关系模型
在数据库的世界里,关系模型就像是建筑物的基础框架,它为我们提供了一种直观而强大的方式来理解和管理数据。 想象我们日常生活中的信息整理方式:将学生信息写在表格里,将商品信息记录在清单上。 关系模型正是将这种表格化的思维方式引入到计算机科学中,并使其变得极其高效和精确。
关系模型之所以成为当今商业数据处理应用的主要数据模型,是因为它的简洁性让程序员的工作变得更加轻松,相比于早期的网络模型或层次模型, 关系模型提供了一种更加自然的数据组织方式。
关系数据库的结构
表格
在关系数据库体系中,所有数据均以结构化表格(即“关系”)的形式进行组织,每个表格拥有唯一的名称以便于区分和引用。 我们可以借助高校信息管理系统的场景,来深入理解这一点。
以在线教育平台为例,假设我们需要设计一套数据库架构。首先,系统中应有一张“教师表”,用于系统性地存储每位教师的详细信息:
在这个表格中,每一行代表一位教师的完整信息,每一列代表一个特定的属性。这种结构让我们能够清晰地看到数据的组织方式。 同样地,我们还需要一个“课程表”来记录所有课程信息:
在关系模型的理论体系中,表格被严格称为“关系”(Relation),每一行数据称为“元组”(Tuple),每一列则被称为“属性”(Attribute)。 这些术语源自集合论与数学逻辑,强调了数据结构的严谨性和抽象性。
数据的原子性
在关系模型中,数据的“原子性”是指每个属性值必须是不可再分的最小数据单元。这一原则确保了数据结构的规范性和操作的高效性。 可以将其类比为化学中的原子,原子是物质的基本组成单位,无法再被分割。同理,关系数据库中的每个属性值也应当是最基本、不可拆分的信息。
例如,在设计教师信息表时,若存在“联系方式”这一列,我们不应将手机号、座机号和邮箱地址混合存储于同一字段。 正确的做法是将每种联系方式分别设计为独立的属性列,从而保证每个数据项的原子性。
这种原子性的要求确保了数据的一致性和查询的效率。
空值的处理
在实际的数据库管理过程中,我们常常会遇到某些数据项暂时无法获取或本身并不适用的情形。关系模型采用“空值”(null)来精确表达这种“未知”或“无定义”的状态。
