目标检测
图像分类回答“这是什么?”,目标检测回答“什么在哪里?”。自动驾驶需要检测行人、车辆、交通标志的位置;安防系统需要检测异常行为的区域;医疗影像分析需要定位病变。目标检测不仅识别物体类别,还要用边界框标出位置,是计算机视觉最实用的任务之一。
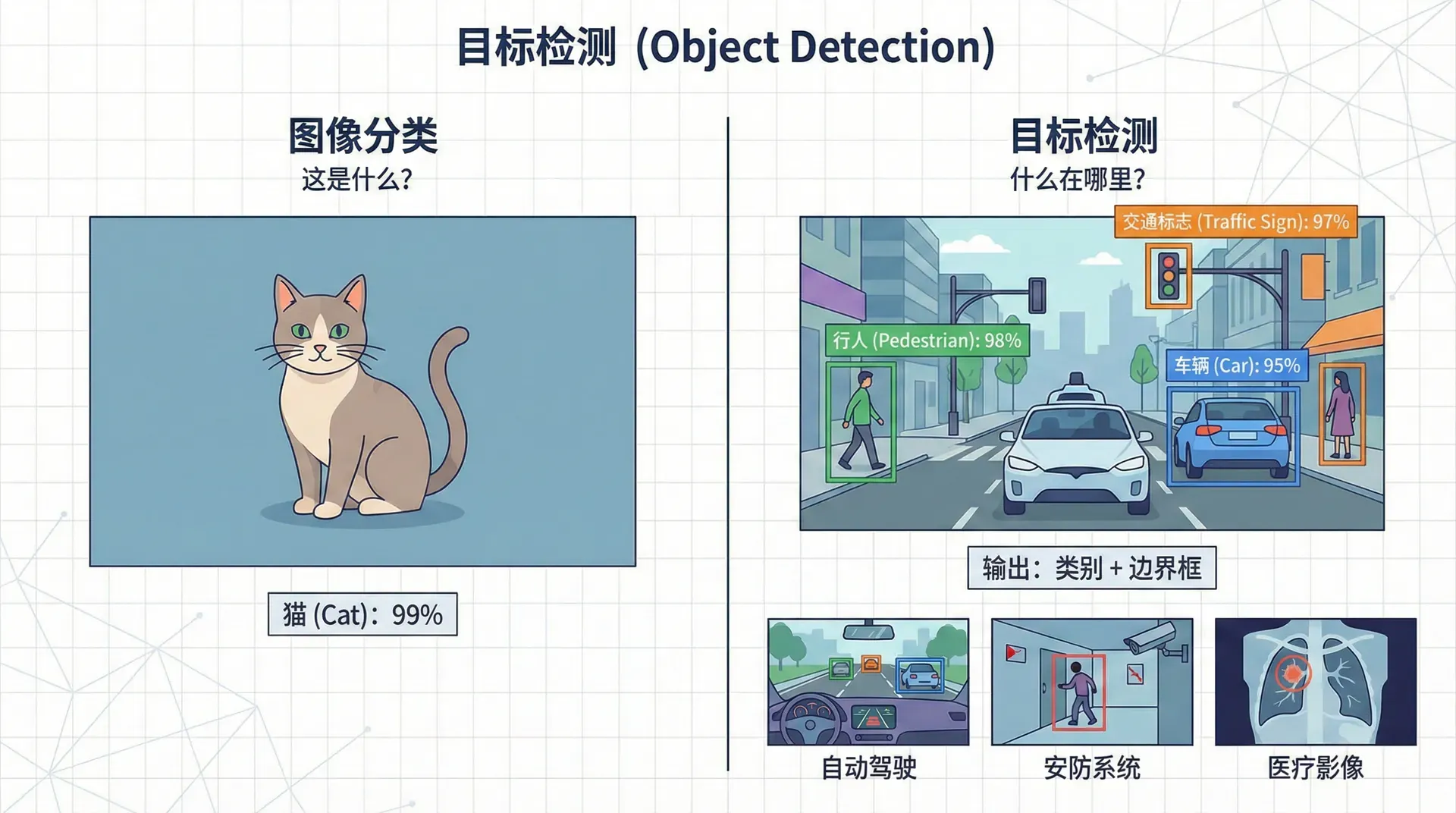
从分类到检测
最简单的情况是目标定位(Object Localization):图像中只有一个物体,输出它的类别和位置。
输出不只是类别标签,还包括边界框(Bounding Box)的四个坐标:
- :是否有物体(0或1)
- :边界框中心坐标
- :边界框高度和宽度
损失函数需要同时考虑分类和定位:
边界框损失通常用L2(均方误差)或Smooth L1。
IoU:评估定位质量
如何判断预测的边界框好不好?交并比(Intersection over Union, IoU)是标准指标。
IoU范围在[0, 1]:
- IoU = 1:完美匹配
- IoU > 0.5:通常认为是"正确"的检测
- IoU < 0.5:认为检测失败
python
def compute_iou(box1, box2):
"""
计算两个边界框的IoU
box: [x1, y1, x2, y2] 左上角和右下角坐标
"""
# 计算交集区域
x1_inter = max(box1[0], box2[0])
y1_inter = max(box1[1], box2[1])
x2_inter = min(box1[2], box2[2])
y2_inter = min(box1[3], box2[3
非极大值抑制:去除重复检测
目标检测算法可能对同一个物体输出多个边界框(略微不同的位置)。非极大值抑制(Non-Max Suppression, NMS)保留最好的检测,去除重复。
算法:
- 按置信度降序排列所有检测
- 选择置信度最高的检测,加入输出列表
- 删除所有与它IoU > 阈值(如0.5)的检测
- 重复2-3直到没有剩余检测
python
def non_max_suppression(boxes, scores, iou_threshold=0.5):
"""
非极大值抑制
boxes: list of [x1, y1, x2, y2]
scores: list of confidence scores
"""
# 按分数降序排列
order = sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)
keep = []
while order:
# 选择分数最高的
i = order[
多类别NMS:对每个类别分别执行NMS,因为不同类别的物体可能重叠(如人骑在马上)。
YOLO:实时目标检测
