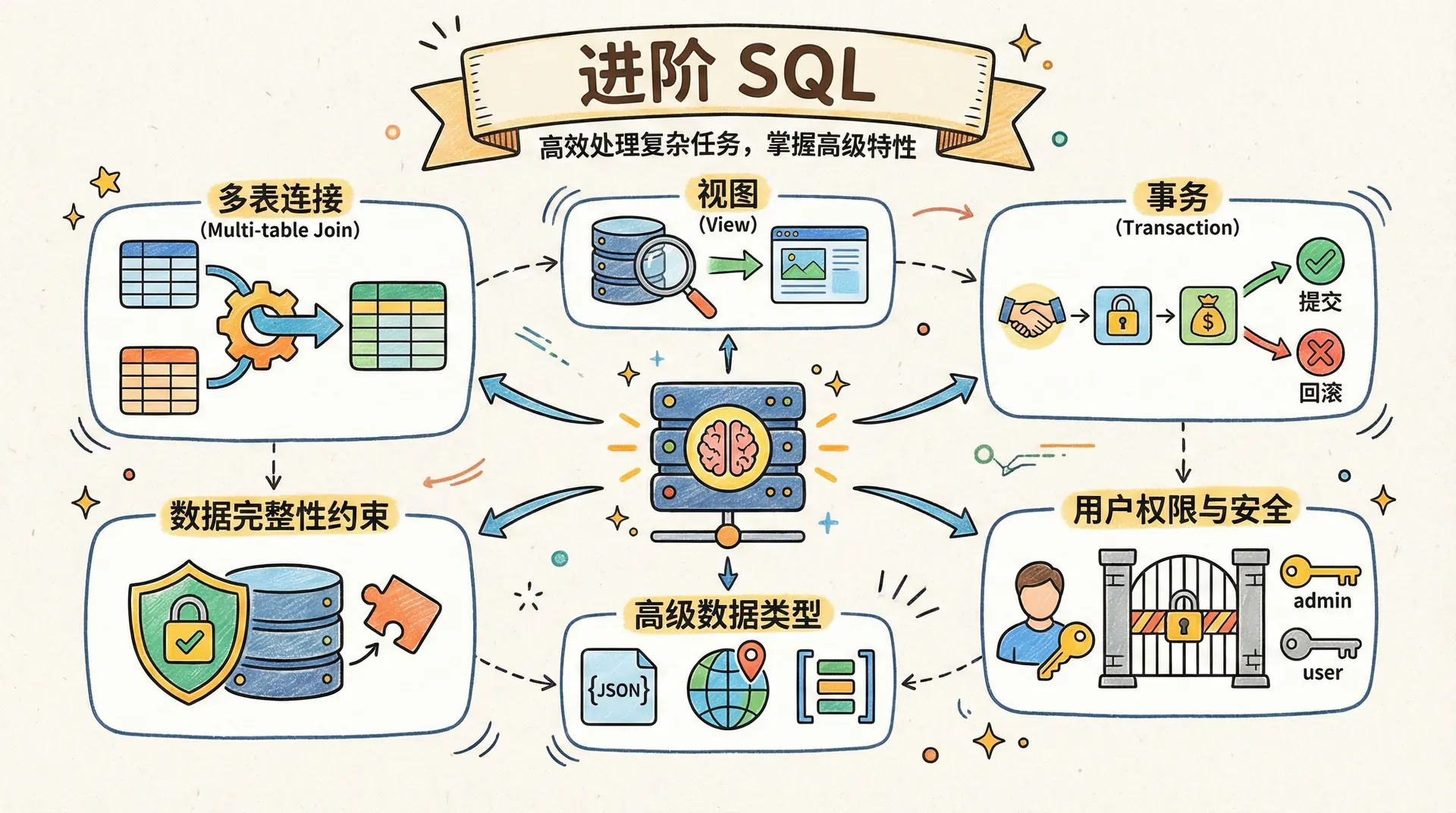
进阶 SQL
在数据库领域,进阶 SQL 能力使我们能够高效地处理复杂的数据分析、数据管理和安全控制任务。 我们将系统性地介绍 SQL 的高级特性,包括多表连接、视图(View)的设计与应用、事务(Transaction)管理、数据完整性约束、高级数据类型的使用,以及用户权限与安全机制。
表连接
在数据库管理中,表连接(Join)是实现多表数据关联与综合分析的核心技术。通常,实际业务数据会分布在多张结构化表中,例如图书信息表与借阅记录表。通过连接操作,可以基于表之间的主外键或其他逻辑关系,将分散的数据整合为统一的查询结果,从而支持复杂的数据分析和业务需求。
SQL 的连接操作不仅仅是将表按行拼接,而是依据设定的连接条件(如主键与外键的对应关系),生成具有业务语义的结果集。这一过程为数据的深度挖掘和多维分析提供了基础,是关系型数据库查询的关键能力之一。
连接条件的灵活运用
在实际的多表连接操作中,ON 子句允许我们精确地定义表之间的关联条件,从而实现复杂的数据关联。例如,在电商系统中,通常需要将顾客信息表与订单表通过顾客ID进行关联,以便查询每位顾客的订单详情:
sql
-- 查找所有顾客的订单信息
SELECT 顾客.姓名, 顾客.城市, 订单.订单日期, 订单.总金额
FROM 顾客表 JOIN 订单表 ON 顾客表.顾客ID = 订单表.顾客ID;这个查询就像是在两张纸质表格上画线连接相关的记录。ON 条件告诉数据库:“请把顾客ID相同的记录连接起来”。
ON 子句与 WHERE 子句在连接查询中的作用略有不同。ON 子句定义了表之间的连接条件,而 WHERE 子句则是在连接完成后对结果进行过滤。
外连接
在实际的数据分析中,除了关注存在关联的数据外,我们还常常需要保留未建立关联的记录。例如,在统计学生与社团参与情况时,既要展示已加入社团的学生,也要完整反映未参与任何社团的学生信息,以确保数据的全面性和业务分析的准确性。
左外连接保留左侧表的所有记录,即使右侧表没有匹配的数据:
sql
-- 显示所有学生信息,包括没有参加社团的学生
SELECT 学生.姓名, 学生.专业, 社团.社团名称
FROM 学生表 LEFT OUTER JOIN 社团参与表 ON 学生表.学号 = 社团参与表.学号;在实际的数据管理中,左外连接(LEFT OUTER JOIN)常用于需要完整保留主表(如学生表)所有记录的场景,无论其在关联表(如社团参与表)中是否有匹配项。例如,统计每位学生的课外活动参与情况时,左外连接能够确保所有学生信息都被包含在查询结果中。对于未参与任何社团的学生,其对应的社团相关字段将以 NULL 显示。