以高校信息系统为例,假设一位教师刚刚入职,尚未分配具体的办公室,此时“办公室号”字段应赋予空值。需要注意的是,空值与数值零(0)或空字符串("")有本质区别:零代表具体的数值,空字符串表示已知但内容为空,而空值则专指数据缺失或不可用的情形,体现了数据的不可比性和不确定性。
空值的存在会为数据库操作带来一定的复杂性,在实际应用中应该尽量避免空值的产生,或者为其设置合理的默认值。
数据库模式
模式与实例的区别
在关系数据库理论中,我们通常会区分“数据库模式”(Schema)与“数据库实例”(Instance)这两个核心概念。
数据库模式可以理解为数据库的结构性蓝图,它详细规定了数据库中各个关系(表)的名称、每个关系包含的属性(列)、属性的数据类型、以及各种完整性约束等。这一结构定义了数据的组织方式和存储规则,具有高度的抽象性和稳定性。模式的设计直接影响到数据的规范性与后续操作的可行性。
而数据库实例则是指在某一特定时刻,数据库中实际存储的全部数据集合。实例随着数据的插入、删除和更新而动态变化,反映了数据库在运行过程中的具体状态。可以将模式比作一座大厦的设计图纸,而实例则是这座大厦在某一时刻的实际样貌——图纸不变,但大厦内部的人员和物品会不断更替。
关联关系的建立
在关系型数据库的实际建模与应用过程中,表与表之间的关联关系(Relation Association)是数据组织的核心。以“教师表”和“课程表”为例,二者均包含“学科”这一属性,这种设计并非偶然,而是为了实现数据的语义关联与完整性约束。
通过在不同关系中设置相同的属性(如“学科”),我们能够利用关系代数中的连接(Join)操作,将分散在各表的数据有机地整合。例如,若需查询“人工智能”学科下的所有教师及其开设课程,我们可以基于“学科”属性对“教师表”与“课程表”进行等值连接,从而高效地获取跨表的综合信息。这种关联机制不仅提升了数据的可扩展性,也为复杂业务需求的实现提供了理论基础和技术保障。
键
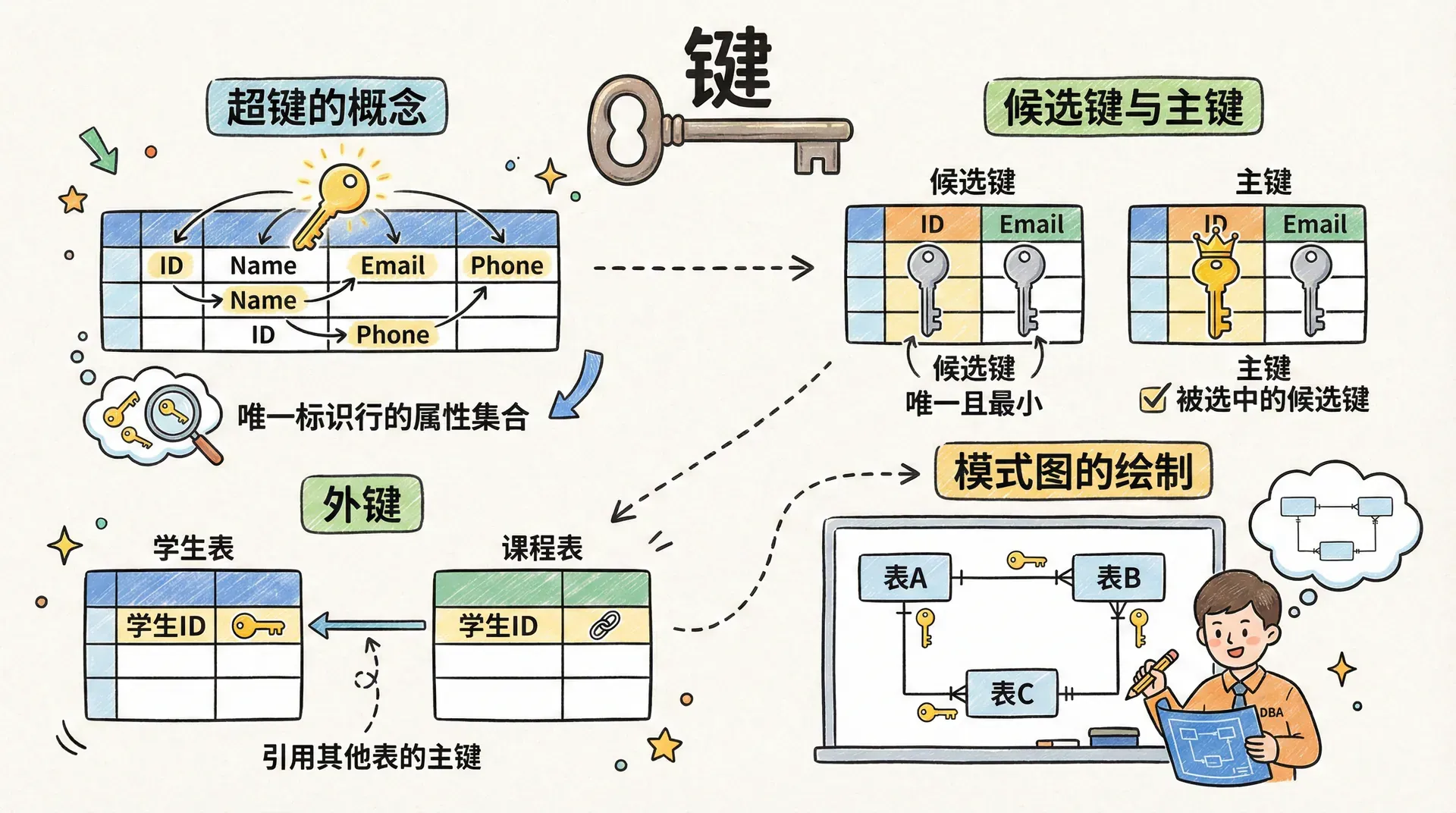
超键的概念
在关系数据库理论中,“键”是用于唯一标识关系中元组(行)的属性或属性组。它不仅是数据检索和完整性约束的基础,也是关系模型结构化管理的核心工具。