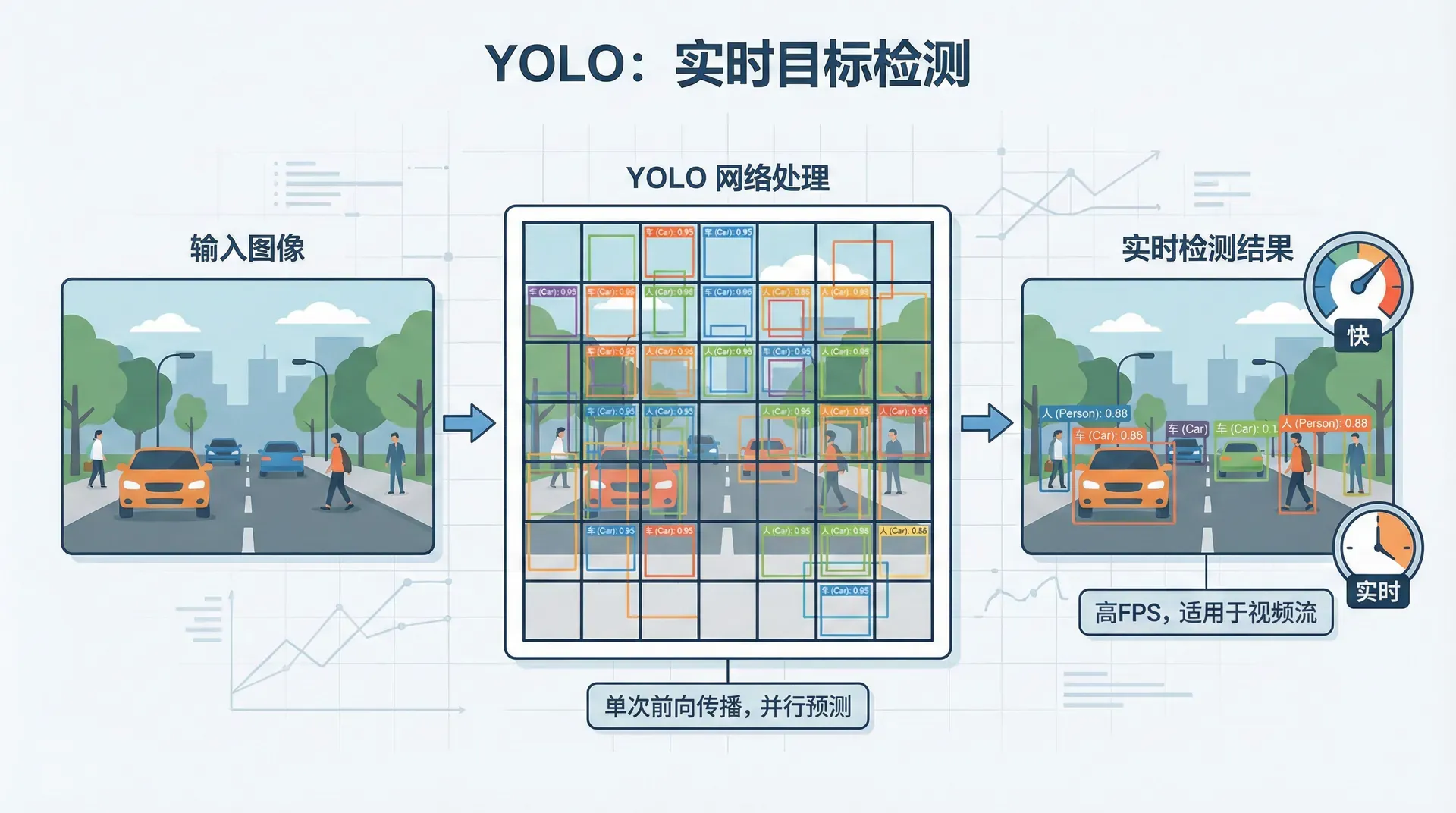
传统目标检测(如R-CNN)分两步:先提议候选区域,再分类。YOLO(You Only Look Once)将检测视为回归问题,一次前向传播完成检测,实现实时处理(45 FPS)。
核心思想:
- 将图像分成 网格(如7×7)
- 每个网格预测 个边界框及其置信度
- 每个网格还预测类别概率
输出张量形状:
其中5是 , 是类别数。
训练目标:
- 定位损失:预测框与真实框的坐标差异
- 置信度损失:预测置信度与实际IoU的差异
- 分类损失:类别预测的交叉熵
优势:
- 快速:单次前向传播,适合实时应用
- 全局推理:看整张图,比区域提议法少背景误检
- 通用性:适用于各种物体
劣势:
- 小物体检测不好(受限于网格大小)
- 同一网格内的多个物体难以检测
YOLOv2、v3、v4持续改进,v5、v7在速度和精度上继续提升,成为工业界最常用的检测算法之一。
Anchor Boxes:处理多物体重叠
如果两个物体的中心落在同一个网格怎么办?YOLO原版只能检测一个,Anchor Boxes解决了这个问题。
思路:预定义几种不同形状的Anchor(如高瘦的、宽扁的),每个Anchor预测一个物体。
假设每个网格有3个Anchor,输出变成 。训练时,每个真实物体分配给与它IoU最大的Anchor。
python
def assign_anchor(object_box, anchors):
"""
将物体分配给最匹配的anchor
object_box: [w, h] 归一化的宽高
anchors: list of [w, h] 预定义的anchor形状
"""
ious = []
for anchor in anchors:
# 计算IoU(假设中心对齐)
inter = min(object_box[0], anchor[0]) * min(object_box[1], anchor[1])
union = object_box[0]*object_box[
Anchor的选择:通常通过聚类训练集中的物体尺寸来确定。YOLO v2用k-means聚类找到5个Anchor,v3用9个。
实战:搭建简单的目标检测器
用预训练的YOLOv5进行检测:
python
import torch
# 加载预训练的YOLOv5
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
# 推理
img = 'path/to/image.jpg'
results = model(img)
# 显示结果
results.show() # 显示带框的图像
# 获取检测结果
detections = results.pandas().xyxy[0] # x1, y1, x2, y2, confidence, class, name