右外连接则相反,它保留右侧表的所有记录:
sql
-- 显示所有课程信息,包括没有学生选修的课程
SELECT 课程.课程名称, 课程.学分, 学生.姓名
FROM 选课表 RIGHT OUTER JOIN 课程表 ON 选课表.课程ID = 课程表.课程ID;全外连接会保留两个表中的所有记录:
sql
-- 显示所有教师和所有课程的对应关系
SELECT 教师.姓名, 课程.课程名称
FROM 教师表 FULL OUTER JOIN 授课表 ON 教师表.教师ID = 授课表.教师ID
FULL OUTER JOIN 课程表 ON 授课表.课程ID = 课程表.课程ID;这个查询会显示所有教师(包括目前没有授课的)和所有课程(包括目前没有分配教师的)。
连接类型
选择合适的连接类型在实际的数据管理中非常重要。例如,在商店管理系统中,查询所有员工及其负责的部门信息时,内部连接(INNER JOIN)用于确保只有与部门存在关系的员工被纳入结果,避免了孤立员工记录的显示; 而左连接(LEFT JOIN)则保留所有员工记录,同时确保所有关联的部门信息都能被显示出来,这对于展现员工在某个时间点的工作状态和变动情况非常有用。
视图
视图(View)是数据库中的一种虚拟表,其本质是基于一个或多个基础表的查询结果集。视图本身不存储实际数据,而是在每次访问时动态地执行定义视图的查询语句,返回相应的数据结果。 通过视图,可以为不同的用户或应用提供定制化的数据展示和访问权限,实现数据抽象和安全隔离。例如,在同一套底层数据基础上,可以为教务人员、教师、学生等不同角色分别定义只包含其所需字段的视图,从而满足多样化的业务需求,同时避免敏感信息的泄露。
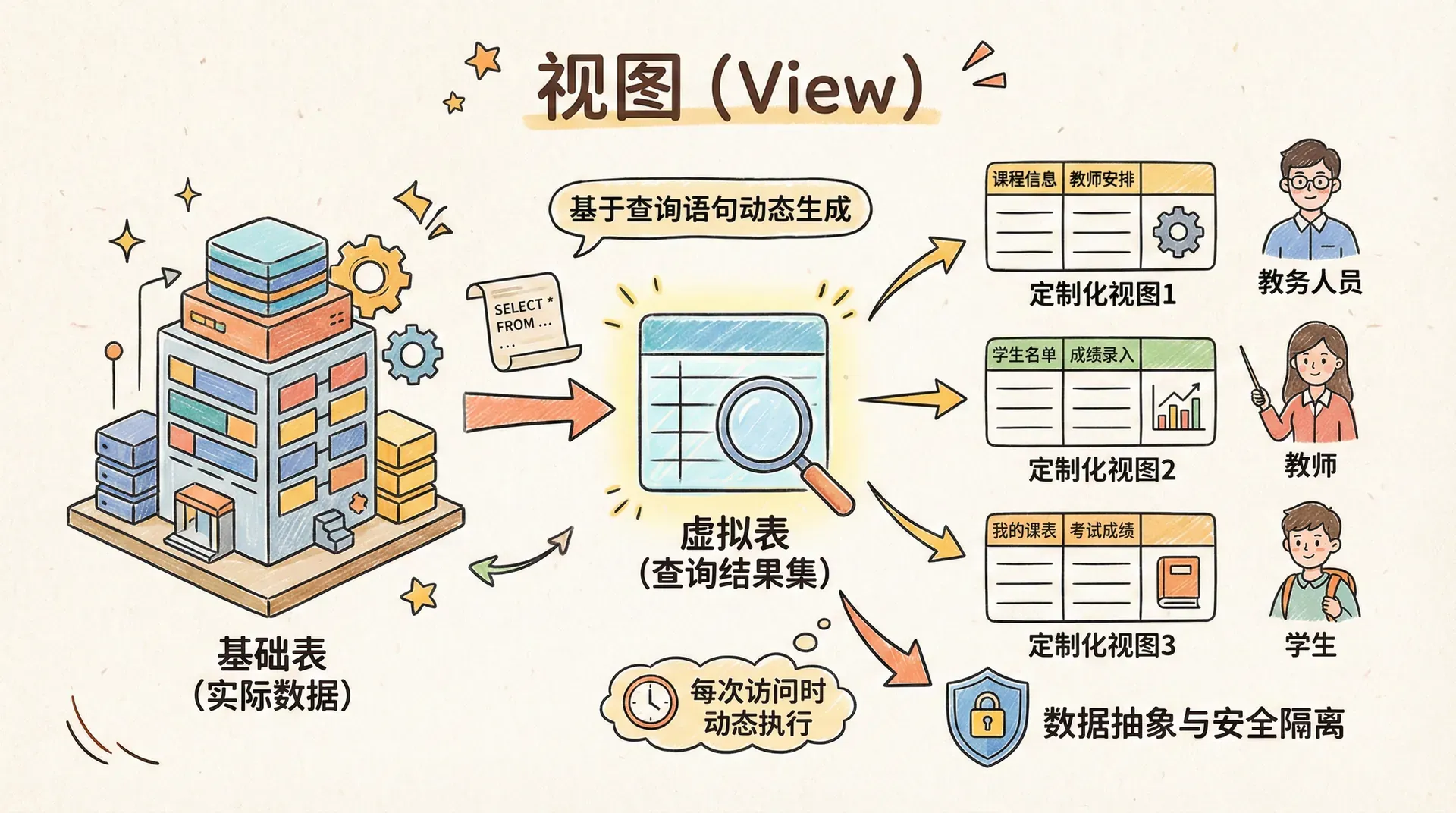
创建和使用视图
让我们通过一个实际的例子来理解视图的创建和使用。假设我们有一个学校管理系统,我们需要为不同的用户角色创建不同的数据视图:
sql
-- 为教务处创建学生基本信息视图(不包含敏感信息)
CREATE VIEW 学生基本信息 AS
SELECT 学号, 姓名, 专业, 入学年份
FROM 学生表;这个视图隐藏了学生的身份证号、家庭住址等敏感信息,只向教务处展示必要的学术信息。
sql
-- 为任课教师创建所教课程的学生名单视图
CREATE VIEW 我的课程学生(课程名称, 学生姓名, 学号, 成绩) AS
SELECT 课程.课程名称, 学生.姓名, 学生.学号, 选课.成绩
FROM 课程表 JOIN 选课表 ON 课程表.课程ID = 选课表.课程ID
JOIN 学生表 ON 选课表.学号 = 学生表.
