关联容器
在日常编程中,我们经常需要根据某个特定的标识来快速查找和检索数据。比如,根据学号查找学生信息、根据商品编号获取价格、或者判断某个用户名是否已经存在。这种基于键进行高效查找的需求,正是关联容器设计的初衷。
关联容器支持基于键的高效查找和检索操作。与顺序容器不同,关联容器中元素的位置不是由它们在容器中的物理位置决定,而是由元素的键值决定。这种设计使得我们能够快速定位和访问特定的元素,而不需要遍历整个容器。
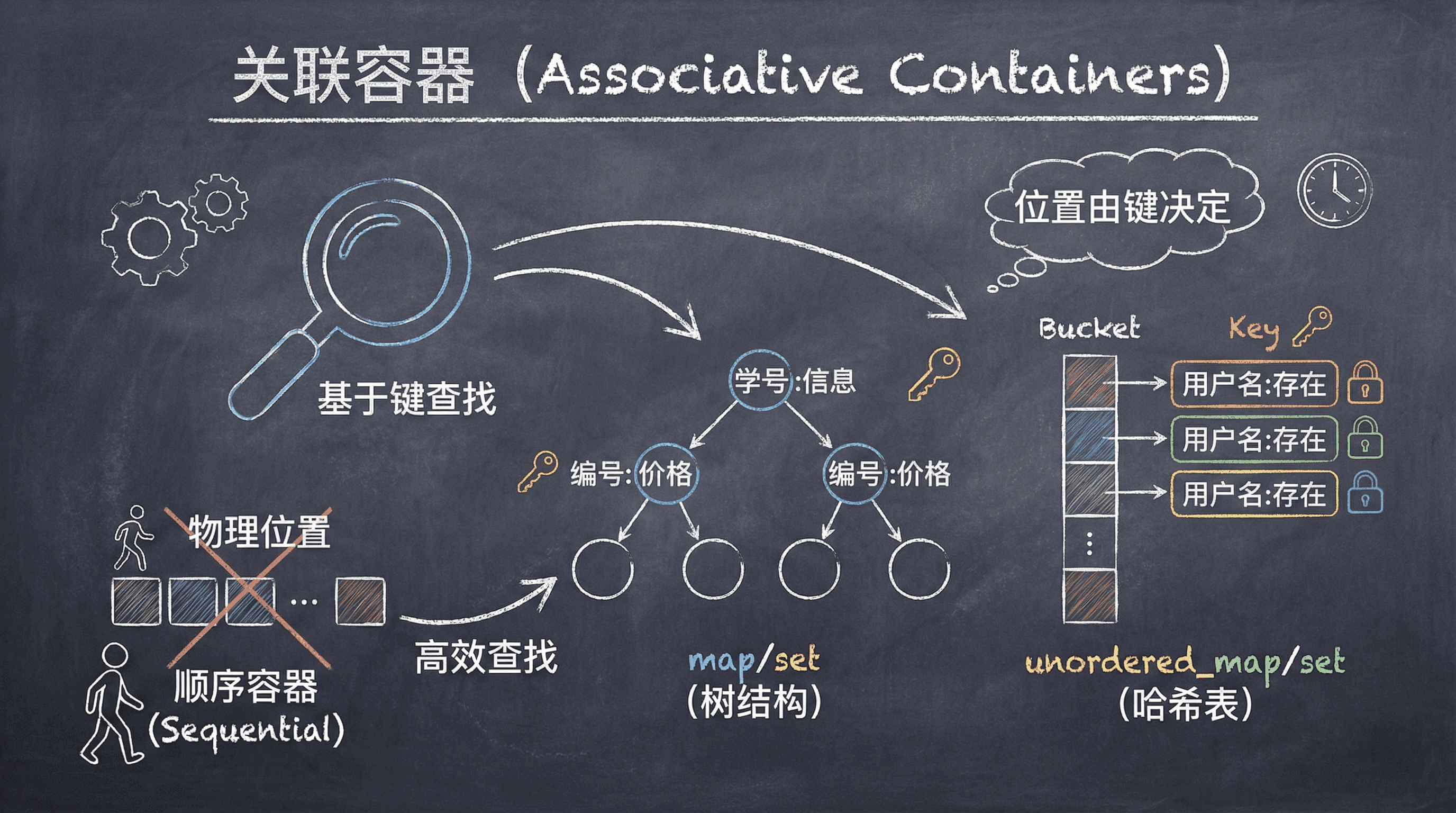
关联容器的分类与特点
C++标准库提供了八种关联容器,它们在三个维度上有所不同:
- 首先是数据组织方式的差异:
set类型只存储键,而map类型存储键值对,其中键作为索引,值表示与该索引关联的数据。 - 其次是键的唯一性要求:某些容器要求键必须唯一,而另一些允许重复的键。
- 最后是元素的存储方式:有些容器按照键的顺序存储元素,而另一些则使用哈希函数来组织元素。
有序关联容器使用比较函数来维护元素的顺序,这类容器包括map(关联数组,存储键值对)、set(键集合)、multimap(允许重复键的map)和multiset(允许重复键的set)。它们的头文件分别是map和set。
无序关联容器使用哈希函数来组织元素,包括unordered_map、unordered_set、unordered_multimap和unordered_multiset。这些容器定义在unordered_map和unordered_set头文件中。
虽然大多数程序员都熟悉向量和链表这样的数据结构,但很多人可能没有使用过关联数据结构。在深入了解这些容器的技术细节之前,让我们先通过实际例子来感受它们的用法和威力。
初步认识关联容器的应用
map:构建映射关系
map容器本质上是一个键值对的集合。我们可以把它想象成一个高效的"字典",其中每个条目都有一个唯一的"词条"(键)和对应的"释义"(值)。这种数据结构通常被称为关联数组,它像普通数组一样支持下标访问,但下标不必是整数,而可以是任何类型的键。
让我们通过一个学生成绩管理的例子来理解map的使用。假设我们需要统计每门课程的选课人数:
cpp
map<string, size_t> courseCount;
string courseName;
while (cin >> courseName) {
++courseCount[courseName];
}
// 输出统计结果
for (const auto &course : courseCount) {
cout << course.first << ":" << course.second
<< "人选课" << endl;
}这个程序读取课程名称,并统计每门课程出现的次数。当我们使用courseCount[courseName]时,如果该课程名称还不在map中,下标运算符会自动创建一个新的条目,键为课程名称,值初始化为0。无论元素是否已存在,我们都可以对其值进行递增操作。
当我们遍历map时,每个元素都是一个pair对象。pair的first成员保存键(课程名称),second成员保存值(选课人数)。需要注意的是,有序容器会按照键的字典序输出结果。
set:高效的存在性检查
set容器就是键的集合,它最适合用来判断某个值是否存在。比如在文本处理中,我们可能需要过滤掉一些常见的停用词。
让我们扩展前面的例子,假设我们要统计课程选课人数,但需要排除一些无效的课程代码:
cpp
map<string, size_t> courseCount;
set<string> invalidCodes = {"TMP", "TEST", "DEBUG", "TEMP",
"NULL", "EMPTY", "INVALID"};
string courseName;
while (cin >> courseName) {
// 只统计有效的课程代码
if (invalidCodes.find(courseName) == invalidCodes.end()) {
在这个改进的版本中,我们首先创建了一个包含无效课程代码的set。然后在统计之前,我们使用find方法检查当前的课程名称是否在无效代码集合中。find方法返回一个迭代器:如果找到了目标元素,迭代器指向该元素;如果没找到,则返回end()迭代器。只有当课程代码不在无效集合中时,我们才进行统计。