超键(Superkey)指的是在一个关系模式中,能够唯一标识任意元组的属性集合。只要属性组合具备唯一性,无论包含多少冗余字段,都可以称为超键。例如,在“教师”关系中,教师ID(如teacherId)本身就是一个超键,因为每位教师的ID都不重复。即使我们将教师ID与姓名、学科等其他属性组合,这样的属性组依然是超键,但通常包含了冗余信息。
需要注意的是,像“姓名”这样的属性,由于可能存在重名现象,无法保证唯一性,因此不能作为超键。超键的本质在于其唯一性和区分能力,是后续候选键、主键等概念的理论基础。
候选键与主键
候选键(Candidate Key)是指在关系模式中,能够唯一标识每一个元组的最小属性集。换句话说,候选键不仅具备唯一性,而且是不可再约简的——一旦去除其中任意一个属性,就无法保证对元组的唯一标识。候选键的存在为数据的完整性和检索效率提供了理论基础。
在实际数据库设计中,一个关系通常会存在多个候选键。例如,假设我们在教师信息管理系统中,既为每位教师分配了唯一的“教师ID”,又规定“姓名与学科”的组合在全校范围内也具有唯一性。那么,“教师ID”以及“姓名+学科”这两组属性都可以作为候选键。每组候选键都能独立地实现对元组的唯一标识。
主键(Primary Key)则是在所有候选键中,经过综合考量后选定的一个,作为关系的主标识符。主键的选择不仅要满足唯一性和最小性,还应优先考虑属性值的稳定性、简洁性以及实际业务需求等因素。主键的合理选取对于后续的索引优化、外键关联和数据一致性维护具有重要意义。
在我们的例子中,“教师ID”比“姓名+学科”更适合作为主键,因为教师ID一旦分配就不会改变,而教师的姓名或学科可能会发生变化。
外键
外键(Foreign Key)是关系数据库中实现表与表之间参照完整性约束的关键机制。当某一关系(表)中的属性组取值必须依赖于另一关系的主键时,这组属性即被定义为外键。外键不仅用于表达实体间的逻辑关联,还能有效防止“孤立数据”的出现,确保数据的一致性与完整性。
让我们考虑一个新的表格——授课表,它记录哪个教师教授哪门课程:
在上述授课表结构中,“教师ID”字段作为外键,严格关联并参照教师表中的主键,确保每条授课记录都能准确对应到唯一的教师实体。同理,“课程编号”字段作为外键,直接指向课程表的主键,实现对课程信息的有效引用。