视图的列名可以显式指定,这在聚合查询或复杂表达式中特别有用,因为这些情况下系统可能无法自动生成有意义的列名。
视图的查询使用
一旦创建了视图,我们就可以像使用普通表一样使用它:
sql
-- 使用视图查询计算机专业的学生
SELECT * FROM 学生基本信息
WHERE 专业 = '计算机科学与技术';当你执行该查询时,数据库查询优化器会将对视图的访问自动转换(或“展开”)为其定义的底层 SQL 查询,并在执行计划中与其他操作一同优化和执行。整个过程对用户完全透明,无需关心视图背后的实现细节,用户只需像操作普通表一样使用视图即可。
物化视图:性能的平衡艺术
在某些场景下,为了提升查询性能和响应速度,可以将视图的查询结果持久化存储,这种机制称为物化视图(Materialized View)。物化视图会将查询结果以物理表的形式保存下来,并在底层数据发生变更时通过刷新机制进行同步更新。 这样,针对复杂的聚合或多表关联查询,用户可以直接访问预先计算好的结果集,显著减少查询时的计算开销,提高系统整体性能。
sql
-- 创建学生成绩统计的物化视图(概念示例)
CREATE MATERIALIZED VIEW 学生成绩统计 AS
SELECT 学号, 姓名, 平均成绩, 总学分
FROM (
SELECT s.学号, s.姓名,
AVG(sc.成绩) as 平均成绩,
SUM(c.学分) as 总学分
FROM 学生表 s
JOIN 选课表 sc ON s.学号
物化视图的维护依赖于数据库的刷新机制。当底层数据发生变更时,数据库系统可通过自动或手动刷新策略对物化视图进行同步更新,从而保证查询结果的时效性和准确性。
视图的更新
虽然视图在使用上类似于表,但并非所有视图都支持直接的数据更新。只有满足一定条件的视图才具备可更新性。具体而言,可更新视图通常要求以下条件:视图必须仅基于单一基表构建,不能包含聚合函数(如SUM、AVG等)、GROUP BY、DISTINCT等分组或去重操作,且视图中的列应直接对应基表的物理列,而非计算表达式或常量。 只有在这些约束下,数据库系统才能将对视图的插入、更新、删除操作准确映射到底层基表,实现数据的一致性和完整性。
sql
-- 可以更新的简单视图
CREATE VIEW 在校学生 AS
SELECT 学号, 姓名, 专业, 年级
FROM 学生表
WHERE 状态 = '在校';
-- 向视图插入数据
INSERT INTO 在校学生 VALUES ('2023001', '张小明', '计算机科学', '大一');这个插入操作实际上是在底层的学生表中插入记录,并且状态字段会自动设置为'在校'以满足视图的条件。
事务
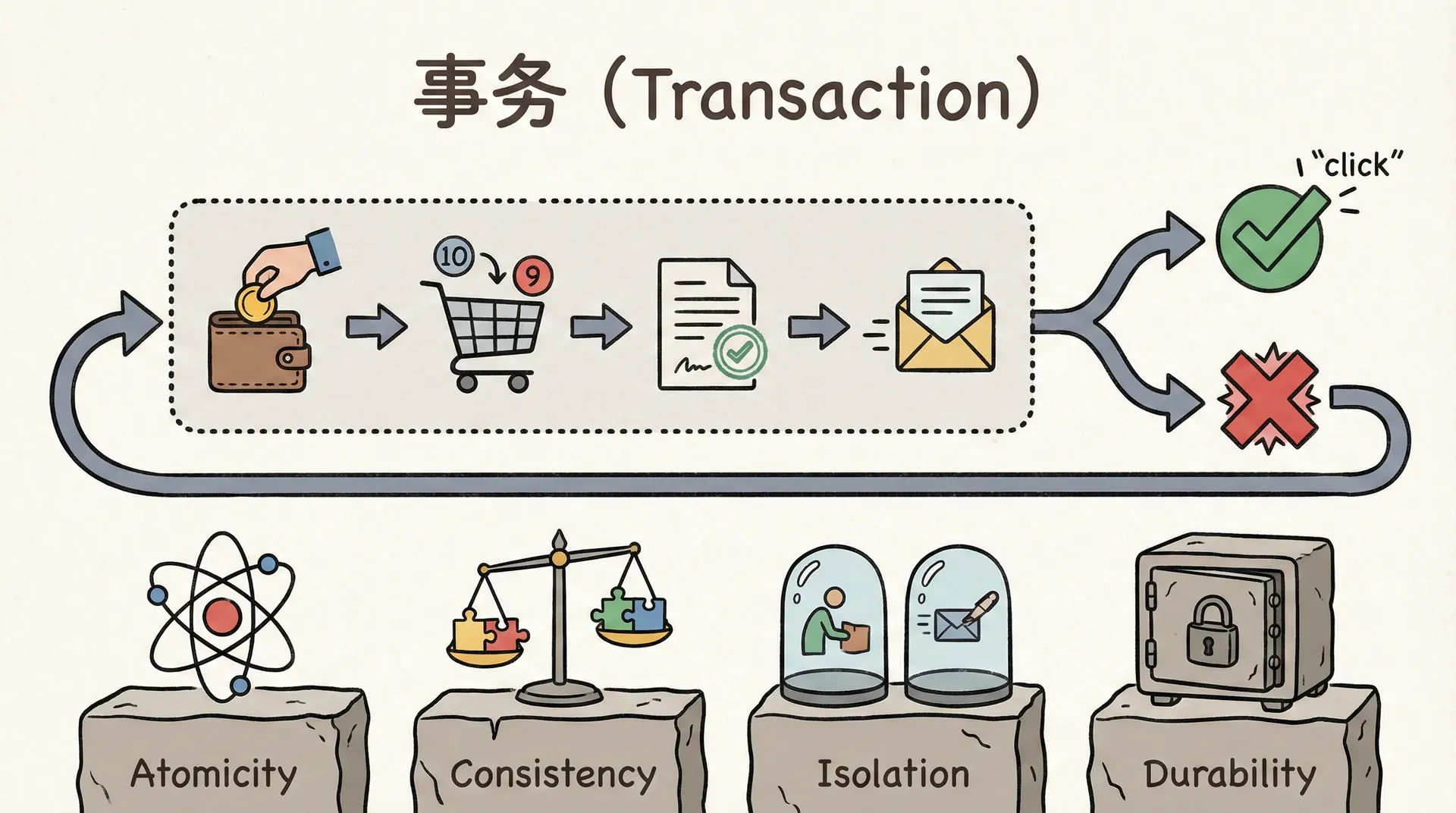
事务(Transaction)是数据库管理系统中用于保证数据一致性和完整性的基本单位。一个事务由一组相关的操作组成,这些操作要么全部成功提交,要么在出现异常时全部撤销回滚,任何中间状态都不会对外可见。 例如你在网上购物,需要完成几个步骤:从账户扣款、减少商品库存、生成订单记录、发送确认邮件。如果在某个步骤出现问题(比如网络断开),你肯定希望要么所有步骤都成功,要么什么都没有发生,而不是钱被扣了但商品没买到。 事务的核心特性通常用ACID(原子性Atomicity、一致性Consistency、隔离性Isolation、持久性Durability)来描述:
- 原子性:事务中的所有操作要么全部完成,要么全部不做,不会出现部分完成的情况。
- 一致性:事务执行前后,数据库都处于一致的状态,所有数据完整性约束都得到满足。
- 隔离性:并发执行的事务之间相互隔离,一个事务的中间结果对其他事务不可见。
- 持久性:一旦事务提交,其对数据库的修改将被永久保存,即使系统发生故障也不会丢失。
通过事务机制,数据库能够有效防止如转账、订单处理等多步操作中因部分失败导致的数据不一致问题,确保业务流程的可靠性和数据的正确性。
sql
-- 银行转账的事务示例
BEGIN; -- 开始事务
-- 从张三账户扣除1000元
UPDATE 账户表 SET 余额 = 余额 - 1000
WHERE 账户号 = '张三账户';
-- 向李四账户增加1000元
UPDATE 账户表 SET 余额 = 余额 + 1000
WHERE 账户号 = '李四账户';
-- 记录转账日志
INSERT INTO 转账记录 VALUES ('2024001'
事务的提交与回滚
事务提供了两个关键操作:COMMIT(提交)和 ROLLBACK(回滚)。提交就像按下保存按钮,告诉数据库“这些修改我都满意,请永久保存”。回滚则像是按下撤销键,告诉数据库“算了,这些修改我都不要了,请恢复到修改前的状态”。
sql
BEGIN;
-- 更新学生成绩