关联容器的深入理解
定义和初始化关联容器
关联容器的定义方式与顺序容器类似,但有一些重要的区别。对于map类型,我们必须同时指定键和值的类型;对于set类型,我们只需要指定键的类型。
cpp
map<string, int> studentGrades; // 空的成绩映射
// 使用列表初始化
set<string> departments = {"计算机", "数学", "物理", "化学"};
// 初始化教师信息映射
map<string, string> teachers = {
{"张教授", "计算机系"},
{"李教授", "数学系"},
初始化map时,我们需要将每个键值对包装在花括号中,形成{key, value}的格式。键是第一个元素,值是第二个元素。
标准的map和set要求键必须唯一,但有时我们需要允许重复的键。比如在图书管理系统中,同一个作者可能写了多本书,这时我们就需要使用multimap:
cpp
vector<int> numbers;
for (int i = 0; i < 10; ++i) {
numbers.push_back(i % 5); // 创建包含重复值的序列
numbers.push_back(i % 5);
}
set<int> uniqueNumbers(numbers.cbegin(), numbers.cend
这个例子展示了set和multiset的区别:set自动去除重复元素,只保留唯一值;而multiset保留所有元素,包括重复的。
键类型的要求与自定义比较
有序关联容器对键类型有特殊要求:键类型必须定义一种比较元素的方法。默认情况下,标准库使用键类型的<运算符来比较键。这意味着键类型必须支持严格弱序关系,这种关系具有以下特性:
两个键不能同时"小于"对方;如果键A小于键B,且键B小于键C,那么键A必须小于键C;如果两个键互不小于对方,我们称它们"等价"。
在实际应用中,大多数内置类型和标准库类型都满足这些要求。但当我们使用自定义类型作为键时,可能需要提供自定义的比较函数。
假设我们有一个表示学生的类,我们希望按照学号对学生进行排序:
cpp
struct Student {
string id;
string name;
int grade;
};
bool compareById(const Student &lhs, const Student &rhs) {
return lhs.id < rhs.id;
}
// 使用自定义比较函数的multiset
multiset<Student, decltype(compareById)*> studentSet(compareById);这里我们定义了一个比较函数compareById,然后在定义multiset时指定了这个函数的类型。我们使用decltype来获取函数类型,并加上*表示这是一个函数指针类型。
pair类型:理解键值对
在深入学习关联容器的操作之前,我们需要了解pair类型。pair是一个模板类型,定义在utility头文件中,它可以保存两个数据成员。
cpp
pair<string, int> studentInfo; // 保存学生姓名和年龄
pair<string, vector<int>> courseScores; // 保存课程名和成绩列表
// 使用初始化列表创建pair
pair<string, string> authorBook{"鲁迅", "朝花夕拾"};pair的两个数据成员是公开的,分别命名为first和second。我们可以直接访问这些成员:
cpp
cout << "作者:" << authorBook.first << endl;
cout << "作品:" << authorBook.second << endl;标准库还提供了make_pair函数来创建pair对象:
cpp
auto bookInfo = make_pair("红楼梦", 1200); // 自动推断类型当我们需要从函数返回两个值时,pair特别有用:
cpp
pair<bool, string> validateUser(const string &username) {
if (username.empty()) {
return {false, "用户名不能为空"};
}
if (username.length() < 3) {
