分治 | 自在学
分治法
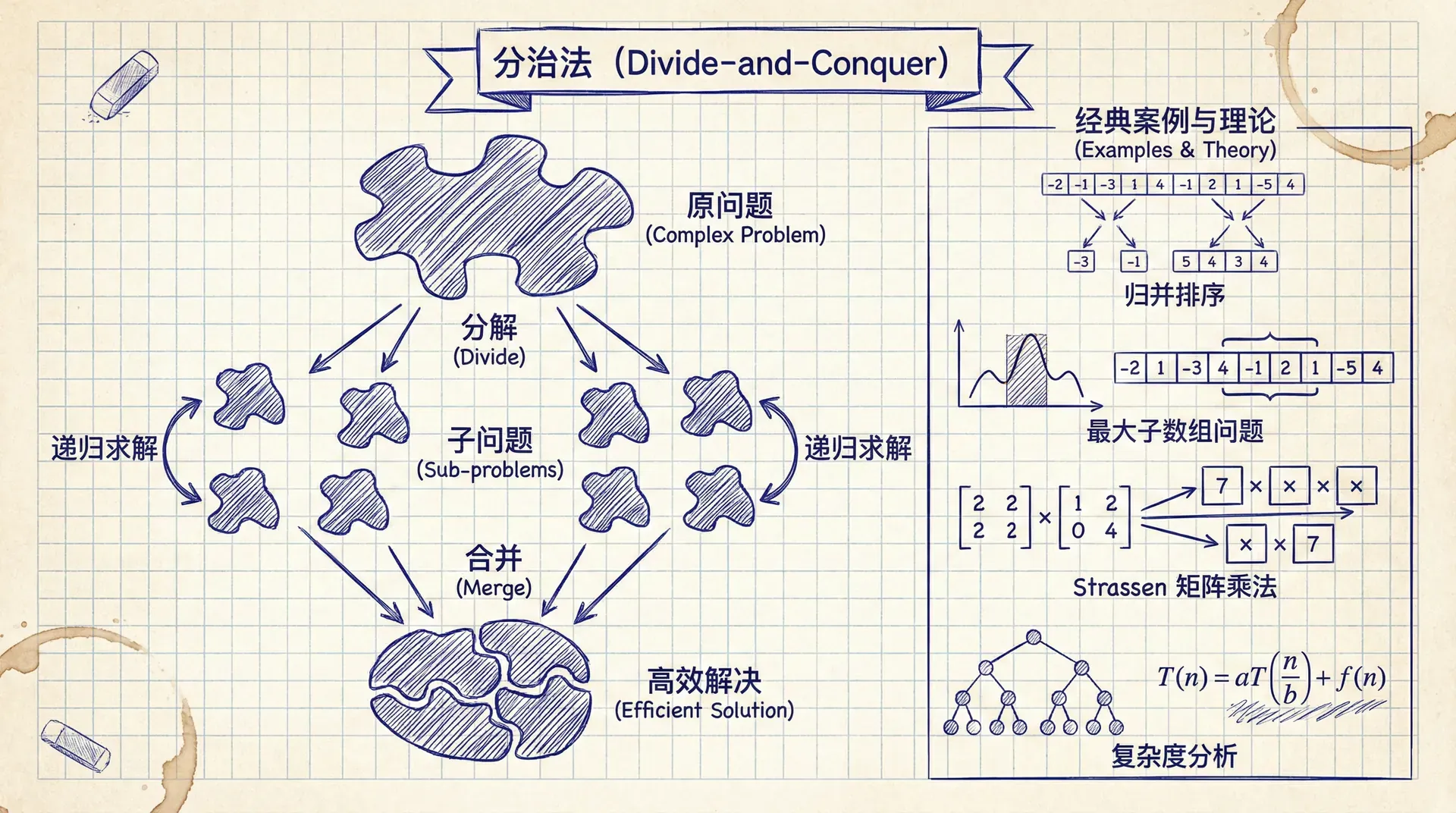
分治法(Divide-and-Conquer)是算法设计中的核心范式之一,通过将复杂问题分解为结构相似的子问题,递归求解后合并结果,从而高效地解决原问题。
在算法入门部分,我们已通过归并排序初步了解了分治法的基本思想。本章将系统阐述分治法的理论框架,并通过最大子数组问题和 Strassen 矩阵乘法两个经典案例,深入探讨分治法在算法设计中的应用及其复杂度分析。
分治法的核心思想
分治法采用递归策略,其执行过程可形式化为三个基本阶段:
分解(Divide) :将原问题 P P P k k k P 1 , P 2 , … , P k P_1, P_2, \ldots, P_k P 1 , P 2 , … , P k P i P_i P i P P P
解决(Conquer) :递归地求解各子问题。若子问题规模足够小,可直接求解(称为基本情况 ,Base Case);否则继续递归分解(称为递归情形 ,Recursive Case)。
合并(Combine) :将各子问题的解 S 1 , S 2 , … , S k S_1, S_2, \ldots, S_k S 1 , S 2 , … , S
分治法并非适用于所有问题。一个问题能够有效应用分治法,需满足以下必要条件:
可分解性 :问题可分解为规模更小的同类型子问题,且子问题规模严格小于原问题规模子问题独立性 :子问题之间相互独立,求解一个子问题不影响其他子问题的求解过程合并可行性 :子问题的解可在多项式时间内合并为原问题的解规模递减性 :子问题规模必须严格递减,确保递归过程在有限步内终止 分治法的优势与局限
最大子数组问题
最大子数组问题 (Maximum Subarray Problem)是算法设计中的经典问题。给定一个包含 n n n A [ 1.. n ] A[1..n] A [ 1.. n ] A [ i ] A[i] A [ i ] i i i A A A
形式化地,我们需要找到索引 i i i j j j 1 ≤ i ≤ j ≤ n 1 \leq i \leq j \leq n 1 ≤ i ≤ j ≤ n ∑ k = i j A [ k ] \sum_{k=i}^{j} A[k] ∑
例如,对于数组 A = [ 13 , − 3 , − 25 , 20 , − 3 , − 16 , − 23 , 18 , 20 , − 7 , 12 , − 5 , − 22 , 15 , − 4 , 7 ] A = [13, -3, -25, 20, -3, -16, -23, 18, 20, -7, 12, -5, -22, 15, -4, 7] A = [ 13 , − 3 , − 25 , 20 , − 3 , − 16 , − 23 , 18 , 20 , − 7 , 12 , − 5
暴力求解方法需要检查所有可能的子数组,共有 ( n + 1 2 ) = n ( n + 1 ) 2 \binom{n+1}{2} = \frac{n(n+1)}{2} ( 2 n + 1 ) = 2 n ( n + 1 )
分治求解策略
对于数组 A [ low . . high ] A[\text{low}..\text{high}] A [ low .. high ] mid = ⌊ ( low + high ) / 2 ⌋ \text{mid} = \lfloor(\text{low} + \text{high})/2\rfloor mid = ⌊( low + high ) /2 ⌋
完全位于左子数组 A [ low . . mid ] A[\text{low}..\text{mid}] A [ low .. mid ]
完全位于右子数组 A [ mid + 1.. high ] A[\text{mid}+1..\text{high}] A [ mid + 1.. high ]
跨越中点 mid \text{mid} mid A [ mid ] A[\text{mid}] A [ mid ] A [
前两种情形可通过递归求解。第三种情形"跨越中点"是合并步骤的关键。跨越中点的最大子数组必然由两部分组成:左半部分 A [ i . . mid ] A[i..\text{mid}] A [ i .. mid ] A [ mid + 1.. j ] A[\text{mid}+1..j] A [ mid + 1.. j ] i ∈ [ low , mid ] i \in [\text{low}, \text{mid}] i ∈ [ low , mid ] j ∈ [ mid +
我们可在 Θ ( high − low ) \Theta(\text{high} - \text{low}) Θ ( high − low ) ( i , j ) (i, j) ( i , j ) mid \text{mid} mid