外键约束确保了数据的参照完整性。这意味着授课表中的每个教师ID都必须在教师表中存在,每个课程编号都必须在课程表中存在,从而避免了数据的不一致性。
模式图的绘制
为了更好地理解数据库的结构,我们可以用模式图来可视化表格之间的关系:
关系查询语言
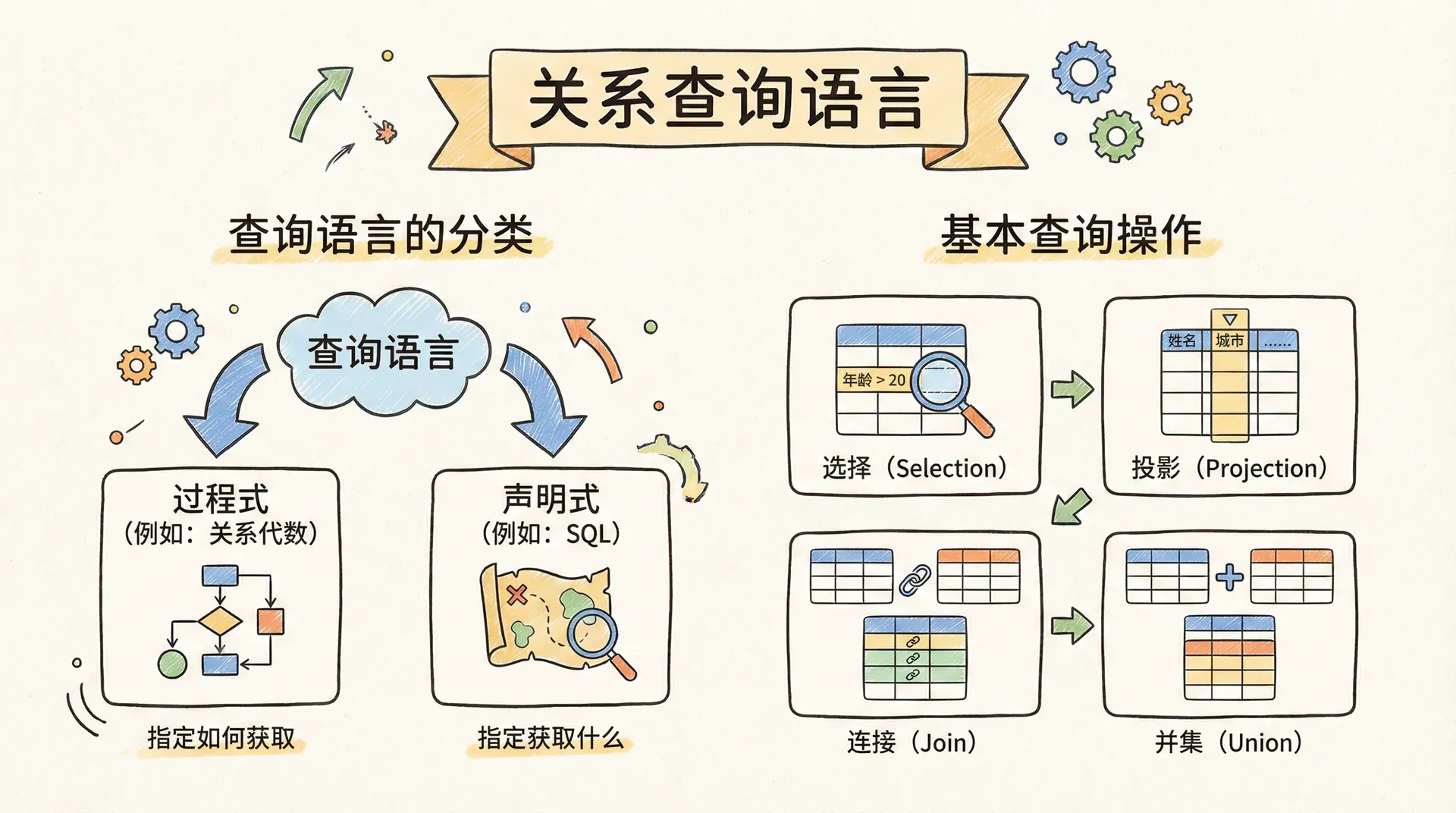
查询语言的分类
关系数据库的核心优势在于其强大的查询机制。通过关系查询语言,我们能够高效、准确地从庞大的数据集中检索出所需的信息。 在学术和工程领域,查询语言按照描述和执行方式的不同,主要分为两类:过程性(Procedural)和非过程性(Non-Procedural)。
过程性查询语言要求用户详细指定数据检索的每一步操作流程,类似于算法的逐步描述。 例如,用户需要明确指出先筛选哪些记录,再如何排序、分组,最后输出哪些字段。 这种方式为用户提供了高度的操作控制权,但也要求用户具备较强的逻辑思维能力和数据库操作经验。
非过程性查询语言则更侧重于描述“想要什么”,而不是“怎么做”。用户只需表达查询目标,具体的数据检索路径和优化由数据库系统自动完成。 以SQL为代表的结构化查询语言,就是典型的非过程性语言。它让用户专注于业务需求,极大地提升了开发效率和系统的可维护性。
现代关系数据库查询语言往往融合了两者的优点,既允许用户在需要时精细控制查询过程,又能在大多数场景下简洁地表达复杂的数据需求。 这种设计既保证了系统的灵活性,也兼顾了易用性和高效性。
基本查询操作
关系数据库支持多种基本操作:
选择操作在关系代数中对应于对关系(表)中满足特定条件的元组进行筛选。举例来说,假设我们需要检索所有工资高于7500元的教师,这一操作本质上就是在教师表中应用条件过滤,得到一个仅包含符合要求记录的新关系。
投影操作在关系代数中,指的是从一个关系(表)中选取所需的属性(字段),形成一个新的关系。 举例来说,假设我们只关心教师的姓名与工资,而不需要其他信息,此时就可以通过投影操作,仅保留这两个属性,简化数据结构,便于后续分析与处理。
连接操作(Join Operation)在关系数据库理论中占据着核心地位。 它允许我们基于某些共同属性,将两个或多个关系(表)中的数据有机地整合为一个更丰富、更具业务价值的新关系。 例如,若我们希望深入了解每位教师所对应学科的详细背景信息,就可以通过连接操作,将“教师表”与“学科表”按照“学科”字段进行关联, 从而获得教师与其所属学科的完整数据视图。