return {false, "用户名长度至少3个字符"};
}
return {true
关联容器的核心操作
迭代器的特殊性质
关联容器的迭代器具有一些特殊性质。对于map类型,解引用迭代器得到的是一个pair对象,其中first成员是const键,second成员是对应的值:
cpp
map<string, int> examScores = {{"张三", 85}, {"李四", 92}, {"王五", 78}};
auto mapIter = examScores.begin();
cout << "学生:" << mapIter->first << endl; // 输出键
cout << "成绩:" << mapIter->second << endl; // 输出值
对于set类型,虽然定义了iterator和const_iterator类型,但两者都只提供只读访问。这是因为set中的键也是const的:
cpp
set<int> numbers = {1, 3, 5, 7, 9};
set<int>::iterator setIter = numbers.begin();
if (setIter != numbers.end()) {
// *setIter = 42; // 错误!set中的键是只读的
cout << *setIter << endl; // 正确:可以读取键
}当我们遍历关联容器时,元素按照键的升序返回:
cpp
map<string, int> scores = {{"物理", 88}, {"数学", 95}, {"化学", 82}};
for (const auto &subject : scores) {
cout << subject.first << ": " << subject.second << "分" << endl;
}
// 输出顺序:化学、数学、物理(按字典序)添加元素的策略
关联容器提供了多种添加元素的方法。insert成员函数是最通用的方法:
cpp
set<string> courses;
courses.insert("数据结构");
courses.insert("算法分析");
// 使用迭代器范围插入
vector<string> newCourses = {"操作系统", "数据库", "网络原理"};
courses.insert(newCourses.begin(), newCourses.end());
// 使用初始化列表插入
courses.insert({对于map类型,我们需要插入键值对。有多种方法可以创建这样的pair对象:
cpp
map<string, int> inventory;
// 使用花括号初始化(推荐)
inventory.insert({"苹果", 50});
// 使用make_pair
inventory.insert(make_pair("香蕉", 30));
// 显式构造pair
inventory.insert(pair<string, int>("橙子", 25));
// 使用value_type
inventory.检测插入结果
对于要求唯一键的容器,insert操作返回一个pair,告诉我们插入是否成功。返回的pair的first成员是指向具有给定键的元素的迭代器,second成员是一个布尔值,指示元素是否被插入:
cpp
map<string, size_t> wordCount;
string word = "hello";
auto result = wordCount.insert({word, 1});
if (!result.second) { // 如果插入失败(元素已存在)
++result.first->second; // 递增计数器
}这种模式在计数程序中很常见。我们尝试插入一个新的键值对,如果键已经存在,就增加对应的计数。
多重容器的插入
对于允许重复键的容器,insert总是成功插入元素,并返回指向新元素的迭代器:
cpp
multimap<string, string> authorBooks;
authorBooks.insert({"金庸", "射雕英雄传"});
authorBooks.insert({"金庸", "神雕侠侣"}); // 总是成功插入
authorBooks.insert({"金庸", "倚天屠龙记"});删除元素的方式