以下是寻找跨越中点的最大子数组的算法:
FIND - MAX - CROSSING - SUBARRAY(A, low, mid, high) 1 left - sum = - ∞ // 初始化左半部分最大和 2 sum = 0 // 当前累加和 3 for i = mid downto low // 从mid向左扫描 4 sum = sum + A[i] // 累加当前元素 5 if sum > left - 基于上述辅助函数,可构造完整的分治算法:
FIND - MAXIMUM - SUBARRAY(A, low, high) 1 if high == low // 基本情况:只有一个元素 2 return (low, high, A[low]) // 返回该元素本身 3 else 4 mid = floor((low + high) / 2 ) // 计算中点 5 (left - low, left - high, left - sum ) = FIND - 时间复杂度分析 :设 T ( n ) T(n) T ( n ) n n n n / 2 n/2 n /2 Θ ( n ) \Theta(n) Θ ( n )
T ( n ) = 2 T ( n / 2 ) + Θ ( n ) T(n) = 2T(n/2) + \Theta(n) T ( n ) = 2 T ( n /2 ) + Θ ( n )
根据主方法(Master Method),该递推式的解为 T ( n ) = Θ ( n lg n ) T(n) = \Theta(n \lg n) T ( n ) = Θ ( n lg n ) Θ ( n 2 ) \Theta(n^2) Θ ( n 2 )
线性时间解法:Kadane 算法
尽管分治法将最大子数组问题的时间复杂度从 Θ ( n 2 ) \Theta(n^2) Θ ( n 2 ) Θ ( n lg n ) \Theta(n \lg n) Θ ( n lg n ) Kadane 算法 。
Kadane 算法的核心思想基于动态规划:维护两个变量,max_ending_here 表示以当前位置结尾的最大子数组和,max_so_far 表示迄今为止找到的最大子数组和。算法的关键洞察是:若以位置 i − 1 i-1 i − 1 i i i
KADANE - MAXIMUM - SUBARRAY(A) 1 max - so - far = A[ 1 ] // 全局最大和,初始化为第一个元素 2 max - ending - here = A[ 1 ] // 以当前位置结尾的最大和 3 start = 1 // 最大子数组起始位置 4 end = 1 // 最大子数组结束位置 5 复杂度分析 :Kadane 算法的时间复杂度为 Θ ( n ) \Theta(n) Θ ( n ) Θ ( 1 ) \Theta(1) Θ ( 1 )
Strassen 矩阵乘法
矩阵乘法是线性代数中的基本运算,在科学计算、机器学习、图像处理等领域有广泛应用。给定两个 n × n n \times n n × n A A A B B B C = A ⋅ B C = A \cdot B C = A ⋅ B n × n n \times n n ×
c i j = ∑ k = 1 n a i k b k j c_{ij} = \sum_{k=1}^{n} a_{ik} b_{kj} c ij = ∑ k = 1 n a ik
标准矩阵乘法算法需要计算 n 2 n^2 n 2 n n n n − 1 n-1 n − 1 Θ ( n 3 ) \Theta(n^3) Θ ( n 3 )
朴素的分治解法
采用分治法,将 n × n n \times n n × n ( n / 2 ) × ( n / 2 ) (n/2) \times (n/2) ( n /2 ) × ( n /2 )
C = ( C 11 C 12 C 21 C 22 ) , A = ( A 11 A 12 A 21 A 22 ) , B = ( B 11 B 12 B 21 B 22 ) C = \begin{pmatrix} C_{11} & C_{12} \\ C_{21} & C_{22} \end{pmatrix}, \quad
A = \begin{pmatrix} A_{11} & A_{12} \\ A_{21} & A_{22} \end{pmatrix}, \quad
B = \begin{pmatrix} B_{11} & B_{12} \\ B_{21} & B_{22} \end{pmatrix} C = ( 则矩阵乘法可表示为:
( C 11 C 12 C 21 C 22 ) = ( A 11 A 12 A 21 A 22 ) ( B 11 B 12 B 21 B 22 ) \begin{pmatrix} C_{11} & C_{12} \\ C_{21} & C_{22} \end{pmatrix} =