print(detections)自定义数据集训练:
yaml
# data.yaml
train: ./images/train
val: ./images/val
nc: 3 # 类别数
names: ['person', 'car', 'bicycle']python
# 训练
!python train.py --data data.yaml --weights yolov5s.pt --epochs 50标注工具推荐:LabelImg、CVAT、Roboflow。标注格式通常是YOLO格式(每张图一个txt,每行是 class x_center y_center width height)或COCO格式(JSON)。
目标检测的评估:mAP
目标检测的标准评估指标是平均精度均值(mean Average Precision, mAP)。
步骤:
- 对每个类别,按置信度降序排列检测
- 计算不同召回率下的精确率,画PR曲线
- 计算PR曲线下面积(AP)
- 对所有类别的AP取平均得到mAP
mAP@0.5:IoU阈值为0.5时的mAP
mAP@[0.5:0.95]:IoU从0.5到0.95每隔0.05计算一次,取平均(COCO数据集标准)
python
from sklearn.metrics import average_precision_score
def compute_map(all_predictions, all_ground_truths, iou_threshold=0.5):
"""
计算mAP
all_predictions: list of (class, confidence, box)
all_ground_truths: list of (class, box)
"""
aps = []
for class_id in unique_classes:
# 该类别的预测和真实框
preds = [p for p in all_predictions if p[0] ==
高mAP意味着模型既准确(高精确率)又全面(高召回率)。SOTA模型在COCO数据集上的mAP@0.5通常在60-70%。
目标检测的应用前景
目标检测是计算机视觉商业化最成功的领域之一:
- 自动驾驶:特斯拉、Waymo用多相机目标检测
- 安防:人脸识别、异常行为检测
- 零售:无人商店的商品识别
- 医疗:CT/MRI中的病变检测
- 农业:无人机识别作物病虫害
2026年,边缘设备(NVIDIA Jetson、手机NPU)上的实时检测已成为现实,为更多应用场景打开了可能。
我们已经完成了CNN模块的学习。在下面的几节中,我们将转向序列模型——处理时间序列和自然语言的核心技术。RNN、LSTM、注意力机制将带我们进入另一个精彩的领域:让机器理解和生成语言。