组合操作(Composition Operation)是关系代数中的重要特性,它允许我们将多个基本操作有机结合,构建出复杂且高效的数据查询流程。 例如,若需检索所有工资高于7500元的教师姓名,我们可以先对教师表进行选择操作筛选出符合条件的记录,再通过投影操作提取姓名字段,实现精准的数据提取。
这个过程展示了关系操作的一个重要特点:操作的结果仍然是关系,这意味着我们可以在查询结果上继续进行其他操作,形成复杂的查询链。
关系操作的这种可组合性是关系数据库强大的重要原因。我们可以像搭积木一样,将简单的操作组合成复杂的查询,满足各种数据分析需求。
数据的维护与更新
关系数据库不仅让我们能够灵活查询数据,还为日常的数据维护提供了保障。无论是新教师的加入、课程内容的调整,还是工资的变动,这些信息的插入、删除与修改都需要在保证数据一致性和完整性的前提下进行。比如说,如果我们要删除一位教师,系统还会自动检查是否有课程记录与之关联,防止出现“悬空”数据,确保每一条信息都能自洽地存在于数据库中。
正是因为有了关系模型的理论基础,数据库才能将纷繁复杂的现实世界信息,转化为结构化、可操作的数据。我们可以像搭积木一样,通过各种查询和维护操作,灵活地管理和分析数据。
小练习
1. 关于关系模型的数据组织方式,以下哪个说法是正确的?
2. 关于关系模型中数据的原子性要求,以下哪个说法是正确的?
3. 关于超键、候选键和主键的关系,以下哪个说法是正确的?
4. 关于外键的概念和作用,以下哪个说法是正确的?
5. 关于关系数据库的基本查询操作,以下哪个说法是正确的?
6. 设计关系数据库表结构
假设你需要为一个在线书店设计数据库,需要存储以下信息:
- 图书信息:图书编号、书名、作者、出版社、价格、ISBN
- 作者信息:作者编号、姓名、国籍、出生年份
- 订单信息:订单编号、客户姓名、下单日期、订单金额
- 订单明细:订单编号、图书编号、购买数量、单价
请设计这些表的结构,并说明:
- 每个表的主键是什么?为什么选择它作为主键?
- 哪些字段应该作为外键?它们参照哪些表?
- 哪些字段可能允许为空值?为什么?