UPDATE 成绩表 SET 分数 = 85 WHERE 学号 = '2023001' AND 课程ID = 'CS101';
-- 假设发现输入错误,需要回滚
ROLLBACK; -- 撤销所有修改,成绩仍然是原来的值事务的自动管理
在实际应用中,许多数据库管理系统(DBMS)默认采用自动提交(autocommit)模式,即每条 SQL 语句在执行后会被当作一个独立的事务自动提交。这种机制简化了操作流程,但在需要保证多步操作原子性和一致性时,开发者通常需要关闭自动提交,手动管理事务的开始、提交与回滚,以实现更精细的事务控制。
sql
-- 关闭自动提交模式,开始手动控制事务
SET AUTOCOMMIT = 0;
-- 现在可以执行多个相关操作
INSERT INTO 订单表 VALUES (...);
UPDATE 库存表 SET 数量 = 数量 - 1 WHERE 商品ID = 'P001';
INSERT INTO 订单明细表 VALUES (...);
-- 手动提交
COMMIT;如果程序在事务执行过程中意外终止(比如断电或系统崩溃),数据库会自动回滚未提交的事务,确保数据不会处于不一致的状态。
现代数据库系统还支持更高级的事务控制,比如保存点(Savepoint),允许你在长事务中设置检查点:
sql
BEGIN;
INSERT INTO 学生表 VALUES ('2024001', '王小华', '计算机科学');
SAVEPOINT 添加学生完成;
INSERT INTO 选课表 VALUES ('2024001', 'CS101');
-- 发现课程代码输入错误
ROLLBACK TO 添加学生完成; -- 只回滚到保存点,学生信息保留
INSERT INTO 选课表 VALUES ('2024001', 'CS102'); -- 重新选课
COMMIT;这样的机制让我们可以像使用文档的多级撤销功能一样,灵活地控制和恢复事务中的各个阶段,极大提升了数据操作的安全性与便利性。
数据完整性约束
数据完整性约束(Data Integrity Constraints)是数据库系统中用于保证数据准确性、一致性和可靠性的规则集合。它们在表结构设计阶段被定义,强制数据库中存储的数据必须满足特定的业务和逻辑要求。 例如,在学籍管理系统中,数据完整性约束可以防止出现姓名为空、年龄为负数或专业代码不存在等不合理的数据,从而确保数据的有效性和规范性。
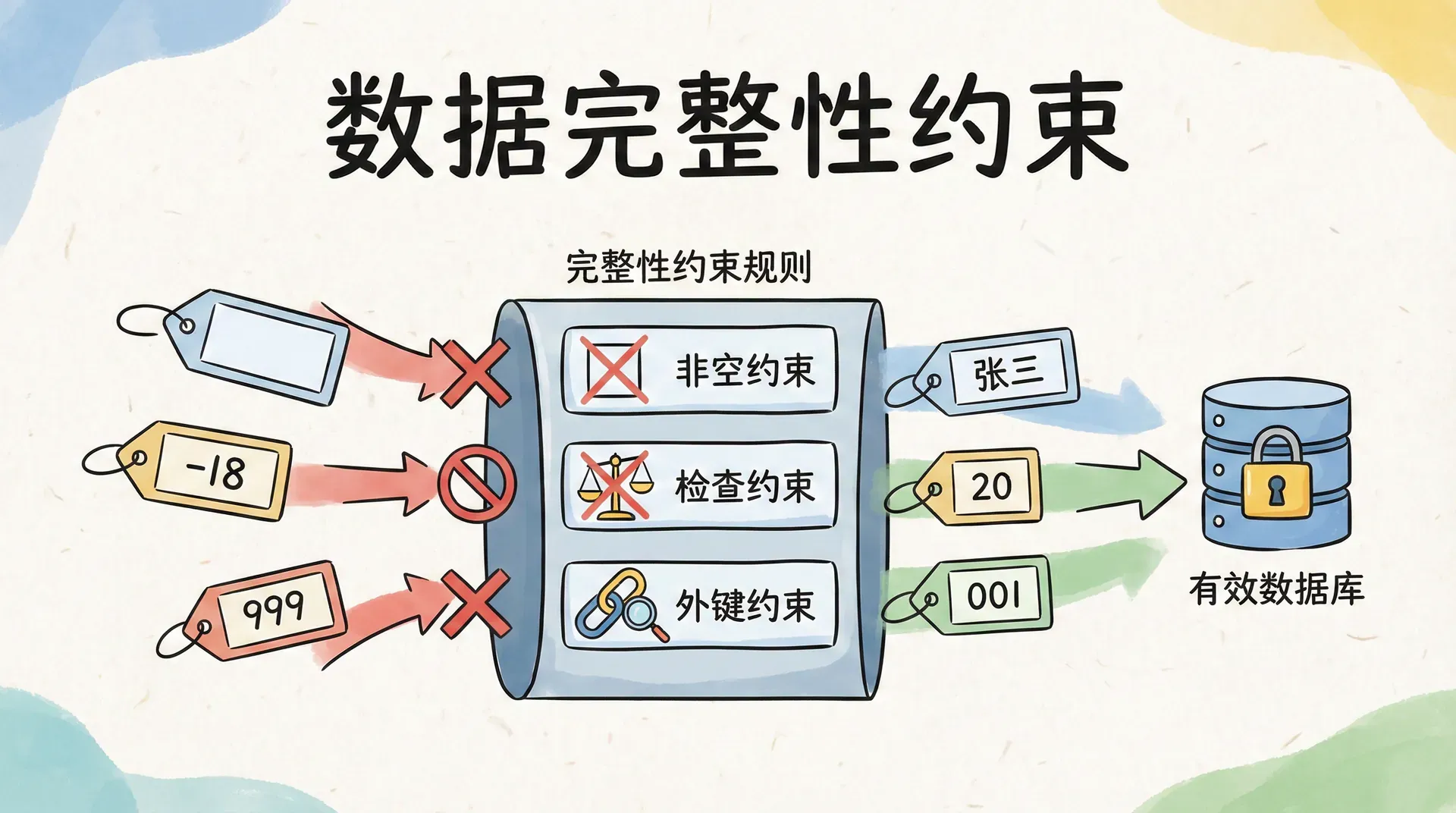
非空约束
非空约束(NOT NULL Constraint)用于保证表中指定字段在插入或更新时不能为空值。它强制要求每一行数据在这些关键列上都必须有有效输入,防止出现缺失或不完整的信息。
sql
-- 创建学生表,确保姓名和学号不能为空
CREATE TABLE 学生表 (
学号 VARCHAR(10) NOT NULL,
姓名 VARCHAR(50) NOT NULL,
专业 VARCHAR(30),
入学日期 DATE NOT NULL,
PRIMARY KEY (学号)
);当你试图插入姓名为空的记录时:
sql
-- 这个操作会失败,因为违反了非空约束
INSERT INTO 学生表 (学号, 专业) VALUES ('2024001', '计算机科学');
-- 错误:列 '姓名' 不能为 NULL唯一性约束
唯一性约束的作用是保证表中某些字段的取值不会重复。例如,像身份证号、邮箱或手机号这样的信息,每个人都只能拥有一个,数据库通过唯一性约束来防止出现重复的数据。
sql
-- 确保邮箱地址唯一
CREATE TABLE 用户表 (
用户ID INT PRIMARY KEY,
用户名 VARCHAR(30) NOT NULL,
邮箱 VARCHAR(100) UNIQUE,
手机号 VARCHAR(15) UNIQUE
);检查约束
检查约束(CHECK Constraint)用于在表级或列级定义字段必须满足的特定条件,从而实现对数据有效性的更精细控制。通过检查约束,数据库能够自动强制执行复杂的业务规则,防止不符合规范的数据被写入表中。
sql
-- 创建课程表,确保学分为正数且不超过8
CREATE TABLE 课程表 (
课程ID VARCHAR(10) PRIMARY KEY,
课程名称 VARCHAR(100) NOT NULL,
学分 INT CHECK (学分 > 0 AND 学分 <= 8),
开课学期 VARCHAR(10) CHECK (开课学期 IN ('春季', '夏季'
sql
-- 这个插入会失败,因为学分不能为负数
INSERT INTO 课程表 VALUES ('CS999', '测试课程', -1, '春季', 30);
-- 错误:违反检查约束 'courses_credits_check'引用完整性