\begin{pmatrix} A_{11} & A_{12} \\ A_{21} & A_{22} \end{pmatrix}
\begin{pmatrix} B_{11} & B_{12} \\ B_{21} & B_{22} \end{pmatrix} ( C 展开后得到:
C 11 = A 11 B 11 + A 12 B 21 C 12 = A 11 B 12 + A 12 B 22 C 21 = A 21 B 11 + A 22 B 21 C 22 = A 21 B 12 + A 22 B 22 \begin{align}
C_{11} &= A_{11}B_{11} + A_{12}B_{21} \\
C_{12} &= A_{11}B_{12} + A_{12}B_{22} \\
C_{21} &= A_{21}B_{11} + A_{22}B_{21} \\
C_{22} &= A_{21}B_{12} + A_{22}B_{22}
\end{align} C 该分治策略需要 8 次 ( n / 2 ) × ( n / 2 ) (n/2) \times (n/2) ( n /2 ) × ( n /2 ) Θ ( n 2 ) \Theta(n^2) Θ ( n 2 )
T ( n ) = 8 T ( n / 2 ) + Θ ( n 2 ) T(n) = 8T(n/2) + \Theta(n^2) T ( n ) = 8 T ( n /2 ) + Θ ( n 2 )
根据主方法,a = 8 a = 8 a = 8 b = 2 b = 2 b = 2 f ( n ) = Θ ( n 2 ) f(n) = \Theta(n^2) f ( n ) = Θ ( n 2 ) log b a = log 2
Strassen 算法
1969 年,Volker Strassen 提出了一种突破性的矩阵乘法算法,通过巧妙的代数变换,将子问题的矩阵乘法次数从 8 次减少至 7 次,代价是增加了加法和减法运算次数(共 18 次)。其递推关系为:
T ( n ) = 7 T ( n / 2 ) + Θ ( n 2 ) T(n) = 7T(n/2) + \Theta(n^2) T ( n ) = 7 T ( n /2 ) + Θ ( n 2 )
复杂度分析 :根据主方法,a = 7 a = 7 a = 7 b = 2 b = 2 b = 2 f ( n ) = Θ ( n 2 ) f(n) = \Theta(n^2) f ( n ) = Θ ( n 2 ) log b a = log
T ( n ) = Θ ( n log 2 7 ) = Θ ( n 2.81 ) T(n) = \Theta(n^{\log_2 7}) = \Theta(n^{2.81}) T ( n ) = Θ ( n l o g 2 7 ) = Θ ( n
与标准算法的 Θ ( n 3 ) \Theta(n^3) Θ ( n 3 )
Strassen 算法的执行步骤 :
分解阶段 :将矩阵 A A A B B B C C C ( n / 2 ) × ( n / 2 ) (n/2) \times (n/2) ( n /2 ) × ( n /2 )
求解递推式的方法
分治算法的时间复杂度通常由形如 T ( n ) = a T ( n / b ) + f ( n ) T(n) = aT(n/b) + f(n) T ( n ) = a T ( n / b ) + f ( n ) a ≥ 1 a \geq 1 a ≥ 1 b > 1 b > 1 b > 1
代入法
代入法 (Substitution Method)是一种严格的证明技术,通过数学归纳法验证对递推式解的猜测。其基本步骤为:
猜测解的形式 :基于递归树、经验或类似问题的解,猜测 T ( n ) T(n) T ( n ) 验证猜测 :使用数学归纳法证明猜测的正确性,通常需要确定合适的常数
示例:证明 T ( n ) = 2 T ( n / 2 ) + n T(n) = 2T(n/2) + n T ( n ) = 2 T ( n /2 ) + n T ( n ) = O ( n lg n ) T(n) = O(n \lg n) T ( n ) = O ( n lg n )
猜测 :存在常数 c > 0 c > 0 c > 0 T ( n ) ≤ c n lg n T(n) \leq cn \lg n T ( n ) ≤ c n lg n n n n
归纳证明 :假设对于所有 m < n m < n m < n T ( m ) ≤ c m lg m T(m) \leq cm \lg m T ( m ) ≤ c m lg m