答案:
表结构设计:
sql
-- 作者表
CREATE TABLE 作者表 (
作者编号 VARCHAR(10) PRIMARY KEY,
姓名 VARCHAR(50) NOT NULL,
国籍 VARCHAR(50),
出生年份 YEAR
);
-- 图书表
CREATE TABLE 图书表 (
图书编号 VARCHAR(20) PRIMARY KEY
7. 关系操作的综合应用
假设你有以下三个表:
学生表:
课程表:
选课表:
请使用关系操作的概念,描述如何实现以下查询(用文字描述操作步骤,不需要写SQL):
- 查询所有计算机科学专业的学生姓名
- 查询学号为S001的学生选修的所有课程名称和成绩
- 查询所有选修了"数据库原理"课程的学生姓名和专业
答案:
查询1:查询所有计算机科学专业的学生姓名
操作步骤:
- 选择操作:在学生表上应用选择条件"专业 = '计算机科学'",筛选出所有计算机科学专业的学生记录。
- 投影操作:从筛选结果中投影出"姓名"属性,得到最终结果。
结果: 张三、王五
查询2:查询学号为S001的学生选修的所有课程名称和成绩
操作步骤:
- 选择操作:在选课表上应用选择条件"学号 = 'S001'",筛选出该学生的所有选课记录。
- 连接操作:将筛选后的选课表与课程表进行连接,连接条件是"选课表.课程编号 = 课程表.课程编号",得到包含课程名称和成绩的组合结果。
- 投影操作:从连接结果中投影出"课程名称"和"成绩"两个属性。
结果:
查询3:查询所有选修了"数据库原理"课程的学生姓名和专业
操作步骤:
- 选择操作:在课程表上应用选择条件"课程名称 = '数据库原理'",找到该课程的记录(课程编号为C001)。
- 连接操作:将课程表(已筛选)与选课表进行连接,连接条件是"课程表.课程编号 = 选课表.课程编号",得到所有选修该课程的学生学号。
- 连接操作:将上一步的结果与学生表进行连接,连接条件是"选课表.学号 = 学生表.学号",得到学生的完整信息。
- 投影操作:从最终结果中投影出"姓名"和"专业"两个属性。
结果:
关键概念:
- 选择操作用于筛选满足条件的行
- 投影操作用于选取需要的列
- 连接操作用于整合多个表的信息
- 这些操作可以组合使用,形成复杂的查询流程
8. 键的设计和完整性约束
假设你正在设计一个员工管理系统,包含以下表:
部门表:
员工表:
请分析并回答以下问题:
- 员工表中哪些属性或属性组合可以作为超键?哪些可以作为候选键?
- 应该选择哪个作为主键?为什么?
- 部门表中的"部门经理工号"字段应该如何处理?它应该参照哪个表?
- 如果某个部门暂时没有经理(部门经理工号为NULL),这会影响数据完整性吗?
答案:
1. 超键和候选键分析:
超键(能够唯一标识员工的属性组合):
- 工号(单独)
- 身份证号(单独)
- 工号 + 姓名
- 工号 + 身份证号
- 身份证号 + 姓名
- 工号 + 姓名 + 身份证号
- 等等(任何包含工号或身份证号的组合)
候选键(最小的超键,去除任意属性后无法保证唯一性):
- 工号:单独就能唯一标识每个员工,是最小的超键
- 身份证号:单独就能唯一标识每个员工,是最小的超键
2. 主键选择:
应该选择工号作为主键,原因如下:
- 稳定性:工号一旦分配通常不会改变,而身份证号虽然唯一但属于个人隐私信息
- 简洁性:工号通常比身份证号更短,便于使用和索引
- 业务相关性:工号是业务系统中的标识符,更符合业务逻辑
- 非空性:工号是系统分配的,保证非空;身份证号在某些情况下可能无法获取
3. 部门经理工号的处理:
"部门经理工号"字段应该:
- 作为外键,参照员工表的工号
- 这样可以确保部门经理必须是系统中的有效员工
- 建立外键约束:
FOREIGN KEY (部门经理工号) REFERENCES 员工表(工号)
4. 空值对数据完整性的影响:
如果某个部门暂时没有经理(部门经理工号为NULL),这不会影响数据完整性,原因如下:
- NULL值表示"未知"或"不适用",这是合理的业务状态
- 外键约束允许NULL值(只要非NULL的值必须存在于被参照表中)
- 这符合实际业务场景:新成立的部门可能暂时没有经理,或者经理离职后需要时间任命新经理
完整的设计示例:
sql
-- 员工表
CREATE TABLE 员工表 (
工号 VARCHAR(10) PRIMARY KEY,
姓名 VARCHAR(50) NOT NULL,