引用完整性约束(Referential Integrity Constraint)用于保证表与表之间的外键关系始终有效,防止出现引用不存在主键的数据,从而维护数据库数据的一致性和完整性。
sql
-- 创建选课表,确保学号和课程ID都是有效的
CREATE TABLE 选课表 (
选课ID INT PRIMARY KEY,
学号 VARCHAR(10) NOT NULL,
课程ID VARCHAR(10) NOT NULL,
选课日期 DATE NOT NULL,
成绩 DECIMAL(4,1) CHECK (成绩 >= 0 AND 成绩 <= 100
级联操作
在实际数据库设计中,常常需要确保当父表(如部门表)中的数据发生变更时,相关的子表(如员工表)能够自动同步更新或删除对应的数据。这种机制称为级联操作(Cascade),能够有效维护数据之间的参照完整性,避免出现孤立或不一致的记录。
sql
-- 创建员工表,当部门被删除时自动删除该部门的所有员工
CREATE TABLE 员工表 (
员工ID VARCHAR(10) PRIMARY KEY,
姓名 VARCHAR(50) NOT NULL,
部门ID VARCHAR(10),
FOREIGN KEY (部门ID) REFERENCES 部门表(部门ID)
ON DELETE CASCADE -- 级联删除
ON UPDATE CASCADE -- 级联更新
);级联操作很强大,但也很危险。删除一个部门可能会意外删除很多员工记录。在使用级联删除时要特别小心,建议先备份数据。
SQL 的数据类型
时间与日期
在数据库管理系统中,时间和日期类型用于精确存储和管理与时间相关的数据,如用户注册时间、课程开始时间、作业截止日期等关键业务信息。
SQL 标准主要提供三种时间日期数据类型,每种类型适用于不同的业务场景:
sql
-- 创建学习记录表,展示不同时间类型的使用
CREATE TABLE 学习记录表 (
记录ID INT PRIMARY KEY,
学员姓名 VARCHAR(50),
注册日期 DATE, -- 只记录日期:2024-03-15
上课时间 TIME, -- 只记录时间:14:30:00
完成时间戳 TIMESTAMP, -- 完整的日期时间:2024-03-15 14:30:25
学习时长 INTERVAL -- 时间间隔:2小时30分钟
);让我们看看如何在实际场景中使用这些类型:
sql
-- 插入学习记录
INSERT INTO 学习记录表 VALUES (
1,
'小明',
DATE '2024-03-15', -- 注册日期
TIME '14:30:00', -- 下午2点30分上课
TIMESTAMP '2024-03-15 16:45:30', -- 完成时间
INTERVAL '2 hours 15 minutes' -- 学习了2小时15分钟
);TIMESTAMP 类型通常包含时区信息,这在处理全球用户时特别有用。比如北京时间下午2点和纽约时间下午2点是不同的绝对时刻。
时间计算
时间和日期类型的强大之处在于支持多种运算,可以进行加减等时间计算,满足复杂的业务需求:
sql
-- 计算学习任务的截止时间(开始时间 + 期限)
SELECT
任务名称,
开始时间,
开始时间 + INTERVAL '7 days' AS 截止时间,
截止时间 - CURRENT_TIMESTAMP AS 剩余时间
FROM 学习任务表;sql
-- 查找本周注册的新学员
SELECT 姓名, 注册日期
FROM 学员表
WHERE 注册日期 >= CURRENT_DATE - INTERVAL '7 days';默认值
在数据库设计中,默认值用于在未显式提供数据时自动填充字段,确保数据的完整性和一致性。这在用户注册、数据录入等业务场景中尤为重要:
sql
-- 创建用户表,设置贴心的默认值
CREATE TABLE 用户表 (
用户ID INT PRIMARY KEY,
用户名 VARCHAR(30) NOT NULL,
注册时间 TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 自动记录注册时间
积分 INT DEFAULT 0, -- 新用户积分从0开始
状态 VARCHAR(10) DEFAULT '正常', -- 默认状态为正常
最后登录 TIMESTAMP DEFAULT NULL
现在,即使你只提供用户名,系统也会自动填充其他字段:
sql
-- 只提供用户名,其他字段使用默认值
INSERT INTO 用户表 (用户名) VALUES ('新用户小王');
-- 结果会是:
-- 用户ID: (自动生成), 用户名: '新用户小王', 注册时间: (当前时间),