T ( n ) = 2 T ( n / 2 ) + n ≤ 2 ⋅ c ( n / 2 ) lg ( n / 2 ) + n = c n lg ( n / 2 ) + n = c n ( lg n − lg 2 ) + n = c n lg n − c n + n = c n lg n − ( 为使 T ( n ) ≤ c n lg n T(n) \leq cn \lg n T ( n ) ≤ c n lg n ( c − 1 ) n ≥ 0 (c-1)n \geq 0 ( c − 1 ) n ≥ 0 c ≥ 1 c \geq 1 c ≥ 1
在应用代入法时,必须严格导出所假设的不等式形式。有时需要强化归纳假设,即从猜测中减去一个低阶项(如 T ( n ) ≤ c n lg n − d n T(n) \leq cn \lg n - dn T ( n ) ≤ c n lg n − d n
递归树法
递归树法 (Recursion-Tree Method)通过可视化递推关系来生成解的猜测,特别适用于分析复杂递推式。在递归树中,每个节点表示一个子问题的成本,树的深度对应递归的层数。
示例:分析 T ( n ) = 3 T ( n / 4 ) + c n 2 T(n) = 3T(n/4) + cn^2 T ( n ) = 3 T ( n /4 ) + c n 2
分析过程 :
树的高度 :递归在 n / 4 i = 1 n/4^i = 1 n / 4 i = 1 i = log 4 n i = \log_4 n i = log 4 n log 4 n \log_4 n log
T ( n ) = ∑ i = 0 log 4 n c n 2 ( 3 16 ) i = c n 2 ∑ i = 0 log 4 n ( 3 16 ) i T(n) = \sum_{i=0}^{\log_4 n} cn^2\left(\frac{3}{16}\right)^i = cn^2 \sum_{i=0}^{\log_4 n} \left(\frac{3}{16}\right)^i T ( n ) = ∑ i = 0 l o g 4
由于 3 / 16 < 1 3/16 < 1 3/16 < 1 T ( n ) = O ( n 2 ) T(n) = O(n^2) T ( n ) = O ( n 2 ) T ( n ) = Θ ( n 2 ) T(n) = \Theta(n^2) T ( n ) =
递归树法的一般步骤 :
主方法
主方法 (Master Method)提供了求解形如 T ( n ) = a T ( n / b ) + f ( n ) T(n) = aT(n/b) + f(n) T ( n ) = a T ( n / b ) + f ( n ) a ≥ 1 a \geq 1 a ≥ 1 b > 1 b > 1 b >
主定理 :设 T ( n ) = a T ( n / b ) + f ( n ) T(n) = aT(n/b) + f(n) T ( n ) = a T ( n / b ) + f ( n ) a ≥ 1 a \geq 1 a ≥ 1 b > 1 b > 1 b > 1
情况一 :若 f ( n ) = O ( n log b a − ε ) f(n) = O(n^{\log_b a - \varepsilon}) f ( n ) = O ( n l o g b a − ε ) ε > 0 \varepsilon > 0 ε >
主方法为分治算法的时间复杂度分析提供了系统化的工具。通过比较 f ( n ) f(n) f ( n ) n log b a n^{\log_b a} n l o g b a
应用主方法的步骤
识别参数 :确定 a a a b b b f ( n ) f(n) f ( n ) 计算关键值 :计算 log b a \log_b a log b a n log b a n^{\log_b a} n
经典应用示例
示例 1:归并排序
递推式:T ( n ) = 2 T ( n / 2 ) + n T(n) = 2T(n/2) + n T ( n ) = 2 T ( n /2 ) + n
参数:a = 2 a = 2 a = 2 b = 2 b = 2 b = 2 f ( n ) = n f(n) = n
示例 2:二分查找
递推式:T ( n ) = T ( n / 2 ) + 1 T(n) = T(n/2) + 1 T ( n ) = T ( n /2 ) + 1
参数:a = 1 a = 1 a = 1 b = 2 b = 2 b = 2 f ( n ) = 1 f(n) = 1
示例 3:Strassen 矩阵乘法
递推式:T ( n ) = 7 T ( n / 2 ) + Θ ( n 2 ) T(n) = 7T(n/2) + \Theta(n^2) T ( n ) = 7 T ( n /2 ) + Θ ( n 2 )