关联容器提供了几种删除元素的方法。我们可以通过迭代器删除单个元素或一个范围的元素:
cpp
map<string, int> scores = {{"数学", 95}, {"物理", 88}, {"化学", 92}};
// 删除指定位置的元素
auto iter = scores.find("物理");
if (iter != scores.end()) {
scores.erase(iter);
}
// 删除指定键的所有元素
size_t
对于唯一键容器,erase返回0或1,表示是否找到并删除了元素。对于多重键容器,返回值可能大于1:
cpp
multimap<string, string> phoneBook;
phoneBook.insert({"张三", "13800000001"});
phoneBook.insert({"张三", "13800000002"});
size_t removed = phoneBook.erase("张三");
cout << "删除了" << removed << "个电话号码" << endl; // 输出:删除了2个电话号码map的下标操作
map和unordered_map支持下标操作,这是它们独有的特性。下标操作接受一个键,返回关联的值。但是要特别注意:如果键不存在,下标操作会自动插入一个新元素:
cpp
map<string, int> studentAges;
studentAges["张三"] = 20; // 插入新元素
studentAges["李四"] = 21;
cout << studentAges["张三"] << endl; // 输出:20
cout << studentAges["王五"] << endl; // 输出:0(自动插入并值初始化)
// 现在map中有三个元素了
cout << "学生总数:" << studentAges.由于下标操作可能插入新元素,我们只能对非const的map使用下标操作。下标操作返回的是mapped_type对象(即值类型),而解引用map迭代器得到的是value_type对象(即pair类型)。
如果我们只想检查某个键是否存在而不想插入新元素,应该使用find或count:
cpp
if (studentAges.find("赵六") != studentAges.end()) {
cout << "找到赵六的年龄:" << studentAges["赵六"] << endl;
} else {
cout << "赵六不在记录中" << endl;
}查找元素的技巧
关联容器提供了多种查找元素的方法。find是最基本的查找操作,它返回指向找到元素的迭代器,如果没找到则返回end()迭代器:
cpp
set<string> validUsers = {"admin", "user1", "user2", "guest"};
string username = "user1";
auto found = validUsers.find(username);
if (found != validUsers.end()) {
cout << "用户" << username << "验证通过" << endl;
}
count方法返回具有给定键的元素数量。对于唯一键容器,结果只能是0或1;对于多重键容器,结果可能大于1:
cpp
cout << validUsers.count("admin") << endl; // 输出:1
cout << validUsers.count("hacker") << endl; // 输出:0在多重键容器中查找元素更加复杂,因为可能有多个元素具有相同的键。标准库提供了几种方法来处理这种情况。最直观的方法是结合使用find和count:
cpp
multimap<string, string> courseTeachers;
courseTeachers.insert({"数据结构", "张教授"});
courseTeachers.insert({"数据结构", "李教授"});
courseTeachers.insert({"算法分析", "王教授"});
string course = "数据结构";
auto teacherCount = courseTeachers.count(course);
auto iter = courseTeachers.