-- 积分: 0, 状态: '正常', 最后登录: NULL大对象类型
现代应用常常要存储图片、视频、长文本等大体积数据。为此,SQL 提供了专门的大对象类型来应对这些需求:
sql
-- 创建多媒体资源表
CREATE TABLE 课程资源表 (
资源ID INT PRIMARY KEY,
课程名称 VARCHAR(100),
课程介绍 CLOB(10KB), -- 存储长篇课程描述
课程封面 BLOB(5MB), -- 存储封面图片
教学视频 BLOB(2GB) -- 存储教学视频
);在实际应用中,我们通常不会直接在 SQL 中操作这些大对象,而是通过应用程序接口:
sql
-- 获取课程资源的定位符,然后通过程序接口分块下载
SELECT 资源ID, 课程名称, LENGTH(教学视频) as 视频大小
FROM 课程资源表
WHERE 课程名称 = '数据库基础教程';自定义类型
在实际业务场景中,内置数据类型有时难以覆盖所有复杂或特定的需求。此时,可以通过自定义类型来精确描述业务数据结构,实现更高的数据一致性与类型安全:
sql
-- 创建货币类型,避免不同货币间的混淆
CREATE TYPE 人民币 AS DECIMAL(12,2);
CREATE TYPE 美元 AS DECIMAL(12,2);
-- 创建产品表
CREATE TABLE 产品表 (
产品ID VARCHAR(10) PRIMARY KEY,
产品名称 VARCHAR(100),
国内价格 人民币,
海外价格 美元
这种设计的好处是类型安全。如果你不小心尝试将人民币价格赋值给美元字段,系统会报错:
sql
-- 这会产生类型错误
UPDATE 产品表 SET 海外价格 = 国内价格 WHERE 产品ID = 'P001';
-- 需要显式转换
UPDATE 产品表 SET 海外价格 = CAST(国内价格 AS 美元) / 7.2 WHERE 产品ID = 'P001';域约束
域(Domain)是具有限定约束的自定义数据类型,用于对字段取值范围进行严格规范,确保数据的有效性与一致性。
sql
-- 创建年级域,只允许特定的年级值
CREATE DOMAIN 年级类型 AS VARCHAR(10)
CONSTRAINT 有效年级 CHECK (VALUE IN ('大一', '大二', '大三', '大四', '研一', '研二', '研三'));
-- 创建成绩域,确保成绩在合理范围内
CREATE DOMAIN 成绩类型 AS DECIMAL(4,1)
CONSTRAINT
数据库安全与授权管理
数据库权限管理是保障数据安全与合规性的核心机制。通过合理分配和控制不同用户的访问权限,可以有效防止数据泄露、篡改和越权操作。在实际应用中,数据库系统通常根据用户的职责和业务需求,授予其相应的操作权限,确保每个用户只能访问和操作其被授权的数据范围。
权限管理不仅是数据库系统的基础功能,更是企业信息安全体系的重要组成部分。若权限分配不当,可能导致敏感数据被未授权用户访问或修改,进而引发严重的安全风险和合规问题。
基本权限类型
SQL 定义了几种基本的权限类型,每种权限都对应着不同的操作能力:
sql
-- 给学生用户授予查看自己成绩的权限
GRANT SELECT ON 成绩表 TO 学生用户;
-- 给教师用户授予录入成绩的权限
GRANT INSERT, UPDATE ON 成绩表 TO 教师用户;
-- 给教务处用户授予完全访问权限
GRANT ALL PRIVILEGES ON 学生表 TO 教务处用户;权限的粒度可以非常精细。比如,我们可以只授予对特定列的更新权限:
sql
-- 只允许HR部门更新员工的薪资信息
GRANT UPDATE (薪资, 奖金) ON 员工表 TO HR部门;
-- 允许部门经理查看本部门员工信息
GRANT SELECT ON 员工视图 TO 部门经理
WHERE 部门 = CURRENT_USER_DEPARTMENT();角色
在大型组织中,针对每个用户单独分配数据库权限不仅效率低下,还容易导致权限管理混乱和安全隐患。例如,高校中存在大量学生和教职工,若每次用户变动都需手动调整权限,既增加了管理成本,也难以保证权限分配的准确性和一致性。
为了解决这一问题,数据库管理系统引入了“角色(Role)”机制。角色本质上是一组权限的集合,管理员可以根据岗位或职责预先定义好各类角色及其对应的权限,然后将角色分配给具体用户。这样,权限管理更加集中、规范,便于批量授权和后续维护。
sql
-- 创建不同的角色
CREATE ROLE 学生角色;
CREATE ROLE 教师角色;
CREATE ROLE 管理员角色;
-- 为学生角色分配权限
GRANT SELECT ON 课程表 TO 学生角色;