参数:a = 7 a = 7 a = 7 b = 2 b = 2
主方法仅适用于特定形式的递推关系。若递推式不符合 T ( n ) = a T ( n / b ) + f ( n ) T(n) = aT(n/b) + f(n) T ( n ) = a T ( n / b ) + f ( n ) f ( n ) f(n) f ( n )
小练习
分治法的适用性分析 :判断以下问题是否适合采用分治法求解,并给出理论依据:
计算斐波那契数列的第 n n n
寻找数组中的最大值
判断一个字符串是否为回文串
计算两个大整数的乘积
寻找数组中的众数(出现次数最多的元素)
分治算法设计 :设计一个分治算法寻找数组中的第二大元素。要求:
时间复杂度为 O ( n ) O(n) O ( n )
空间复杂度为 O ( lg n ) O(\lg n) O ( lg n )
最近点对问题 :给定平面上 n n n
设计一个基于分治的算法
分析算法的时间复杂度
实现算法的关键步骤
逆序对计数 :给定一个数组 A [ 1.. n ] A[1..n]
k
k
=
i
j
A
[
k
]
,
−
22
,
15
,
−
4
,
7
]
A [ 8..11 ] = [ 18 , 20 , − 7 , 12 ] A[8..11] = [18, 20, -7, 12] A [ 8..11 ] = [ 18 , 20 , − 7 , 12 ] Θ ( n 2 )
Θ ( n lg n ) \Theta(n \lg n) Θ ( n lg n ) mid + 1 ] A[\text{mid}+1] A [ mid + 1 ]
1 , high ] j \in [\text{mid}+1, \text{high}] j ∈ [ mid + 1 , high ]
sum
//
更新最大和
6 left - sum = sum
7 max - left = i // 记录左边界
8 right - sum = - ∞ // 初始化右半部分最大和
9 sum = 0 // 重置累加和
10 for j = mid + 1 to high // 从mid + 1向右扫描
11 sum = sum + A[j] // 累加当前元素
12 if sum > right - sum // 更新最大和
13 right - sum = sum
14 max - right = j // 记录右边界
15 return ( max - left, max - right, left - sum + right - sum ) // 返回跨越中点的最大子数组
MAXIMUM
-
SUBARRAY(A, low, mid)
//
递归求解左子数组
6 (right - low, right - high, right - sum ) = FIND - MAXIMUM - SUBARRAY(A, mid + 1 , high) // 递归求解右子数组
7 (cross - low, cross - high, cross - sum ) = FIND - MAX - CROSSING - SUBARRAY(A, low, mid, high) // 求解跨越中点的子数组
8 if left - sum >= right - sum and left - sum >= cross - sum
9 return (left - low, left - high, left - sum ) // 左子数组的解最优
10 elseif right - sum >= left - sum and right - sum >= cross - sum
11 return (right - low, right - high, right - sum ) // 右子数组的解最优
12 else
13 return (cross - low, cross - high, cross - sum ) // 跨越中点的解最优
temp
-
start
=
1
//
临时起始位置
6 for i = 2 to n // 遍历数组
7 if max - ending - here + A[i] > A[i] // 扩展当前子数组更优
8 max - ending - here = max - ending - here + A[i]
9 else // 从当前位置重新开始
10 max - ending - here = A[i]
11 temp - start = i // 更新临时起始位置
12 if max - ending - here > max - so - far // 更新全局最大值
13 max - so - far = max - ending - here
14 start = temp - start // 更新起始位置
15 end = i // 更新结束位置