更高效的方法是使用lower_bound和upper_bound:
cpp
auto lowerIter = courseTeachers.lower_bound(course);
auto upperIter = courseTeachers.upper_bound(course);
for (auto iter = lowerIter; iter != upperIter; ++iter) {
cout << course << "由" << iter->second << "授课" << endl;
}lower_bound返回指向第一个不小于给定键的元素的迭代器,upper_bound返回指向第一个大于给定键的元素的迭代器。这两个迭代器构成一个范围,包含所有具有给定键的元素。
最直接的方法是使用equal_range,它返回一个pair,包含lower_bound和upper_bound的结果:
cpp
auto range = courseTeachers.equal_range(course);
for (auto iter = range.first; iter != range.second; ++iter) {
cout << course << "由" << iter->second << "授课" << endl;
}实际应用:文本转换程序
为了展示关联容器在实际编程中的应用,让我们构建一个文本转换程序。这个程序读取两个文件:第一个文件包含转换规则,每条规则指定一个单词及其替换内容;第二个文件包含要转换的文本。
假设我们的转换规则文件包含:
shell
很好 excellent
不错 good
一般 okay
较差 poor
很差 terrible要转换的文本是:
shell
这次考试成绩很好
那个项目做得不错
这个方案一般
服务质量较差程序应该输出:
shell
这次考试成绩excellent
那个项目做得good
这个方案okay
服务质量poor整体程序结构
我们的解决方案包含三个函数:transformText管理整体流程,buildTransformMap构建转换映射,applyTransform执行单词转换。
cpp
void transformText(ifstream &ruleFile, ifstream &inputFile) {
auto transformMap = buildTransformMap(ruleFile);
string line;
while (getline(inputFile, line)) {
istringstream lineStream(line);
string word;
bool firstWord = true;
while (lineStream >> word) {
if (firstWord) {
这个函数首先调用buildTransformMap构建转换规则映射,然后逐行读取输入文件。对于每一行,我们使用istringstream将其分解为单词,并对每个单词应用转换规则。
构建转换映射
cpp
map<string, string> buildTransformMap(ifstream &ruleFile) {
map<string, string> transformMap;
string key, value;
while (ruleFile >> key && getline(ruleFile, value)) {
if (value.size() > 1) {
transformMap[key] = value.substr(1); // 跳过前导空格
这个函数读取规则文件,每条规则包含一个要转换的单词和对应的替换文本。我们使用>>读取第一个单词作为键,然后用getline读取该行的剩余部分作为值。由于getline不会跳过前导空格,我们需要使用substr(1)去掉键和值之间的空格。
执行单词转换
cpp
const string& applyTransform(const string &word,
const map<string, string> &transformMap) {
auto foundIter = transformMap.find(word);
if (foundIter != transformMap.cend()) {
return foundIter->second;
} else {
return word;
}
转换函数接受一个单词和转换映射,返回转换后的结果。我们使用find查找单词是否在映射中存在,如果存在就返回对应的转换结果,否则返回原始单词。
文本转换引擎
无序容器的应用与优化
C++11引入的无序关联容器使用哈希函数而不是比较操作来组织元素。当键类型没有明显的排序关系,或者当维护元素顺序的代价过高时,无序容器是理想的选择。
无序容器提供与有序容器相同的操作接口,这意味着我们可以很容易地在两者之间切换:
cpp
// 使用无序map重写词频统计程序
unordered_map<string, size_t> wordFreq;
string word;
while (cin >> word) {
++wordFreq[word];
}
for (const auto &entry : wordFreq) {
cout << entry.first << " 出现 " << entry.second << " 次" << endl;
}这个程序与使用有序map的版本几乎完全相同,唯一的区别是容器类型声明。但是输出的顺序会有所不同:有序容器按照键的字典序输出,而无序容器的输出顺序是不确定的。
虽然哈希容器在理论上具有更好的平均性能,但在实践中获得良好的性能往往需要仔细的性能测试和调优。通常,除非有明确的性能需求或键类型本身无法排序,否则使用有序容器往往更容易获得稳定的性能。
无序容器将元素组织在一系列桶中,每个桶包含零个或多个元素。容器使用哈希函数将元素映射到桶。为了访问元素,容器首先计算元素的哈希码,然后在对应的桶中搜索元素。
理想情况下,哈希函数会将每个特定值映射到唯一的桶。但是,允许不同的键映射到相同的桶。当一个桶包含多个元素时,需要顺序搜索来找到目标元素。
cpp
unordered_map<string, int> studentIds;
// 添加一些数据...