GRANT SELECT ON 自己的成绩视图 TO 学生角色;
GRANT INSERT, UPDATE ON 选课表 TO 学生角色;
-- 为教师角色分配权限
GRANT SELECT ON 学生表 TO 教师角色;
现在,当新学生注册时,只需要一个简单的命令:
sql
-- 将学生角色分配给新用户
GRANT 学生角色 TO 新学生用户;角色的层次结构
角色机制支持层次化设计,高级角色能够继承下级角色所拥有的全部权限,实现类似企业组织架构中的权限递进与集中管理:
sql
-- 创建角色层次
CREATE ROLE 普通教师;
CREATE ROLE 系主任;
CREATE ROLE 院长;
-- 普通教师的基本权限
GRANT SELECT ON 学生表 TO 普通教师;
GRANT UPDATE ON 成绩表 TO 普通教师;
-- 系主任继承普通教师的权限,并有额外权限
GRANT 普通教师 TO 系主任;
GRANT INSERT, DELETE ON 课程表 TO 系主任;
-- 院长继承系主任的所有权限
视图级别的安全控制
在实际数据库安全管理中,往往需要实现更为细致的访问控制。此时,视图(View)成为关键工具。通过为不同用户或角色设计专属视图,可以有效隔离敏感信息,实现基于最小权限原则的数据可见性。例如,视图可根据用户身份动态过滤数据,使每类用户仅能访问其授权范围内的数据内容。
sql
-- 创建学生只能看到自己信息的视图
CREATE VIEW 我的信息 AS
SELECT 学号, 姓名, 专业, 入学年份
FROM 学生表
WHERE 学号 = CURRENT_USER_ID();
-- 创建教师只能看到自己课程学生的视图
CREATE VIEW 我的学生 AS
SELECT s.学号, s.姓名, c.课程名称, sc.成绩
FROM 学生表 s
JOIN 选课表 sc ON s
权限的传递与回收
权限管理过程中需要特别注意权限的授予与回收。权限并非一旦分配就永久有效,实际管理中应根据人员变动和岗位需求及时调整,避免权限滥用或遗留隐患:
sql
-- 授权时允许用户将权限传递给其他用户
GRANT SELECT ON 学生表 TO 张老师 WITH GRANT OPTION;
-- 张老师可以将这个权限传递给助教
GRANT SELECT ON 学生表 TO 李助教; -- 由张老师执行
-- 回收权限
REVOKE SELECT ON 学生表 FROM 张老师;
-- 这会级联回收李助教的权限,因为他的权限来源于张老师权限的级联回收可能会产生意想不到的后果。在回收重要权限之前,一定要仔细检查可能受影响的用户。
实战演练
习题一:学生选课数据分析
现有以下三个表:
学生表(students):
- 学号(student_id):VARCHAR(10),主键
- 姓名(name):VARCHAR(50),非空
- 专业(major):VARCHAR(30)
- 年级(grade):VARCHAR(10)
课程表(courses):
- 课程ID(course_id):VARCHAR(10),主键
- 课程名称(course_name):VARCHAR(100),非空
- 学分(credits):INT,检查约束(
学分>0 AND 学分<=8) - 教师ID(teacher_id):VARCHAR(10)
选课表(enrollments):
- 选课ID(enrollment_id):INT,主键,自增
- 学号(student_id):VARCHAR(10),外键引用学生表
- 课程ID(course_id):VARCHAR(10),外键引用课程表
- 成绩(score):DECIMAL(4,1),检查约束(
成绩>=0 AND 成绩<=100) - 选课时间(enrollment_date):DATE
请写出查询语句:查找所有计算机科学专业学生的姓名、选修课程名称和成绩,按成绩降序排列。
sql
SELECT s.name, c.course_name, e.score
FROM students s
JOIN enrollments e ON s.student_id = e.student_id
JOIN courses c ON e.course_id = c.course_id
WHERE s.major = '计算机科学'
ORDER BY e习题二:视图创建与使用
使用上面的学生表、课程表和选课表,创建一个视图显示每位学生的平均成绩和总学分。
sql
CREATE VIEW student_performance AS
SELECT s.student_id, s.name, s.major,
AVG(e.score) as average_score,
SUM(c.credits) as total_credits
