数(通常使用defer调用)Wait()阻塞直到等待计数为0- 注意传递
&wg(指针),而不是值
11. Channel发送和接收练习
编写程序,演示channel的基本发送和接收操作。
go
package main
import (
"fmt"
"time"
)
func sender(ch chan<- string) {
// 向channel发送数据
ch <- "消息1"
ch <- "消息2"
ch <- "消息3"
close(ch) // 关闭channel
}
func receiver(ch <-chan string) {
// 从channel接收数据
for msg := range ch {
fmt.Printf("接收到: %s\n", msg)
}
fmt.Println("Channel已关闭")
}
func main() {
// 创建无缓冲channel
ch := make(chan string)
// 启动发送者goroutine
go sender(ch)
// 在主goroutine中接收
receiver(ch)
// 演示有缓冲channel
fmt.Println("\n=== 有缓冲channel ===")
bufferedCh := make(chan int, 3)
// 发送数据(不会阻塞,因为有缓冲)
bufferedCh <- 1
bufferedCh <- 2
bufferedCh <- 3
fmt.Println("已发送3个数据到有缓冲channel")
// 接收数据
fmt.Printf("接收: %d\n", <-bufferedCh)
fmt.Printf("接收: %d\n", <-bufferedCh)
fmt.Printf("接收: %d\n", <-bufferedCh)
}console
接收到: 消息1
接收到: 消息2
接收到: 消息3
Channel已关闭
=== 有缓冲channel ===
已发送3个数据到有缓冲channel
接收: 1
接收: 2
接收: 3说明:
chan<- Type表示只能发送的channel<-chan Type表示只能接收的channelmake(chan Type)创建无缓冲channelmake(chan Type, size)创建有缓冲channel- 使用
close(channel)关闭channel for range会自动处理关闭的channel
12. Select语句处理多个channel
编写程序,使用select语句处理多个channel操作。
go
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan string)
ch2 := make(chan string)
// 启动两个goroutine发送数据
go func() {
time.Sleep(1 * time.Second)
ch1 <- "来自channel 1"
}()
go func() {
time.Sleep(2 * time.Second)
ch2 <- "来自channel 2"
}()
// 使用select处理多个channel
for i := 0; i < 2; i++ {
select {
case msg1 := <-ch1:
fmt.Printf("接收到: %s\n", msg1)
case msg2 := <-ch2:
fmt.Printf("接收到: %s\n", msg2)
case <-time.After(3 * time.Second):
fmt.Println("超时")
}
}
// 演示非阻塞select
fmt.Println("\n=== 非阻塞select ===")
select {
case msg := <-ch1:
fmt.Printf("接收到: %s\n", msg)
default:
fmt.Println("没有数据可接收(非阻塞)")
}
}console
接收到: 来自channel 1
接收到: 来自channel 2
=== 非阻塞select ===
没有数据可接收(非阻塞)说明:
select语句用于处理多个channel操作- 如果有多个case就绪,select会随机选择一个
default分支用于非阻塞操作time.After()可以用于超时处理- select常用于实现超时、非阻塞操作等场景
13. 并行计算练习
编写程序,使用goroutine并行计算一组数字的平方。
go
package main
import (
"fmt"
"sync"
)
type Result struct {
Number int
Square int
}
func calculateSquare(num int, resultChan chan<- Result, wg *sync.WaitGroup) {
defer wg.Done()
square := num * num
resultChan <- Result{Number: num, Square: square}
}
func main() {
numbers := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
resultChan := make(chan Result, len(numbers))
var wg sync.WaitGroup
// 启动goroutine并行计算
for _, num := range numbers {
wg.Add(1)
go calculateSquare(num, resultChan, &wg)
}
// 等待所有计算完成
go func() {
wg.Wait()
close(resultChan)
}()
// 收集结果
fmt.Println("计算结果:")
results := make([]Result, 0)
for result := range resultChan {
results = append(results, result)
}
// 输出结果
for _, r := range results {
fmt.Printf("%d² = %d\n", r.Number, r.Square)
}
}console
计算结果:
1² = 1
2² = 2
3² = 9
4² = 16
5² = 25
6² = 36
7² = 49
8² = 64
9² = 81
10² = 100说明:
- 使用goroutine并行处理多个任务
- 使用channel收集结果
- 使用WaitGroup等待所有goroutine完成
- 注意结果的顺序可能不是原始顺序(因为并发执行)
- 如果需要保持顺序,可以使用索引或其他方法