// 检查容器的哈希性能
cout << "桶的数量:" << studentIds.bucket_count() << endl;
cout << "负载因子:" << studentIds.load_factor() << endl;
cout << "最大负载因子:" << studentIds.max_load_factor() << endl;
// 如果负载因子过高,可以主动重新哈希
if (studentIds.load_factor()
对于内置类型和标准库类型(如string),标准库已经提供了哈希函数。但是对于自定义类型,我们需要提供自己的哈希函数和相等比较操作:
cpp
struct Student {
string id;
string name;
bool operator==(const Student &other) const {
return id == other.id;
}
};
// 自定义哈希函数
struct StudentHash {
size_t operator()(const Student &s) const {
或者,我们可以使用函数来定义哈希和相等操作:
cpp
size_t studentHasher(const Student &s) {
return hash<string>()(s.id);
}
bool studentEqual(const Student &lhs, const Student &rhs) {
return lhs.id == rhs.id;
}
unordered_multiset<Student, decltype(studentHasher)*, decltype
通过理解和掌握关联容器,我们能够编写更加高效和优雅的程序。这些容器不仅提供了快速的查找和检索能力,还通过其丰富的接口支持各种复杂的数据操作需求。在实际开发中,选择合适的关联容器类型往往能够显著提升程序的性能和可维护性。
练习
练习 1:map的基本使用
编写一个程序,使用map存储学生的姓名和成绩,然后实现查找和显示所有学生的功能。
cpp
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main() {
map<string, int> scores; // 姓名 -> 成绩
// 添加学生成绩
scores["张三"] = 85;
scores["李四"] = 90;
scores["王五"] = 78;
练习 2:multimap的使用
编写一个程序,使用multimap存储学生的姓名和课程,一个学生可以选择多门课程。
cpp
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main() {
multimap<string, string> courses; // 姓名 -> 课程
// 添加选课信息
courses.insert({"张三", "数学"});
courses.insert({"张三", "英语"});
courses.insert({
练习 3:set的使用
编写一个程序,使用set存储一组不重复的数字,然后检查某个数字是否存在。
cpp
#include <iostream>
#include <set>
using namespace std;
int main() {
set<int> numbers;
// 添加数字(set自动去重)
numbers.insert(10);
numbers.insert(20);
numbers.insert(30);
numbers.insert(20); // 重复,不会被添加
numbers.
练习 4:统计单词出现次数
编写一个程序,统计一段文本中每个单词出现的次数,并输出统计结果。
cpp
#include <iostream>
#include <map>
#include <string>
#include <sstream>
using namespace std;
int main() {
string text = "hello world hello cpp world cpp";
map<string, int> wordCount;
// 将文本分割成单词
istringstream iss(text);
string word;
while (iss >> word) {
wordCount[word]
练习 5:综合应用——简单的电话簿
实现一个简单的电话簿程序,支持添加联系人、查找电话号码和显示所有联系人。
cpp
#include <iostream>
#include <map>
#include <string>
using namespace std;
class PhoneBook {
private:
map<string, string> contacts; // 姓名 -> 电话号码
public:
// 添加联系人
void addContact(const string& name, const string& phone) {
contacts[name] =