16 return (start, end, max - so - far) // 返回最大子数组信息
n
b kj
C 11 C 21
C 12 C 22
)
,
A
=
( A 11 A 21 A 12 A 22 ) , B =
( B 11 B 21 B 12 B 22 )
11
C 21
C 12 C 22
)
=
( A 11 A 21 A 12 A 22 ) ( B 11 B 21 B 12 B
11
C 12
C 21
C 22
= A 11 B 11 + A 12 B 21 = A 11 B 12 + A 12 B 22 = A 21 B 11 + A 22 B 21 = A 21 B 12 + A 22 B 22
8 = 3 \log_b a = \log_2 8 = 3 log b a = log 2 8 = 3
n log b a = n 3 n^{\log_b a} = n^3 n l o g b a = n 3 f ( n ) = Θ ( n 2 ) = O ( n 3 − ε ) f(n) = \Theta(n^2) = O(n^{3-\varepsilon}) f ( n ) = Θ ( n 2 ) = O ( n 3 − ε ) ε = 1 > 0 \varepsilon = 1 > 0 ε = 1 > 0 T ( n ) = Θ ( n 3 ) T(n) = \Theta(n^3) T ( n ) = Θ ( n 3 ) 2 7 ≈ 2.81 \log_b a = \log_2 7 \approx 2.81 log b a = log 2 7 ≈ 2.81
n log b a = n log 2 7 ≈ n 2.81 n^{\log_b a} = n^{\log_2 7} \approx n^{2.81} n l o g b a = n l o g 2 7 ≈ n 2.81 f ( n ) = Θ ( n 2 ) = O ( n log 2 7 − ε ) f(n) = \Theta(n^2) = O(n^{\log_2 7 - \varepsilon}) f ( n ) = Θ ( n 2 ) = O ( n l o g 2 7 − ε ) ε = log 2 7 − 2 ≈ 0.81 > 0 \varepsilon = \log_2 7 - 2 \approx 0.81 > 0 ε = log 2 7 − 2 ≈ 0.81 > 0 2.81
)
A 11
构造辅助矩阵 :创建 10 个辅助矩阵 S 1 , S 2 , … , S 10 S_1, S_2, \ldots, S_{10} S 1 , S 2 , … , S 10
S 1 = B 12 − B 22 S 2 = A 11 + A 12 S 3 = A 21 + A 22 S 4 = B 21 − B 11 S 5 = A 11 + A 22 S 6 = B 11 + B 22 S 7 = A 12 − A 22 递归计算乘积 :递归计算 7 个 ( n / 2 ) × ( n / 2 ) (n/2) \times (n/2) ( n /2 ) × ( n /2 ) P 1 , P 2 , … , P 7 P_1, P_2, \ldots, P_7 P 1 , P 2 , … , P 7
P 1 = A 11 ⋅ S 1 = A 11 ( B 12 − B 22 ) P 2 = S 2 ⋅ B 22 = ( A 11 + A 12 ) B 22 P 3 = S 3 ⋅ B 11 = ( A 21 + A 22 ) B 11 P 4 = A 22 ⋅ S 4 = A 22 ( B 21 − B 11 ) P 5 = S 合并阶段 :通过 P i P_i P i C C C
C 11 = P 5 + P 4 − P 2 + P 6 C 12 = P 1 + P 2 C 21 = P 3 + P 4 C 22 = P 5 + P 1 − P 3 − P 7 \begin{align}
C_{11} &= P_5 + P_4 - P_2 + P_6 \\
C_{12} &= P_1 + P_2 \\
C_{21} &= P_3 + P_4 \\
C_{22} &= P_5 + P_1 - P_3 - P_7
\end{align} C 11 C 12 C 21 C 22 可通过代数验证,上述公式正确计算了矩阵乘积 C = A ⋅ B C = A \cdot B C = A ⋅ B
c − 1 ) n \begin{align}
T(n) &= 2T(n/2) + n \\
&\leq 2 \cdot c(n/2) \lg(n/2) + n \\
&= cn \lg(n/2) + n \\
&= cn(\lg n - \lg 2) + n \\
&= cn \lg n - cn + n \\