FROM students s
LEFT JOIN enrollments e ON s.student_id =
习题三:银行转账事务
现有银行账户表:
账户表(accounts):
- 账户号(account_id):VARCHAR(20),主键
- 账户名(account_name):VARCHAR(50),非空
- 余额(balance):DECIMAL(12,2),检查约束(余额>=0)
请写出完整的转账事务:从账户"A001"转出1000元到账户"B002"。
sql
BEGIN;
-- 检查转出账户余额是否足够
SELECT balance FROM accounts WHERE account_id = 'A001' FOR UPDATE;
-- 假设余额足够,继续执行
-- 扣除转出账户金额
UPDATE accounts SET balance = balance - 1000.00
WHERE account_id = 'A001';
-- 增加转入账户金额
UPDATE accounts SET balance = balance
习题四:数据完整性约束设计
设计一个订单管理系统,要求:
- 订单表(orders)包含:订单ID(order_id)、客户ID(customer_id)、订单日期(order_date)、总金额(total_amount)
- 订单明细表(order_items)包含:明细ID(item_id)、订单ID(order_id)、产品ID(product_id)、数量(quantity)、单价(unit_price)
请写出创建这两个表的SQL语句,包含适当的约束。
sql
-- 创建订单表
CREATE TABLE orders (
order_id VARCHAR(20) PRIMARY KEY,
customer_id VARCHAR(10) NOT NULL,
order_date DATE NOT NULL DEFAULT CURRENT_DATE,
total_amount DECIMAL(10,2) NOT NULL CHECK (total_amount >= 0)
);
-- 创建订单明细表
习题五:时间日期数据类型应用
现有员工考勤表:
考勤表(attendance):
- 记录ID(record_id):INT,主键,自增
- 员工ID(employee_id):VARCHAR(10),非空
- 考勤日期(attendance_date):DATE,非空
- 签到时间(check_in_time):TIME
- 签退时间(check_out_time):TIME
- 工作时长(work_hours):DECIMAL(4,2)
请写出查询语句:查找昨天所有员工的工作时长超过8小时的记录。
sql
SELECT employee_id, attendance_date, work_hours
FROM attendance
WHERE attendance_date = CURRENT_DATE - INTERVAL '1 day'
AND work_hours > 8.00;习题六:数据库权限管理
现有用户表(users)和文章表(posts):
用户表(users):
- 用户ID(user_id):VARCHAR(10),主键
- 用户名(username):VARCHAR(30),唯一,非空
- 角色(role):VARCHAR(20),默认'user'
文章表(posts):
- 文章ID(post_id):INT,主键,自增
- 标题(title):VARCHAR(200),非空
- 内容(content):TEXT
- 作者ID(author_id):VARCHAR(10),外键引用用户表
- 发布时间(publish_time):TIMESTAMP,默认当前时间戳
请写出创建角色和分配权限的SQL语句:
- 创建"作者(author)"角色,可以在文章表上进行SELECT、INSERT、UPDATE操作
- 创建"审核员(reviewer)"角色,可以查看所有文章
- 创建"管理员(admin)"角色,具有所有权限
sql
-- 创建角色
CREATE ROLE author_role;
CREATE ROLE reviewer_role;
CREATE ROLE admin_role;
-- 为作者角色分配权限
GRANT SELECT, INSERT, UPDATE ON posts TO author_role;
GRANT SELECT ON users TO author_role;
-- 为审核员角色分配权限
GRANT SELECT ON posts TO reviewer_role;
GRANT SELECT ON users