&= cn \lg n - (c-1)n
\end{align} T ( n ) = 2 T ( n /2 ) + n ≤ 2 ⋅ c ( n /2 ) lg ( n /2 ) + n = c n lg ( n /2 ) + n = c n ( lg n − lg 2 ) + n = c n lg n − c n + n = c n lg n − ( c − 1 ) n
c = 1 c = 1 c = 1
4
n
第 i i i :第 i i i 3 i 3^i 3 i c ( n / 4 i ) 2 c(n/4^i)^2 c ( n / 4 i ) 2 i i i 3 i ⋅ c ( n / 4 i ) 2 = c n 2 ( 3 / 16 ) i 3^i \cdot c(n/4^i)^2 = cn^2(3/16)^i 3 i ⋅ c ( n / 4 i ) 2 = c n 2 ( 3/16
总成本 :对所有层求和:
n
c
n 2
( 16 3 ) i
=
c n 2 ∑ i = 0 l o g 4 n ( 16 3 ) i
Θ
(
n 2
)
1
n log b a n^{\log_b a} n l o g b a
0
T ( n ) = Θ ( n log b a ) T(n) = \Theta(n^{\log_b a}) T ( n ) = Θ ( n l o g b a ) 情况二 :若 f ( n ) = Θ ( n log b a lg k n ) f(n) = \Theta(n^{\log_b a} \lg^k n) f ( n ) = Θ ( n l o g b a lg k n ) k ≥ 0 k \geq 0 k ≥ 0 T ( n ) = Θ ( n log b a lg k + 1 n ) T(n) = \Theta(n^{\log_b a} \lg^{k+1} n) T ( n ) = Θ ( n l o g b a lg k + 1 n k = 0 k = 0 k = 0 T ( n ) = Θ ( n log b a lg n ) T(n) = \Theta(n^{\log_b a} \lg n) T ( n ) = Θ ( n l o g b a lg n ) 情况三 :若 f ( n ) = Ω ( n log b a + ε ) f(n) = \Omega(n^{\log_b a + \varepsilon}) f ( n ) = Ω ( n l o g b a + ε ) ε > 0 \varepsilon > 0 ε > 0 c < 1 c < 1 c < 1 n n n a f ( n / b ) ≤ c f ( n ) af(n/b) \leq cf(n) a f ( n / b ) ≤ c f ( n ) T ( n ) = Θ ( f ( n ) ) T(n) = \Theta(f(n)) T ( n ) = Θ ( f ( n )) l o g b a
比较函数 :比较 f ( n ) f(n) f ( n ) n log b a n^{\log_b a} n l o g b a
应用定理 :根据比较结果,应用主定理的相应情况f ( n ) = n
计算:log 2 2 = 1 \log_2 2 = 1 log 2 2 = 1 n log 2 2 = n n^{\log_2 2} = n n l o g 2 2 = n 比较:f ( n ) = n = Θ ( n 1 ) = Θ ( n log 2 2 ) f(n) = n = \Theta(n^1) = \Theta(n^{\log_2 2}) f ( n ) = n = Θ ( n 1 ) = Θ ( n l o g 2 2 ) k = 0 k = 0 k = 0 结论:T ( n ) = Θ ( n lg n ) T(n) = \Theta(n \lg n) T ( n ) = Θ ( n lg n ) f ( n ) =
1
计算:log 2 1 = 0 \log_2 1 = 0 log 2 1 = 0 n log 2 1 = 1 n^{\log_2 1} = 1 n l o g 2 1 = 1 比较:f ( n ) = 1 = Θ ( 1 ) = Θ ( n log 2 1 ) f(n) = 1 = \Theta(1) = \Theta(n^{\log_2 1}) f ( n ) = 1 = Θ ( 1 ) = Θ ( n l o g 2 1 ) k = 0 k = 0 k = 0 结论:T ( n ) = Θ ( lg n ) T(n) = \Theta(\lg n) T ( n ) = Θ ( lg n )
b
=
2
f ( n ) = Θ ( n 2 ) f(n) = \Theta(n^2) f ( n ) = Θ ( n 2 ) 计算:log 2 7 ≈ 2.81 \log_2 7 \approx 2.81 log 2 7 ≈ 2.81 n log 2 7 ≈ n 2.81 n^{\log_2 7} \approx n^{2.81} n l o g 2 7 ≈ n 2.81 比较:f ( n ) = Θ ( n 2 ) = O ( n 2.81 − ε ) f(n) = \Theta(n^2) = O(n^{2.81 - \varepsilon}) f ( n ) = Θ ( n 2 ) = O ( n 2.81 − ε ) ε = log 2 7 − 2 ≈ 0.81 \varepsilon = \log_2 7 - 2 \approx 0.81 ε = log 2 7 − 2 ≈ 0.81 结论:T ( n ) = Θ ( n log 2 7 ) = Θ ( n 2.81 ) T(n) = \Theta(n^{\log_2 7}) = \Theta(n^{2.81}) T ( n ) = Θ ( n l o g 2 7 ) = Θ ( n 2.81 ) A [ 1.. n ]
A [ i ] > A [ j ] A[i] > A[j] A [ i ] > A [ j ] ( A [ i ] , A [ j ] ) (A[i], A[j]) ( A [ i ] , A [ j ])
设计一个基于分治的算法
分析算法的时间复杂度
实现算法的关键步骤
22
)
S 8 = B 21 + B 22 S 9 = A 11 − A 21 S 10 = B 11 + B 12 \begin{align}
S_1 &= B_{12} - B_{22} \\
S_2 &= A_{11} + A_{12} \\
S_3 &= A_{21} + A_{22} \\
S_4 &= B_{21} - B_{11} \\
S_5 &= A_{11} + A_{22} \\
S_6 &= B_{11} + B_{22} \\
S_7 &= A_{12} - A_{22} \\
S_8 &= B_{21} + B_{22} \\
S_9 &= A_{11} - A_{21} \\
S_{10} &= B_{11} + B_{12}
\end{align} S 1 S 2 S 3 S 4 S 5 S 6 S 7 S 8 S 9 S 10 = B 12 − B 22 = A 11 + A 12
5 ⋅ S 6 = ( A 11 + A 22 ) ( B 11 + B 22 ) P 6 = S 7 ⋅ S 8 = ( A 12 − A 22 ) ( B 21 + B 22 ) P 7 = S 9 ⋅ S 10 = ( A 11 − A 21 ) ( B 11 + B 12 ) \begin{align}
P_1 &= A_{11} \cdot S_1 = A_{11}(B_{12} - B_{22}) \\
P_2 &= S_2 \cdot B_{22} = (A_{11} + A_{12})B_{22} \\
P_3 &= S_3 \cdot B_{11} = (A_{21} + A_{22})B_{11} \\
P_4 &= A_{22} \cdot S_4 = A_{22}(B_{21} - B_{11}) \\
P_5 &= S_5 \cdot S_6 = (A_{11} + A_{22})(B_{11} + B_{22}) \\
P_6 &= S_7 \cdot S_8 = (A_{12} - A_{22})(B_{21} + B_{22}) \\
P_7 &= S_9 \cdot S_{10} = (A_{11} - A_{21})(B_{11} + B_{12})
\end{align} P 1 P 2 P 3 P 4 P 5 P 6 P 7 = A 11 ⋅ S 1 = A 11 ( B 12 −
= P 5 + P 4 − P 2 + P 6 = P 1 + P 2 = P 3 + P 4 = P 5 + P 1 − P 3 − P 7
)
i
)
= A 21 + A 22
= B 21 − B 11
= A 11 + A 22
= B 11 + B 22
= A 12 − A 22
= B 21 + B 22
= A 11 − A 21
= B 11 + B 12
B
22
)
= S 2 ⋅ B 22 = ( A 11 + A 12 ) B 22
= S 3 ⋅ B 11 = ( A 21 + A 22 ) B 11
= A 22 ⋅ S 4 = A 22 ( B 21 − B 11 )
= S 5 ⋅ S 6 = ( A 11 + A 22 ) ( B 11 + B 22 )
= S 7 ⋅ S 8 = ( A 12 − A 22 ) ( B 21 + B 22 )
= S 9 ⋅ S 10 = ( A 11 − A 21 ) ( B 11 + B 12 )